登录


基本概括
功能
商家功能 商家提供的产品功能信息对比
共有功能
暂无共有功能
差异功能
扩展
扩展
可编程性
可编程性
聚类
聚类
内存中数据结构
内存中数据结构
高可用性
高可用性
展开
定价
免费试用
不支持
不支持
定制
不支持
不支持
价格套餐
-
获取独家报价
-
获取独家报价
客户规模
小型企业
(50人及以下)
-
77%
中型企业
(51-1000人)
-
16%
大型企业
(1000人以上)
-
7%
评分
综合评分
暂无评分

3.4
分


易用性
暂无评分
4.0
分
稳定性
暂无评分
暂无评分
售后服务
暂无评分
4.1
分
点评


将此报告发送至我的邮箱
发至邮箱
问答
热门问答

产品截图
截图对比
1/3
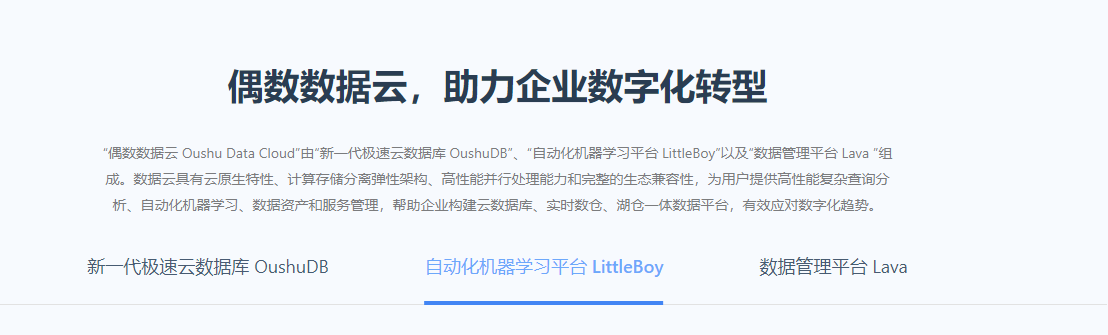
1/3
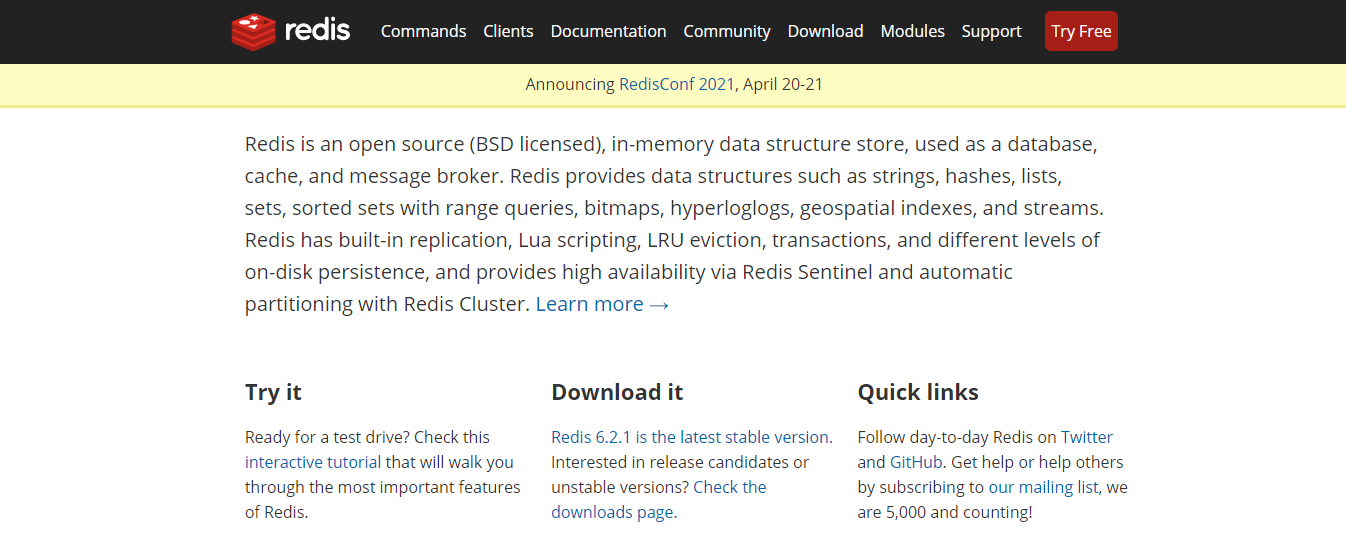





消息通知
咨询入驻

商务合作
