还未添加对比产品
登录

暂无评分
咨询产品
免费试用
基础信息
产品介绍
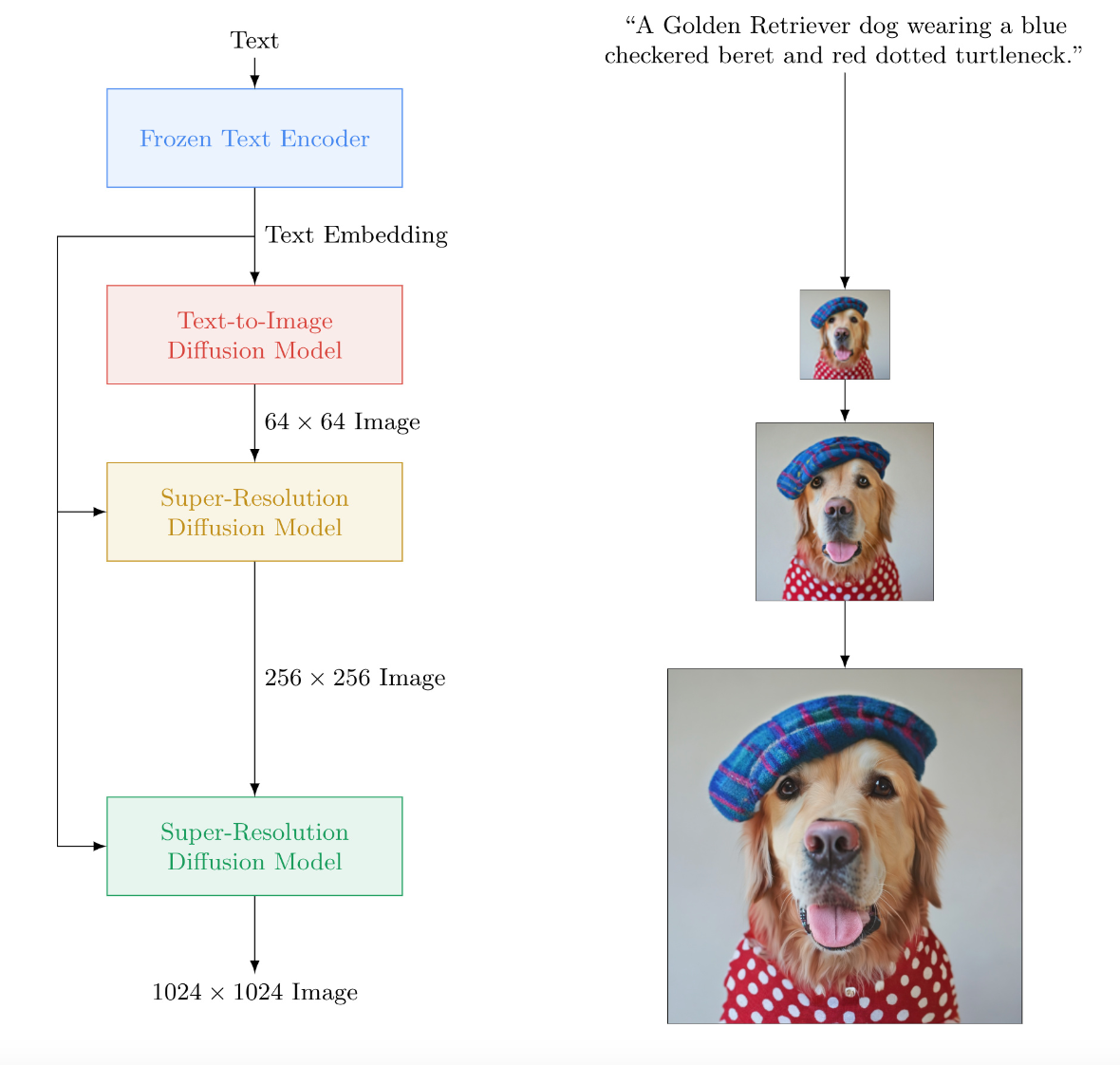
一种文本到图像的扩散模型
Imagen,这是一种文本到图像的扩散模型,具有前所未有的真实感和深度的语言理解。Imagen 建立在大型 Transformer 语言模型在理解文本方面的强大功能之上,并依赖于扩散模型在高保真图像生成方面的优势。
我们的关键发现是,在纯文本语料库上预训练的通用大型语言模型(例如 T5)在为图像合成编码文本方面非常有效:增加 Imagen 中语言模型的大小可以大大提高样本保真度和图像-文本对齐不仅仅是增加图像扩散模型的大小。
Imagen 在 COCO 数据集上获得了 7.27 的新的最先进的 FID 分数,而无需在 COCO 上进行训练,并且人类评估者发现 Imagen 样本在图像-文本对齐方面与 COCO 数据本身相当。为了更深入地评估文本到图像模型,我们引入了 DrawBench,这是一个用于文本到图像模型的全面且具有挑战性的基准。
使用 DrawBench,我们将 Imagen 与最近的方法(包括 VQ-GAN+CLIP、潜在扩散模型和 DALL-E 2)进行比较,发现人类评分者在并排比较中更喜欢 Imagen,无论是在样本质量方面和图文对齐。
收起
公司名称
Google
员工人数
- -
融资轮次
未融资
产品图片


售前咨询,预约演示,了解详细使用场景
立即咨询
问答
提问
暂时没有回答
如果你对产品有疑问,开始 写第一个提问
产品对比
消息通知
咨询入驻

商务合作

点评