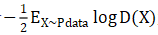gan的基本结构

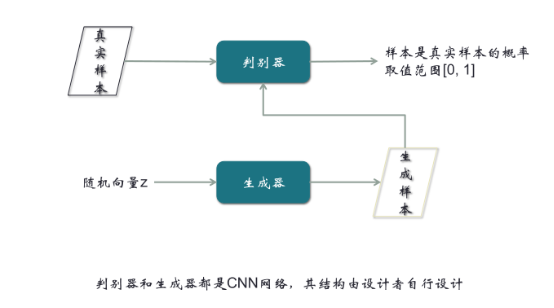
【第一步:用真实样本训练判别器,令它判别出1】
大家思考一下,如果我们不考虑第二步和第三步,只考虑第一步,实际上这个结构是有很大问题的。因为不管输入的样本是什么,想让它输出是1,这样单种类的分类,没有任何意义。一般意义上的分类器,起码分两类。如果不管判别器的输入层、隐藏层、中间层是什么样,只要最后一层保证输出是标量1,这个很容易做到。所以这个模型,只在我们接下来的所有步骤中有意义,单独看没有意义,这个大家要能看出来。

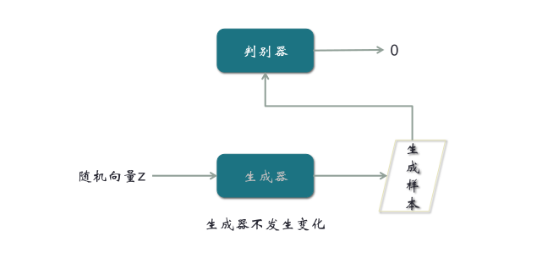
【第二步,由随机向量经过生成器,输出生成样本,然后把生成样本输入到判别器,令它能输出0】
与第一步联系,就会有两个分类,一个是1,一个是0。有了两个分类,判别器就可以得到优化。这是我们设计这个网络模型的结构时一定要注意的地方。在第二步,我们期望结果是0,但可能不是,就会产生误差,从而产生梯度,产生梯度后我们沿着箭头的反方向走,这就是反向传播。在反向传播过程中,可以把遇到的任何一个参数进行优化。优化过程中,有一个小技巧,在生成器的地方,把梯度截断,不优化生成器。因为对生成器优化,最终的结果不过是输出一个0,这不是生成器的目标。生成器的目标是生成一个很像真实样本的假样本。所以需要在这里截断梯度。第二步所进行的优化,是对判别器进行的优化。结合第一步,两步可以合成一步。
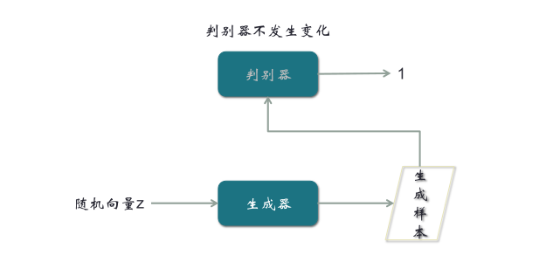
【第三步,输入随机向量,经过生成器输出生成样本,再经过判别器,输出判别系数,这时我们期望输出是1】
前面输出0,我们希望用梯度优化判别器,现在用一个不同的期望输出,来优化生成器。梯度在跑的过程中,虽然的确先经过判别器,但是因为判别器前面只对输出样本,期望输出是0,现在期望输出是1,所以梯度会路过判别器,只对生成器进行优化。所以最优化的结果,就是判别器对真实样本总是汇报1,对生成的假样本总是汇报0,同时我们生成器输出的生成样本,总是能通过判别器的判别。
但是这里有一个矛盾的地方,生成样本经过判别器,如果判别结果是1,会被当成真实样本,这意味判别器的判别是错误的;如果判别结果趋近于0,说明判别器的判别是正确的,但是这又意味着生成器生成的结果是不理想的。这个矛盾的对抗结果,使得整个GAN的训练非常麻烦。
二、GAN的损失函数
对判别器的训练: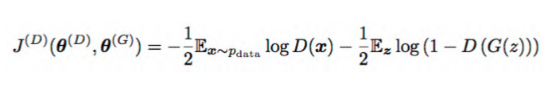
data指真实样本,D指判别器,G指生成器。我们期望D(X)趋近于1,整个![]() 趋近于0。D(G(z))是生成器对输入向量Z生成的样本,作为判别器的输入,我们期望这部分的输入趋近于0。
趋近于0。D(G(z))是生成器对输入向量Z生成的样本,作为判别器的输入,我们期望这部分的输入趋近于0。
对生成器的训练:
这里D(G(z))与上面相反,我们期望输出结果是1。
(本文来源于:Boolan首席AI咨询师—方林老师)
[免责声明]
文章标题: gan的基本结构
文章内容为网站编辑整理发布,仅供学习与参考,不代表本网站赞同其观点和对其真实性负责。如涉及作品内容、版权和其它问题,请及时沟通。发送邮件至36dianping@36kr.com,我们会在3个工作日内处理。