用100元的支票骗到100万:看看对抗性攻击是怎么为非作歹的
作者:Roman Trusov,编译:元元、桑桑、徐凌霄、钱天培、高宁、余志文
Google brain最近的研究表明,任何机器学习的分类器都可以被误导,然后给出错误的预测。甚至,只需要利用一些小技巧,你就可以让分类器输出几乎任何你想要的结果。
机器学习可能会被“误导”的这一现象,正变得越发令人担忧。考虑到越来越多的系统正在使用AI技术,而且很多系统对保障我们舒适而安全的生活至关重要,比如说,银行、监控系统、自动取款机(ATM)、笔记本电脑上的人脸识别系统,以及研发中的自动驾驶汽车。关于人工智能的安全问题,近期的关注点主要围绕道德层面,今天我们将讨论一些更紧迫更现实的问题。
什么是对抗性攻击(Adversarial Attacks)
机器学习算法的输入形式为数值型向量(numeric vectors)。通过设计一种特别的输入以使模型输出错误的结果,这便被称为对抗性攻击。
这怎么可能呢?没有一种机器学习算法是完美的,正如人类会犯错误一样,机器智能自然也会出错——虽然这很罕见。然而,机器学习模型由一系列特定的变换组成的,大多数变换对输入的轻微变化都非常敏感。利用这种敏感性可以改变算法的运行结果,这是人工智能安全安全的一个重要问题。
本文中,我们将展示攻击的几种主要类型及实例,解释攻击易于实施的原因,并讨论这个技术所引起的安全隐患。
对抗性攻击的类型
下面是我们将要重点分析的主要攻击类型:
1.无目标的对抗性攻击: 这是最普遍的攻击类型,其目标是使分类器输出错误的结果
2.有目标的对抗性攻击: 这种攻击稍微困难一些,其目标是使分类器针对你的输入输出一个特定的类。
我们来看看针对Google Inception V3 ImageNet分类器的非目标性对抗攻击是如何完成的:
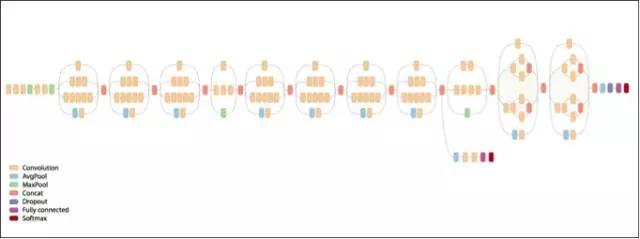
图片注释:Inception v3 构架,来自于Google
一个经训练的神经网络本质上代表一个高维的决策边界。我们可以把决策边界想象为一组单元格,同一个单元格中的每一个点(在这个例子中是指每一张图片)都属于同一个类别。当然,边界不是完美的,甚至可以说,这些“单元格”的分类过于粗糙且为线性。这就是该模型的主要漏洞。
理想情况下,一个好的对抗性攻击是,提供一个与原始图片数据视觉上无法区分的输入,却让分类器输出完全不同的预测结果。该攻击的主要思想是为每一类图片找到一组能够把表示向量从原单元格“拖向”另一个单元格轻微的扰动。。本文中,我们将原始图片称为“源”(source),把我们加入的扰动称为“噪声”(noise)。虽然这并不是一个真正的噪声,但我们会看到,它其实包含着多重复杂的结构。
所以,现在我们需要知道的只是一个移动方向,使其从初始点(source)移动到临近的其他单元格, 或者在目标性攻击的情况下,移至目标类的某个特定单元格。
逐步分析
最简单但也最有效的方法是快速梯度逐步算法(Fast Gradient Step Method ,FGSM)。这个方法的核心思想是在每一步优化的过程中加入少量噪声,让预测结果朝目标类别偏移, 或者如你所愿远离正确的类别。有时候我们需要限制噪声的振幅以使得攻击更加隐蔽, 比如说防止某人调查我们的诡计。在我们的例子中,噪声的振幅意味着像素通道的强度——限制振幅可以确保噪声几乎无法察觉,而在最极端的情况下,图片看起来也只是像一个过度压缩的jpeg文件.
这是一个纯粹的最优化问题——但是在这个例子中,我们优化噪声的强度来使错误最大化。在这个案例中,因为你可以获取神经网络的原始输出信息, 所以你可以直接测量误差以及计算梯度。
你一定会说, 很不错, 但是如果我们没有完整的原始输出信息怎么办, ——比如只有一个分类结果? 如果我们不知道模型的架构怎么办?
好,让我们假设一个最现实的例子。如果我们要攻击一个完全的“黑箱”, 即接受一张图片作为输入,然后输出该图片的类别。仅此而已。你该怎么办呢?
你可以从相同的方向入手. 首先你需要生成噪音并加到图片上, 然后将图片输入分类器, 并不断重复这个过程直到机器出错。不管你是否限制噪声强度的大小,重复到某个时刻,你都不会再看到正确的分类结果。此时你需要做的事就是找到能得到相同错误结果的最弱噪声,用一个简单的二分搜索就可以做到.
让我们来看看为什么这个方法可行。我们来考虑图片空间中的不同横截面,如果你开始向某个方向移动, 你会停在哪儿呢?根据FGSM的定义(沿梯度方向逐步移动),FGSM会使你移动到真实类别和某个错误类别的边界上, 如下图所示:
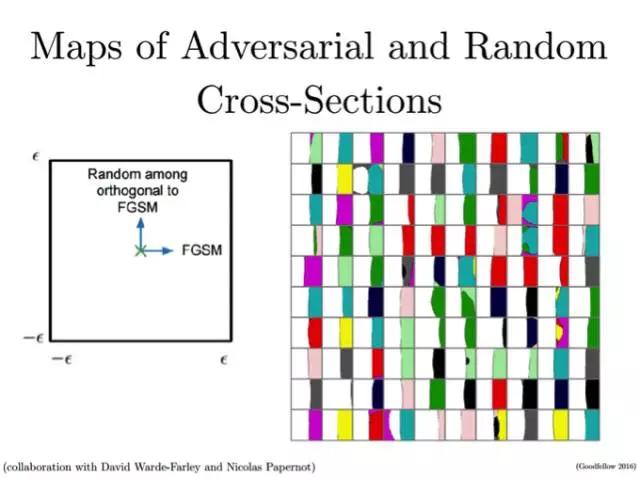
图片标题:对抗方向和随机方向的横截面图集
横坐标:快速梯度方向(对抗方向)
纵坐标:垂直梯度方向的随机值(随机方向)
与David Warde-Farley和Nicolas Papernot合作完成图片
“真”和“假”之间的边界几乎是线性的。我们可以从中得到两个有趣的结论。首先,如果你沿着梯度的方向进行计算, 一旦碰到了预测的类别改变的区域, 就可以确认攻击成功了。另一方面,它表明了,决策函数的结构远比大多数研究者想象的容易。
这个方法很简单而高效。如果没有防护措施,这个方法几乎可以“玩弄”所有的机器学习算法。
让我们来执行一个无目标性攻击

在本实验中,我们将使用PyTorch和torchvision包中的预训练分类器Inception_v3模型。
让我们逐步分解攻击的思路。首先,我们需要选择一组图像,将它转化为对抗样本。为了简单方便起见,我将使用NIPS 2017对抗攻击挑战赛中的数据集(development set)。
你可以在这里下载所有的脚本:
https://github.com/tensorflow/cleverhans/tree/master/examples/nips17_adversarial_competition/dataset
mport torch
from torch import nn
from torch.autograd import Variable
from torch.autograd.gradcheck import zero_gradients
import torchvision.transforms as T
from torchvision.models.inception import inception_v3
from PIL import Image
import matplotlib.pyplot as plt
import numpy as np
定义主要的设置,并初始化神经网络:
classes = eval(open('classes.txt').read())
trans = T.Compose([T.ToTensor(), T.Lambda(lambda t: t.unsqueeze(0))])
reverse_trans = lambda x: np.asarray(T.ToPILImage()(x))
在这里,我们需要一个可以将PIL(Python Imaging Library)图片转换为Torch张量的转化,同时我们还需要一个可以输出numpy矩阵的反向转换,让我们可以将其重新转化为一张图片。
eps = 2 * 8 / 225.
steps = 40
norm = float('inf')
step_alpha = 0.0001
model = inception_v3(pretrained=True, transform_input=True).cuda()
loss = nn.CrossEntropyLoss()
model.eval();
这是一个可以拿来就用的预训练神经网络。这篇教程中的所有操作都是在GPU上运行的,如果你不想使用GPU,只需要将代码中所有的“.cuda()”调用和“.cpu()”调用删除即可。
我们也定义了一个损失函数,之后会在此基础上进行梯度下降。关于“step_alpha”参数,我们稍后会进行进一步讨论。
为了使攻击更加细微,我们需要为所增加的噪音施加约束。一个很好的方法是将噪声的L-无限范数(即绝对值)限制在一定值,通过这种方法,图像就不会显得过亮或过暗。这种方法也很容易理解——像素点数值的绝对值正代表了图片在某一RBG通道的亮度。
在编写攻击代码之前,让我们先添加这个可以进行可视化的函数:
def load_image(img_path):
img = trans(Image.open(img_path).convert('RGB'))
return img
首先,我们从磁盘读取图像,并将其转换为网络能接受的格式。
def get_class(img):
x = Variable(img, volatile=True).cuda()
cls = model(x).data.max(1)[1].cpu().numpy()[0]
return classes[cls]
默认情况下,分类器只给我们一个类的数字id——该方法既能完成统计推断,也能给出最可能的分类结果。
def draw_result(img, noise, adv_img):
fig, ax = plt.subplots(1, 3, figsize=(15, 10))
orig_class, attack_class = get_class(img), get_class(adv_img)
ax[0].imshow(reverse_trans(img[0]))
ax[0].set_title('Original image: {}'.format(orig_class.split(',')[0]))
ax[1].imshow(noise[0].cpu().numpy().transpose(1, 2, 0))
ax[1].set_title('Attacking noise')
ax[2].imshow(reverse_trans(adv_img[0]))
ax[2].set_title('Adversarial example: {}'.format(attack_class))
for i in range(3):
ax[i].set_axis_off()
plt.tight_layout()
plt.show()
我们的FGSM攻击将取决于三个参数:
1.最大强度(这不应超过16)
2.梯度步数
3.步长
一系列试验后,我们将梯度步数确定在了10-20,将步长定为0.001。通常我们不会把步长设置的太大,以避免结果不稳定。这一步骤和普通梯度下降是一样的。
def non_targeted_attack(img):
img = img.cuda()
label = torch.zeros(1, 1).cuda()
x, y = Variable(img, requires_grad=True), Variable(label)
for step in range(steps):
zero_gradients(x)
out = model(x)
y.data = out.data.max(1)[1]
_loss = loss(out, y)
_loss.backward()
normed_grad = step_alpha * torch.sign(x.grad.data)
step_adv = x.data + normed_grad
adv = step_adv - img
adv = torch.clamp(adv, -eps, eps)
result = img + adv
result = torch.clamp(result, 0.0, 1.0)
x.data = result
return result.cpu(), adv.cpu()
通过这样的修改,我们让分类器越错越离谱。我们可以完全控制该流程在两个“维度”中的细化程度:
1.我们用参数eps控制噪声的幅度:参数越小,输出图片的变动也就越小
2.我们通过参数step_alpha来控制攻击的稳定性:和在神经网络的普通训练过程中类似,如果把它设置得太高,我们很可能会找不到损失函数的极值点。
如果我们不限制攻击的幅度,结果则可能类似于目标类中的平均图像,权衡之后将如下所示:

在我所有的实验中,使用最小的eps也能带来不错的结果——很小的改动就能让分类器懵逼。为了更清楚地演示,在下面的示范中我将噪音调大了。
让我们来运行一下“攻击”,看看我们将得到什么:
img = load_image('input.png')
adv_img, noise = non_targeted_attack(img)
draw_result(img, noise, adv_img)
好,所以如果我们想要我们的神经网络输出某个特定的类别怎么办?这只需要对攻击代码做一些小调整就可以了:
def targeted_attack(img, label):
img = img.cuda()
label = torch.Tensor([label]).long().cuda()
x, y = Variable(img, requires_grad=True),
Variable(label)
for step in range(steps):
zero_gradients(x)
out = model(x)
_loss = loss(out, y)
_loss.backward()
normed_grad = step_alpha * torch.sign(x.grad.data)
step_adv = x.data - normed_grad
adv = step_adv - img
adv = torch.clamp(adv, -eps, eps)
result = img + adv
result = torch.clamp(result, 0.0, 1.0)
x.data = result
return result.cpu(), adv.cpu()
这里最主要的改变是梯度符号的改变。在无目标性攻击的过程中,假设目标模型几乎总是正确的,我们的目标是增大偏差。与无目标攻击不同,我们现在的目标是使偏差最小化。
step_adv = x.data - normed_grad
让我们来尝试一些有趣的例子,试试针对Google的FaceNet进行对抗攻击。
本例中,FaceNet是一个拥有密集层(dense layer)的Inception_v3特征提取器,可以识别图片中的人最可能是谁。我们采用户外脸部检测数据集(Labeled Faces in the Wild,LFW)来进行测试,这是面部识别的一个基准。Inception_v3的扩展网络与另一个分类器结合一起,使用LFW数据集的500张最常见的人脸进行训练。

图片解释:LFW 数据库范例
攻击的目标是使数据集中每一个人都被分到“Keanu Reeves”这一类
因为我们有很多张图片,我们可以选择性地在代码中加入一个攻击成功就停止运行的条件。在对数损失小于0.001时就停止攻击是很合理的;实践中,该停止攻击方法可以显著提高运行速度,如下图所示:
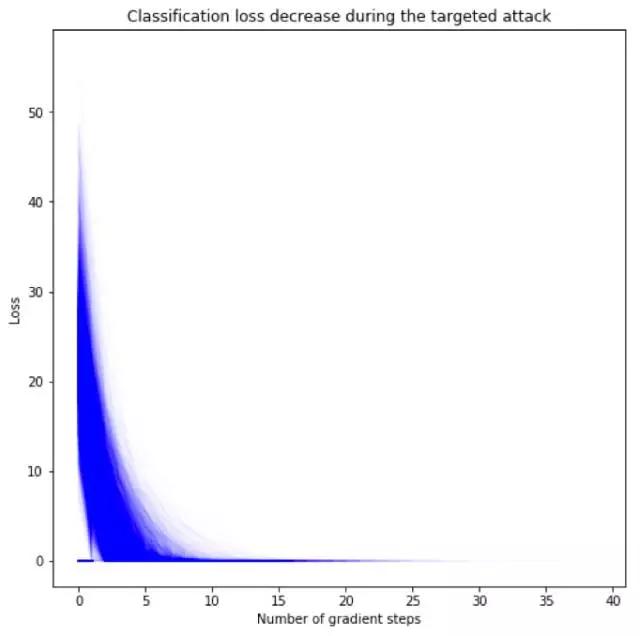
图片标题:目标性攻击过程中,分类损失函数值逐渐减小
横坐标:梯度下降步数
纵坐标:损失
图中有一个很长的平稳期,这意味着大多数时候你可以省很多计算时间。
在我们深入研究之前:仅仅根据收敛所需要的步数,我们可以对该网络的决策函数做些什么推断呢?决策函数的维度太高以至于难以高效检验么? 既然最优化问题这么容易解决,我们推断边界是个很简单的函数,很可能是线性函数。
这告诉我们什么呢?第一,神经网络中的类相距很近。第二,不太明显的是,如果你仅仅输入一些随机噪声,分类器仍会输出一些预测结果,这并不总是一件好事。这个在图像理解领域还是未解决的问题,最近用对抗性训练解决了这个问题。
一个成功的目标性攻击需要多少步?
如下图所示:
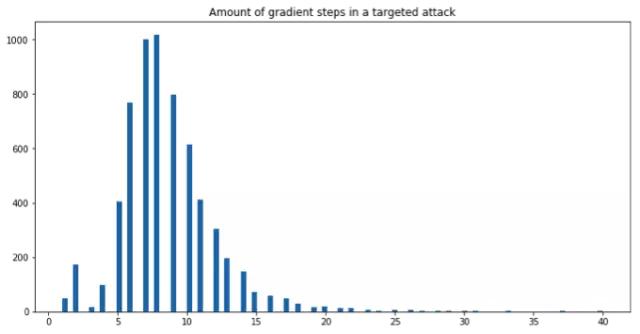
图片标题:目标性攻击的梯度下降步数
有目标攻击的结果就没有那么有趣了——振幅降低的噪声使得原图和修改后的图片用肉眼无法分辨。

图片标题:从左到右:Sylvester Stallone, 对抗噪声,Keanu Reeves
接下来,让我们一起来看看几个对抗性攻击的实际案例。(请勿模仿哦!)
打印一个“布满躁点”的写着$100的ATM支票-而用它取现$1000000.
把一个路标换成一个稍微有干扰性的,将限速设为200——这在自动驾驶的世界中是相当危险的。
不要再等自动驾驶汽车了——重新画你的车辆牌照,摄像头永远不会认出你的车。
安全性和性能的担忧
现在我们已经知道如何成功执行一个攻击,那么让我们来问问自己为什么它们这么危险。是的,每个人都可以使用FGSM,但有没有防御措施呢?
这里我提两个防御策略:
被动型策略:训练其他的分类器来检测对抗输入并抵制他们。
主动型策略:实行对抗训练程序。
主动型策略不仅可以帮助防止过度拟合,让分类器的鲁棒性变强,还可以让你的模型加速收敛。但是根据最近的研究结果,这也不能消除所有对抗攻击带来的问题。
而且,增加一个分类器也会大大降低分类效率,实现这两个分类器也要求你具备更多GANs的经验。
有些人说既然GANs中的鉴别器能够被训练用来侦测对抗的案例(在不消除攻击本身的情况下),攻击的问题能够通过抵制这种被破坏的样本来解决。不论是从商业还是从科学角度来讲,这种解决方案都不是最优的。除了没有人愿意承担误报(false positive)的风险这一因素,还有一个和机器学习本身同样古老的论点:“人类能做的都可以教给一个机器做”。人类可以无障碍地正确解释对抗案例,所以一定有方法让这件事自动化。
最后,迁移学习也非常适合被应用到这种攻击中。即使攻击者没办法接触原模型, 针对一个足够好的分类器所生成的样例也能够骗过很多其他作用相同的模型。
研究方向
最后,我想提几个针对对抗性攻击未来研究的几个研究方向。解决其中的一个或许就能让你扬名立万哦。
我们如何在分类器上实行对抗训练呢?如果我们可以训练出一个不仅能预测标签,还能辨别你是不是在骗他的网络,那可就太棒了。
对于大多数的类别来讲,决策边界到底长什么样子呢?我们知道他们是几乎线性的。但到什么程度呢?类群边界的确切形式(或者换一个准确高端的术语“拓扑”)可以让我们深入了解最有效的攻击/防御。
我们可以如何检测出对抗案例的出现呢?当你看到一个受损的图片时,比如一只大象的图,你很可能通过图上的彩色噪点识别出来。但对于机器来说,它非常确信这就是一架飞机,而不是一张有噪点的大象图。
论文资源
Explaining and Harnessing Adversarial Examples:
解释并治理对抗案例:
https://research.google.com/pubs/pub43405.html
The Space of Transferable Adversarial Examples:
对抗案例的迁移空间:
https://research.google.com/pubs/pub46153.html
Adversarial Autoencoders:
对抗自编码:
https://research.google.com /pubs/pub44904.html
Adversarial examples in the physical world:
现实世界中国的对抗案例:
https://research.google.com/pubs/pub45471.html
Tutorials
教程:
Tutorial by Ian Goodfellow:
Ian Goodfellow的教程:
http://www.iro.umontreal.ca /~memisevr/dlss2015/goodfellow_adv.pdf
Lecture from Stanford course:
斯坦福课程:
https://www.youtube.com /watch?v=CIfsB_EYsVI
OpenAI tutorial:
OpenAI的教程
https://blog.openai.com/adversarial-example- research/
Repositories and tools
资料库和工具:
Cleverhans is a great TensorFlow-based library for adversarial attacks and defences:
Cleverhans是一个很好的基于TensorFlow的对抗攻击和防御的文库
https://github.com/tensoreow/cleverhans
FoolBox — another collection of attacks that you can use with a framework of your preference
FoolBox——另一个你可以结合你喜欢的的框架运用攻击的集合:
https://foolbox.readthedocs.io /en/latest/
Competitions
比赛
Non-targeted attacks:
无目标攻击:
https://www.kaggle.com/c/nips-2017-non- targeted-adversarial-attack
Targeted attacks:
目标攻击:
https://www.kaggle.com/c/nips-2017-targeted- adversarial-attack
Defences:
防御:
https://www.kaggle.com/c/nips-2017-defense-against- adversarial-attack




大厂都在用的在线作图软件
包图网
- 4.2
(241)咨询产品免费试用稿定设计
- 4.0
(193)咨询产品免费试用fotor懒设计
- 4.1
(49)咨询产品免费试用



限时免费的在线作图软件
千图网
- 4.1
(293)咨询产品免费试用创客贴
- 3.9
(243)咨询产品免费试用摄图网
- 4.2
(86)咨询产品免费试用



新锐产品推荐
装企帮
- 0.0
(0)咨询产品免费试用Deskera CRM
- 4.0
(41)咨询产品免费试用CaptivateIQ
- 4.2
(40)咨询产品免费试用Varicent
- 4.0
(40)咨询产品免费试用SmartWinnr
- 4.7
(40)咨询产品免费试用活动行-线下签到服务
- 0.0
(0)咨询产品免费试用







