Facebook、YouTube都会遇到的内容审核难题,今日头条是怎么解决的?
编者按:本文来自微信公众号“一个胖子的世界”(ID:we_the_people),作者:柳胖胖,36氪经授权发布。
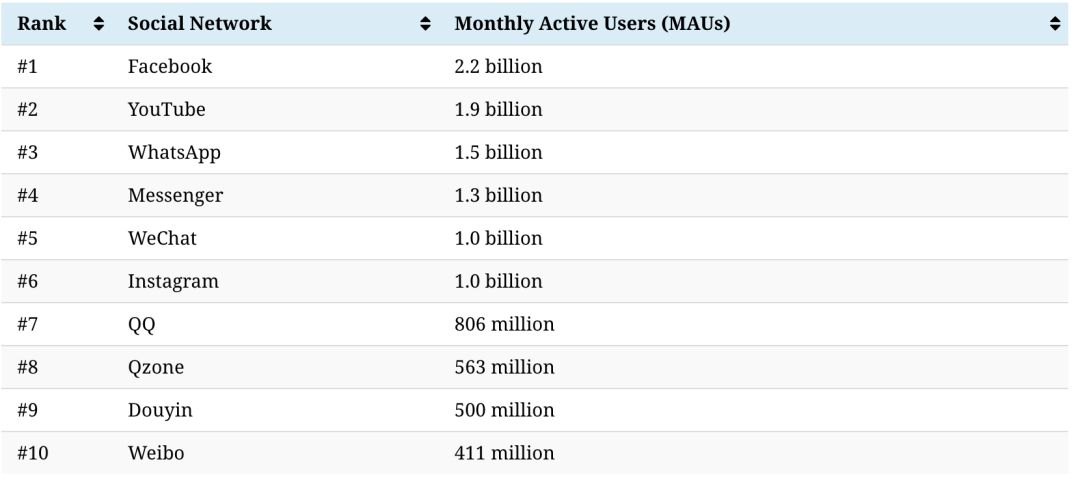
2018年Facebook 上每天上传的照片超过3亿张,每分钟发布51万条评论,30万条新状态;每天在Instagram上的照片和视频分享量为9500万次;而在微信朋友圈,每天有10亿张图片被上传。截止 2018 年,每天约有2.5万亿字节的数据被创建,过去两年里生成的数据占到了全球总数据的90%,而预计到 2022年,全球互联网流量讲达到每秒 7.2 PB。
包括Facebook和Youtube在内的国际顶级UGC平台,如今在这类老生常谈的问题上依然十分吃力,尤其是发达国家最为在意的低龄内容、种族歧视和跨国文化/多语言等问题,它俩其实一直未能交出一份让各方满意的答卷。
而国内今年比较知名的互联网内容社区类产品里,下架甚至关停的已经不下10余款,尽管它们各自都有各自的问题,比如色情内容、微商、内容涉政等等,但归根结底,这还是用户激增带来的日益增长的内容生产量和无法跟上的审核措施和效率之间的矛盾。
一、Facebook:用AI和算力应对海量内容
而这些内容并不只在Facebook app发布和消费,还在这家公司旗下月活15亿的Whatsapp 、13亿的Facebook Messenger和10亿的Instagram上面传播和推广,所以这家公司承受的内容审核压力才会如此之大。
那么Facebook拿出的应对措施是什么?
小扎自称,Facebook上99%有关ISIS和基地组织的内容,都在人们看到之前被人工智能系统标记,并且被删掉。
文字审核方面,Facebook推出了DeepText(深度文本)引擎,利用深层神经网络架构去理解那些帖子的内容,据称它能够以近乎人类的精确度、每秒同时理解数千篇文章的文本内容。相比国内的各大平台的审核体系来说,它的优势除了速度更快,另一方面是Facebook作为一个全球化的社区,DeepText能够审核超过20多种语言的文字。
DeepText甚至能实时通过用户发送的内容分析用户的想法,通过对意图、情绪和实体(人物/地点/事件)的提取,结合文本、图片,并自动移除垃圾信息的干扰,这一能力在Facebook Messenger上已经被测试验证。当然这个AI技术也并不只被用来审核一些可能发生的危险(针对青少年的犯罪),它还可以改进用户体验,帮助广告商进行有目标的宣传活动。
Facebook为这些实时而海量的信息编目录、并让其被搜索是件很困难的事情,所以他们才转向了人工智能。
同时,News Feed做为短小而高频的内容素材,恰好就是众多开展深度学习活动的有效场所之一,因为每个Feed的背后,包含了人们希望看到哪些与他们相关的内容。
而Facebook的图片和视频审核系统名为Rosetta,利用光学字符识别系统来处理图片和视频内容,每天可以实时地从超过10亿张图像和视频帧中提取信息并识别多种语言背后的含义。
另外,Facebook在上周刚刚开源了它们在图像识别及视觉领域的最新模型: ResNext101。 这是一个在Instagram的图片标签上预训练,并在ImageNet上微调的模型。
在这两大系统的背后,其实是Facebook的人工智能研究院FAIR(Facebook Artificial Intelligence Research)在发挥功劳。比如其物体识别技术(Object recognition),以含有数十亿参数和数百万案例训练的神经网络为基础,给了挑战最大的图片和视频审核有力的支持。另外它们也使用自我监督学习(SSL)探索大量数据,让机器可以通过分析未标记的图像、视频或音频来学习世界的抽象表达,这也是 FAIR 将 AI 能力规模化的努力之一。
FAIR 还在研究用户头像的面部识别、上传照片的环境识别等,它承担 Facebook 所有 AI 相关的基础研究、应用研究和技术开发。 比如它推出的刚刚获得了国际视觉模型挑战赛冠军的Mask R-CNN ,这个系统可以将计算机视觉世界的物体检测与语义分割结合到了一起,不但可以检测劣质视频内容,甚至可以帮助视障人士自动替代文字。
不过,你可千万别以为世界上最大的社交网络和内容平台,光靠AI和审核系统就搞定了一切。 截止目前,Facebook聘请了超过2万人(是的你没看错),来辅助内容筛查,并配合监测和删除争议内容。
二、YouTube:版权审核系统的升级之路
YouTube的内容审核系统名为Content ID,会监测并直接删除涉及色情、低俗和暴力等违规内容。不过,这个系统的诞生一开始仅仅是为了解决YouTube上内容的版权问题。
早年间YouTube以草根内容起家,后来出现了大量的搬运号,主要以盗版电视台的精品内容为主。虽然平台的数据因此飙涨,但也因此陷入了旷日持久的官司里。
2007 年至 2009 年,包括维亚康姆(美国第三大传媒公司),Mediaset (意大利的传媒集团)和英超联赛(英国最大足球联赛)等在内的组织对 YouTube 提起诉讼,声称它在用户上传侵权内容方面毫无作为。
维亚康姆要求其作出10 亿美元赔偿金,他们声称已经在 YouTube上 发现超过 15 万条版权内容片段,累计播放量超过 15 亿次。在耗时耗力的多年诉讼和公关战之后,直到2014 年,双方才最终协商解决了争议,但具体条件并未公开。
所以当年在被Google收购之后,YouTube从2007年开始就逐步投入巨资建立起Content ID版权系统,慢慢帮助版权所有者能够识别平台上的侵权行为,并让版权所有者在平台上能够获直接获得收入。截止 2018 年,谷歌为该技术研发共计投入超 1 亿美元。
后来,Content ID的内容监测能力在不断改进后,比如使用哈希算法标记有风险视频,阻⽌它们被⼆次上传,也获得了显著的成效。以2017年Q4为例,平台删除了800万条“令人反感”的视频,有670万条都由监测软件自动标记。大约75%被标记的视频,在被用户观看之前就被下架。
人性化的是,YouTube 于 2014 年 9 ⽉在前端增加了受限模式(Restricted Mode),用以过滤⾊情暴⼒内容,但是⽤户可以自己选择开启还是关闭。依据⽤户举报以及其它识别规则,受限模式可以直接为用户过滤⼤部分不当内容。
当然,YouTube的这些内容审核能力有赖于谷歌的深度学习技术Google Brain作为支持。Google Brian拥有一个收集用户信息(如观看历史和用户反馈)的神经网络, 以及一个用于对所显示部分视频进行排列的神经网络,通过引入机器学习工具,自动标记暴力、色情和低俗等极端视频,并将违规内容报告给人工审核员进行验证。
和Facebook类似的是,就算有了Google多方面的技术支持(包括资金、人才、算法、云和服务器等),YouTube的AI标记、内容审核与识别技术也并不完美。2018的时候YouTube CEO苏珊·沃西基承诺,未来会雇佣至少一万名人工审核员,以补足算法的局限。
因为更早之前英国政府和一些广告公司发现,自己的广告被推荐到了紧挨着极端主义分子上传的视频内容的旁边,造成了许多恶劣的影响,多方政府和广告主们联名宣布将因此撤下自己在YouTube账号上的内容。
不过,Google对 YouTube 的帮助也不会仅仅限于内容审核,Google Brain的技术已经被应用在安卓系统的语音识别、Google+ 的图片搜索、以及 YouTube 的智能推荐。所以,现在的YouTube早已从一个视频UGC社区,到慢慢成为拥有海量内容、搜索驱动的视频综合网站,到拥有了视频推送能力的应用。如今,占据用户在 YouTube 上观看视频总时长 70%的内容 ,是由推荐算法引擎驱动的。
三、头条:审核系统对外开放会带来哪些变化?
如今的今日头条已经拥有海量的用户和多种形式的UGC内容,尽管体量上还颇有不如,但在内容审核方面遭遇的挑战同脸书和Youtube已经十分类似。
头条在这方面的一个创举是,经过多年的技术储备和经验积累后,它开放了内部反低俗系统的一个简化版本“灵犬反低俗助手”,希望普通创作者、社会公众更了解和关注反低俗。 截至2019年6月,灵犬反低俗助手的外部使用人次已经超过了300万。
用户只需要在灵犬的小程序内输入一段文字或文章链接,灵犬就可以帮助其检测内容健康指数,返回一个鉴定结果。 对于用户输入的内容(文字或者图片),“灵犬”会先进行提取、分词和语义识别,然后根据相关规则,输出对应的分数、评级和结论。
在文本识别领域,头条同时应用了“Bert”和半监督技术,训练数据集包含920万个样本,准确率提升至91%。 在图片识别领域,“灵犬”采用深度学习作为解决方案,在数据、模型、计算力等方面均做了针对性优化。 最近新版的灵犬3.0发布,重点拓展了反低俗识别类型和模型能力,现已覆盖图片识别和文本识别,后续,灵犬还将支持难度最大的语音识别和视频识别。
不过,今日头条的人工智能实验室王长虎也提到,AI暂时还是有缺陷的,今日头条现在有将近万余人的审核团队在辅助AI的审核。
比如对于低俗内容,它的定义本来就相对笼统难以精确,这项工作即使对人来说也不容易,交给机器做更难实现。
比如世界名画中常常出现裸体女子,如果完全交由机器判断,机器通过识别画中人物的皮肤裸露面积,就会认为这幅画是色情低俗的; 而某些拍摄芭蕾舞的图片,以机器的视角来看,其实类似于裙底偷拍。
Facebook 曾经因为“裸露”,误删了一张著名的越战新闻照片,内容是一位小女孩遭到汽油弹炸伤、浑身赤裸奔跑,事件发生后引起了美国新闻界的巨大争议。
四、结语
比如邓丽君的歌曲,早年被认为是低俗情色歌曲,如今早已被普遍接受并传唱大街小巷;比如内衣和内衣模特出现在购物平台上,会被默认为正常,但如果频繁出现在新闻资讯平台上,就可能被认为有低俗嫌疑;而正常的热舞内容,提供给成年人看,符合常规标准,但如果开启了青少年模式,这些内容就不应该出现。这就是由于时代背景、使用场景、用户人群不同而导致审核标准可能大幅变动的案例。

海量数据的产生、不断变化的标准,这都要求大公司在这方面的投入必须越来越多,而这本质上就成了一场资本丰厚的对手之间的军备竞赛。
今年卡耐基梅隆大学(CMU)和 Google 合作研发的 XLNet 模型,在Bert模型的基础上更进一步,在足足 512 块 TPU 上训练了两天半时间。 以 Google Cloud的计价标准,只是训练一次XLNet 模型就需要人民币一百六十多万。 若再考虑上整个模型研发过程中的不断试错和调参验证等过程,XLNet的开销简直天文数字。 未来中小团队将难以竞争,这就是一个巨头独霸的竞技场。
不过好在,随着人类进入社会的数字化程度越来越高,新一代的移动互联网原住民们在享受技术带来的便利的同时,也对技术可能的负面在耐受度和适应性上不断提高。



新锐产品推荐
小冰超级自然虚拟人
- 0.0
(0)咨询产品免费试用小冰智能座舱
- 0.0
(0)咨询产品免费试用邦永PM2项目管理软件
- 0.0
(0)咨询产品免费试用准星系统
- 5.0
(1)咨询产品免费试用iPeople
- 4.5
(1)咨询产品免费试用分众传媒
- 0.0
(0)咨询产品免费试用







