语义鸿沟、异构鸿沟、数据缺失,多模态技术如何跨过这些坎?
编者按:本文来自微信公众号“AI前线”(ID:ai-front),作者李岩,36氪经授权发布。
编辑|Debra
多模态技术帮助用户更好地表达与记录
在视频中,对音频部分的理解是视频信息传递的重要部分。快手上有很多以语言讲述为核心的视频,需要大量匹配的字幕辅助观看。视频字幕制作其实是一件工作量很大的事情,一般需要在电脑前使用专业的编辑软件手动逐个输入文字。而如果通过语音识别技术,把语音直接转成文字,就可以很轻松地通过手机编辑生成一个带字幕的视频。
对视频进行语音转写时,面临以下的技术难点:首先,拍摄视频时,麦克风和说话者之间的距离比较远,语音信号因为传输距离远产生衰减,同时麦克风对环境噪声的抑制能力也会减弱,造成语音信号弱,背景噪声强的现象;其次,在房间内拍摄时,可能因墙壁对语音信号的反射造成混响;第三,快手的用户包括了全国各个区域,自然地包括了多样的口音;最后,短视频的内容种类丰富,表达方式随意,有些视频还有很强的韵律起伏。这些因素都会影响语音识别系统的准确率。快手针对这些问题,研发了语音质量检测、单通道混响消除、噪声掩蔽建模等多种技术,以及通过序列化建模方法提升多种口音的识别准确率。
在视频配音方面,如果用户不喜欢男性配音,而希望实现女性配音的效果,就可以通过语音合成技术满足个性化的诉求。
语音识别及合成技术都会使记录的过程变得更加便捷、有趣,但这两项技术在做视觉或者多媒体的圈子里面关注度不是特别高,在语音圈子里面,语音识别、语音合成也往往是两波人在做。
随着深度学习技术的出现,语音识别和合成其实在某种程度上可以看做是非常对称的两个问题,因为语音识别是从语音到文字,语音合成是从文字到语音。语音识别,我们提取一些声学的特征,经过编码器或者 Attention 的机制,实现从语音到文字的转化;语音合成的技术和算法,其实也涉及编码器或者 Attention 的机制,二者形成了比较对称的网络。所以我们把语音识别和合成看成是一个模态转换的特例,从神经网络建模角度来看,是一个比较一致、容易解决的问题。快手的语音识别、语音合成技术原理图如下:
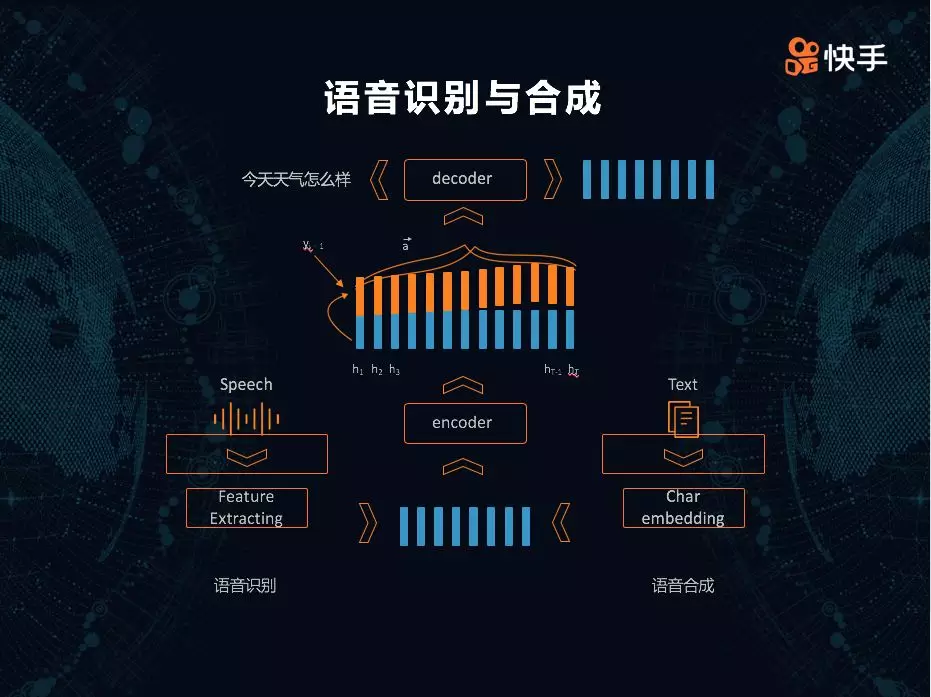
音乐也是短视频非常重要的一部分,为一个场景匹配合适的音乐并非易事。过去,有不少用户在拍摄时为了与音乐节拍一致,努力配合音乐节奏拍摄,极大限制了拍摄的自由度。快手希望用户可以随意按照自己的方式录制视频,对用户拍摄的视频内容进行理解后,自动生成符合视频内容的音乐。
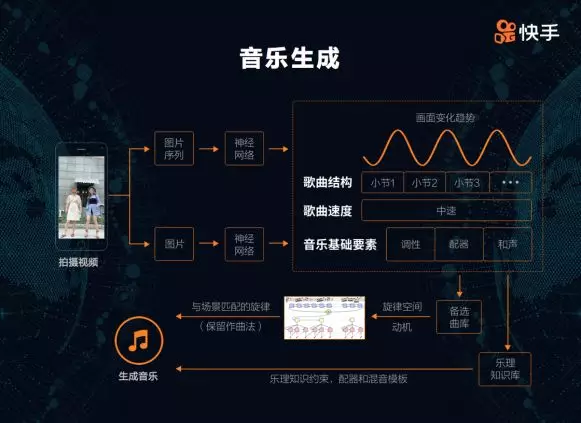
通过上述音乐要素,从备选曲库中筛选合适的乐谱组成旋律空间。音乐的动机是由几个小节组成的旋律片段,它是音乐的核心,整首歌曲都围绕动机展开。在自动编码器网络中,动机被表示为一个向量,旋律空间被表示为若干的向量序列。在动机与旋律空间的约束下进行采样,生成新的向量序列,再通过解码网络生成新的旋律。同样的动机,在相同的旋律空间下,也可以生成情感、风格相似,但表现上又有差异的音乐作品。常见的 AI 旋律生成算法,难以保存作曲手法,生成较长的旋律片段时,整个作品的走势会难以控制。采用旋律空间加动机的方式,能够有效解决该问题。对旋律进行自动化的配器和混音,最终生成符合视频内容的音乐作品。
音乐生成涉及很多具体的技术,其中一个问题是懂音乐的人不懂计算机科学,懂计算机科学的人不懂音乐。想要把短视频配乐这个问题研究好,需要有做音乐和做 AI 的人一起集成创新,这方面快手也做了非常多的工作。
iPhoneX 问世时的一项标志性功能,是通过结构光摄像头实现 Animoji,现在国内手机厂商也越来越多地采用结构光的方式去实现 Animoj。而快手是国内较早实现不使用结构光,只用 RGB 图像信息就实现 Animoji 效果的企业。
用户不必去花上万元去买 iphoneX,只要用一个千元的安卓手机,就可在快手的产品上体验 Animoji 的特效,从而能够在不暴露脸部信息的同时展现细微的表情变化,例如微笑、单只眼睛睁单只眼睛闭等,让原来一些羞于表演自己才艺的人,也可以非常自如地表达。
其实解决这样一个问题是非常难的,即使是苹果,也采用了结构光这样配置额外硬件的方式来解决。想让每一个用户都能享受到最尖端的技术,快手面临着硬件的约束,只能通过 2D 的 RGB 视觉信息对问题进行建模、求解。
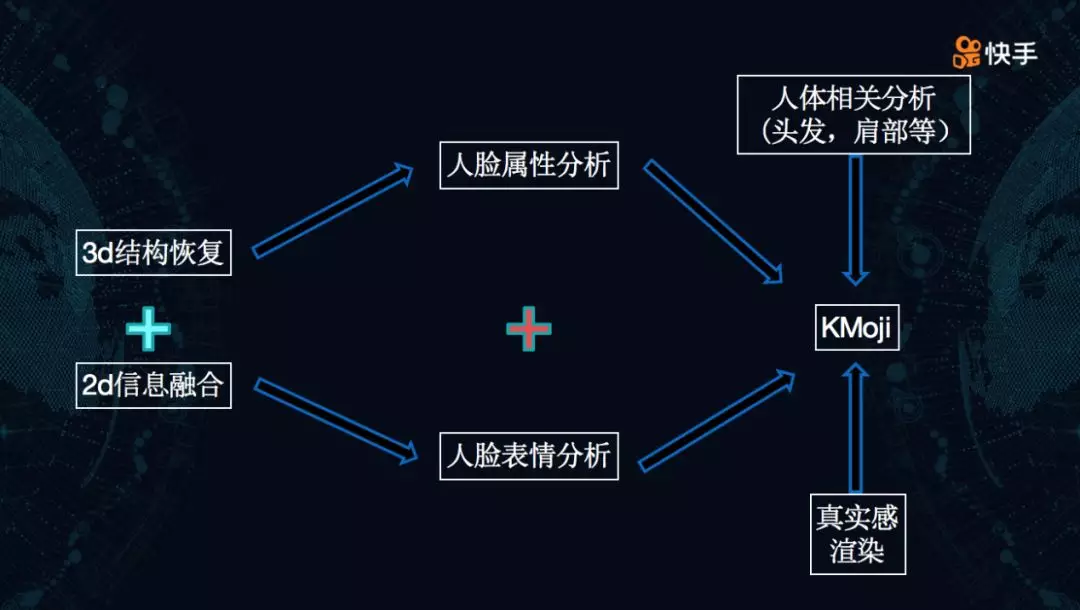
整个模拟人脸的过程借助了 3D 结构恢复与 3D 信息融合,用 3D 重建技术恢复出 3D 结构,融合 2D 信息后,分析人脸特征,进而生成虚拟形象。
3D 人脸重建需要借助快手内部的上万级 3D 人脸数据集,包含每个人的年龄段、人种、脸型和表情,通过人脸关键点识别技术,帮助 3D 人脸重建,不论表情是哭是笑都可以重现出来。
此外,生成虚拟形象还要分析用户的人脸属性,借助分类 / 回归 / 分割等方法,区分出性别、年龄、肤色、脸型等信息。
之后,因为生成的 3D 卡通图像是会随着人的表情而变化的,需要分析人脸表情,才能在卡通形象上展示出一模一样的表情。
这里需要通过 2D 的 RGB 视觉信息对问题进行建模求解,获得人脸关键点和实时重建的 3D 模型,把各种模态信息做建模、做对齐,求解出人脸的表情,驱动虚拟卡通形象做各种逼真的动作。
此外,快手 Animoji 的体验非常流畅,也需要归功于深度神经网络模型的量化。为了让模型在手机端流畅运行,需要进行图像预处理,合并多种预处理操作,对预处理的图像内存进行统一分配和回收,利用 NEON 加速和苹果自带的 accelerate 加速,让运行库只占 2M 的空间。
最后,在保证预测精度的前提下,快手技术团队对 AI 模型进行局部的 INT8 量化,使得运行速度可提高 1 倍以上,同时 AI 预测模型的占用空间也压缩到将近原来的四分之一。
除了帮助用户更好地记录,快手也希望通过一个更好的分享机制,让用户发布的视频能够被更多感兴趣的人看到,这也涉及视频推荐里面多模态的一些问题,其中有两点值得分享:
第一,我们强调音频和视觉的多模态综合的建模,而不是仅仅是单独的视觉或者音频,视觉和听觉两种媒体的融合,会是未来一个重要趋势。
第二,工业界和学术界所做的研究有很大区别,快手有非常多的用户数据,这些用户数据是不在传统多媒体内容研究范畴里面的,但是工业界可以很好地利用这些数据,更好地做内容理解。
举个例子,一个男子表演口技的视频中,如果关闭声音,仅凭画面信息,我们并不知道他是在做什么,可能会觉得是在唱歌或唱戏。这说明如果仅仅是通过视觉的话,人们可能无法获得真实的信息。我们对世界的理解一定是多模态的理解,而不仅仅是视觉的理解。
快手数据库中有 80 亿短视频,想要理解这么多的视频内容,必须借助多模态技术。我们从文本、视觉、听觉角度去做了很多单模态的建模,包括多模态的综合建模、有序与无序,以及多模态特征之间怎样进行异构的建联,在很多任务内部的分类上也做了改进。
另一方面需要强调的是, ImageNET 等很多学术界研究内容理解的任务有完善的标注数据集,但是这个数据集对于工业界而言还是太小,且多样性不够。快手每天有 1.6 亿用户、超过 150 亿次的视频播放,这个数据是非常大的。如果有 150 亿的标注数据,做算法就会有很大的帮助,但是现实上是不具备的。
怎样将研究分析技术与海量数据更好地做到融合?快手通过融合行为数据和内容数据,进行综合建模。同样大小的人工标注量,利用海量的用户行为数据,能够获得比纯内容模型更好的性能,对视频有了一个更好的理解,进而在多媒体内容的理解和分析方面的算法研究有了非常大的进展。
其实在目前来看,多模态研究难度还是非常高的。
其中大家谈得比较多的是语义鸿沟,虽然近十年来深度学习和大算力、大数据快速发展,计算机视觉包括语音识别等技术都取得了非常大的进展,但是截至现在,很多问题还没有得到特别好的解决,所以单模态的语义鸿沟仍然是存在的。再者,由于引入了多种模态的信息,所以怎样对不同模态之间的数据进行综合建模,会是一个异构鸿沟的问题。
另外,做语音、做图像是有很多数据集的,大家可以利用这些数据集进行刷分、交流自己算法的研究成果。但是多模态的数据集是非常难以构建的,所以我们在做多模态研究时是存在数据缺失的问题的。
多模态技术的未来应用方向展望
首先,多模态技术会改变人机交互的方式,我们与机器交互的方式将会越来越贴近于更令人舒适、更自然的方式。比如我们刚才讲的 Animoji 技术,其实它带来的是一种可以通过人脸控制手机自动生成 Avatar(虚拟动画)的体验。原来实现这些效果,需要在好莱坞专门设一个特效室来实现这一点,而现在普通用户都能享受这样的技术,所以人机交互会由原来重的、贵的、笨的方式转变为便宜的、每个人都能参与的而且便捷的方式。
第二,多模态技术会带来新的内容形态,原来接入信息更多是从文本、页面中获得,现在有视频,未来可能还会有 AR 或者其它的形式。多模态 AR 很重要的一点就是强调沉浸感,这种沉浸感其实是通过听觉和视觉综合作用才能产生的。
第三,多模态亟需新的算法和大型的数据,因为这两者可能会是一个某种意义上可以相互折算的问题。以目前的机器学习算法来讲,需要海量的数据才能解决好这个问题,因为现在深度学习、内容理解的成果,某种意义上是监督学习的成果,有足够的样本、算力,所以现在的算法能力基本上还停留在对算力和数据有着非常大要求的阶段。而多模态的大型数据是非常难建的,而且多模态解的空间是更大的。因为一个模态解的空间是 n,另外一个是 m,它最后是一个乘积、一个指数级的变化,所以数据集要多大才足够是一个很难的这个问题,可能需要新的算法来对这个问题进行建模。
作者简介
李岩,毕业于中国科学院计算技术研究所,中国计算机学会多媒体技术专业委员会常委。现任快手科技多媒体内容理解部(Multimedia Understanding, MMU)负责人,带领快手科技近百人的算法研发团队,团队成员多来自清华大学、中科院和日本京都大学等国内外顶尖高校和科研机构。





行业专家共同推荐的软件
包图网
- 4.2
(241)咨询产品免费试用稿定设计
- 4.0
(193)咨询产品免费试用fotor懒设计
- 4.1
(49)咨询产品免费试用



限时免费的在线作图软件
千图网
- 4.1
(293)咨询产品免费试用创客贴
- 3.9
(243)咨询产品免费试用摄图网
- 4.2
(86)咨询产品免费试用



新锐产品推荐
慧言AI开放平台
- 0.0
(0)咨询产品免费试用萤石开放平台-人脸识别
- 0.0
(0)咨询产品免费试用伟峰OA
- 4.0
(10)咨询产品免费试用跨境好运 跨境物流管理平台
- 4.3
(4)咨询产品免费试用金思维企业资源计划
- 0.0
(0)咨询产品免费试用金思维协同办公管理系统
- 4.0
(25)咨询产品免费试用







