内容推荐已成主流,这些问题必须解决
编者按:本文作者闫泽华,摘选自其新书《内容算法:把内容变成价值的效率系统》。
在推荐系统的实践中,我们常会遇到各种问题。
1.推荐重复
在内容生产门槛不断降低、产量持续攀升的背景下,当一个新闻事件发生后,权威新闻源会发布新闻通告,自媒体会从不同角度进行评论,搬运工也会批量产出蹭热点的内容。
内容的大繁荣也带来了信息的过载问题。对用户来说,其需要的是有价值的信息而非千篇一律的内容,用户可能会厌恶列表页上千篇一律的标题,更会因为点击了标题后却发现内容了无新意而怒发冲冠、拍案而起。
重复,对于内容推荐来说,是一个必须解决的问题。
结合用户的使用过程,我们将用户对内容的消费拆解为列表页消费和详情页消费。前者关系到点击前的消费预判(如图1左),后者则代表了用户点击后的消费体验(如图1右)。
图1列表页消费和详情页消费
基于这两个维度拆分,我们能够得到一张 2×2 的表格,如下表所示。

四种场景分别对应了内容重复的四种处理方式:
情况A(甲、乙两篇内容,列表页和详情页都相同):从消费角度来看,甲、乙两篇内容对用户来说是具有替代性的。
用户消费了甲内容之后,大概率不需要再消费乙内容了。那么,对推荐系统来说,就需要从甲、乙两篇内容中进行选择,选出应当展示给用户的内容。因此,问题从内容选择转变为信息源选择,需要深究重复构成的原因和内容的消费特点。
搬运号对原创内容的抄袭:展示原创内容,对搬运者进行惩罚。
媒体机构发布的新闻通稿:选择首发、权威度高的媒体,或是基于用户订阅关系,给用户推荐他订阅的自媒体。
热点转发内容:在这种场景下“被谁转发”是有一定信息量的。我们会基于用户跟转发者关系的紧密度来判断是否需要展示,紧密度低则不展示。
对于某些具有重复消费属性的内容,如音乐、评书、相声等,可以通过产品设计方式(如历史记录、再看一次、收藏列表、播单等形式)让同样的内容重复出现。
情况B(甲、乙两篇内容,列表页不同但详情页相同):在转载的情况下,一篇内容以不同的“妆容”展现在列表页当中。这时就需要进一步分析,以确定用户是否看过此内容。
如果用户点击过甲内容,那么给他推荐乙内容的必要性是不大的,因为从点击后的消费体验来看,用户并没有获得额外收益。如果用户没有点击过甲内容,那么乙内容因为发布者、标题、封面的不同,带给用户的列表页消费预判是不一样的,也就有了进一步推荐的必要性。头条号的脑洞功能“双标题+ 双封面”就是一个实际的应用。
情况C(甲、乙两篇内容,列表页相同但详情页不同):典型的例子如红烧肉的做法、郭德纲最新爆笑相声等,尽管用户点击后的消费体验不同,但是相似的列表页展示会给用户带来消费决策上的困惑。
如果用户点击过了甲内容,他十有八九会以为乙内容与甲内容是重复的,从而忽略;如果用户在列表页看过但是没有点击甲内容,他也会大概率地错过乙内容。对于这种情况,应该拉长两篇内容的推荐间隔,将其视作一个密集打散问题处理。
情况D(甲、乙两篇内容,列表页和详情页都不同):这种情况是最简单的。两篇完全不同的内容,互相不构成对用户消费预判的影响,分别推荐即可。
2.推荐密集
我们承接重复问题继续讨论。密集是指用户的推荐列表中同一类内容的占比过高,导致局部多样性丧失。
导致推荐密集的原因,一方面是因为用户的短期兴趣点通常比较明确,会因为特定事件或人物而快速聚焦。比如,建军节阅兵时,哪怕娇滴滴的女生也会被解放军的飒爽英姿所吸引。围绕阅兵,会产生如军事分析、士兵英姿、爱国抒怀等不同切入点。伴随热点,人们的消费量也会在这一阶段显著攀升。
另一方面则是因为推荐系统对用户的兴趣点理解不够,或是仅追求点击导向而放大了用户的强兴趣相关内容,从而忽视了用户的弱兴趣相关内容。比如,系统只知道用户喜欢财经,就围绕财经内容翻来覆去地推荐,或是在财经内容和科技内容所构成的候选集对比中,由于财经内容点击预估显著高于科技内容,系统就只推荐财经内容。
从点击率角度观测,局部的密集满足了用户需求,往往会带来短期消费量的快速提升。这未必是件坏事。我们在有关用户冷启动的部分也提到,为了短期留存用户,系统会刻意牺牲多样性,以新、热内容来满足用户的短期需求。
但是,不同用户短期兴趣点的衰减速度是不可预知的。比如,对于阅兵的内容,可能到第三天就无人提及了。有关NBA 的赛事报道在赛季结束后,也再无更新。
为了防止用户体验发生断崖式的下跌, 从产品角度来看,还是希望避免一次刷新中出现内容过度密集的情况。通常,我们采用滑动窗口规则,即连续多条规则尽可能在多个维度打散,降低用户的视觉密集感。
密集的衡量取决于我们对内容的理解拆分维度,能够拆分出的维度越细致,可以做出的打散策略就越细致。典型的可以拆分的维度有题材载体维度、作者维度、类目(话题)维度和实体词维度。
题材载体维度:属于同一内容载体的内容过多,比如一屏幕都是视频或图集。
作者维度:来自同一作者的内容过多,比如高产量的媒体型账号刷屏的现象。
题材和作者属于内容的固有属性,类目和实体词则是基于语义理解抽离出来的属性。
类目(话题)维度:来自同一分类(话题)的内容过多,比如阅兵期间有关阅兵的内容大量展现。
实体词维度:讨论某一实体词的内容过多,比如都是关于某位明星名人的各种维度的论述。典型的例子如马云,横跨财经、科技、教育等多个领域,在系统对于类目识别准确的前提下,依靠类目打散都不能解决马云刷屏的问题,只能通过实体词进行打散。
关于密集打散的收益,我们通常会站在用户长期留存的角度去衡量。多样性更好的内容在短期可能会降低点击率,但长期来看,对用户留存是有帮助的,不必争朝夕之短长。
3.易反感内容
在内容推荐系统中,我们将用户的行为拆分为列表页的消费决策和详情页的消费体验两部分。无论是详情页的消费体验差还是列表页的消费体验差,都是需要处理的问题。如图2示,列表页中展现出了标题和封面信息供用户判断,用户点击了前两篇内容,没有点击第三篇内容。
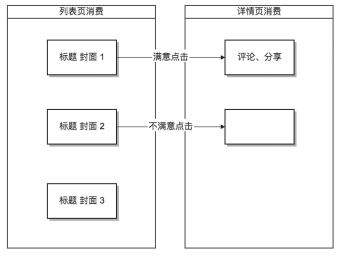
图 2 列表页消费与详情页消费
从内容质量维度看,低质量的内容一定会引发用户的反感,如文不对题的标题党、传播虚假信息或耸人听闻信息的猎奇党、质量低下的无聊水文、因时间识别错误导致的旧闻问题等。如图 2中第二篇内容的情况,用户在被标题吸引点击后可能很快就会退出,或是在内容当中举报,留下负面评论内容等。我们可以通过用户的反馈行为来发现第二类内容,以降低它们对用户体验的影响。
但是,对于列表页刷过但是没有被点击的内容(如图 2第三篇内容)又该怎样处理呢?
通常,我们将没有被点击的内容视作对用户无损,它起到了如兴趣探索、广告变现等作用。但在实践过程中,我们发现有部分内容会因题材问题而非质量问题,对部分敏感用户的列表页消费体验造成负向影响,我们将之归结为易反感内容。常见的易反感内容有:
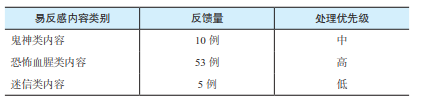
鬼神类内容:如灵异故事、UFO(不明飞行物)等
恐怖血腥类内容:如蛇、野生动物等
迷信类内容:如算命、风水等
对易反感内容而言,先要识别得准,再要推荐得好。
识别过程采用的是数据产品中定量分析处理问题的通用流程:分析影响面、定义标准、数据收集标注、模型评估。
分析影响面旨在帮助我们更好地确定待解决问题的优先级,将有限的精力优先投入到收益场景更大的事情上。就易反感内容的影响面而言,用户的反馈量统计就是一个衡量标准。将一定周期内用户的反馈进行整理和标注,对应到不同的易反感内容类别上,就得到了各个类别的影响面情况(如下表所示)。
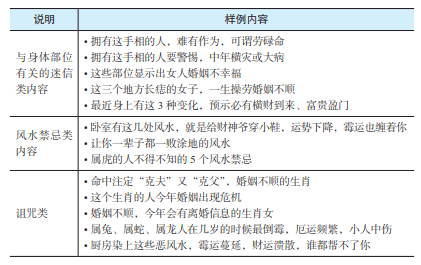
迷信类内容标注示例
数据收集与标注是为模型训练做准备的。基于对标准的理解,标注人员通过双盲校验的方式标注出足够进行模型训练的数据。在大型互联网公司,通常都有专门的数据标注人员负责企业数据的标注和整理。
在研发产出识别模型后,产品经理还需要对模型的准确度和召回度进行评估。在不同的应用场景下,准确和召回的平衡度是不一样的。在易反感问题上:如果要强化读者端的体验,尽量不让用户看到易反感的内容,就需要重视召回率,宁肯误删也不能漏删;如果要强化作者端体验,希望作者的内容尽量不要被误删,则需要重视准确率,适当露出一些置信度低的结果或增加人工复审捞回流程以保证内容不至于被错杀。
在推荐过程中,对易反感内容的推荐处理是一个强化负反馈的过程。
在列表页展示层,对普通内容而言,如果用户不点击的话可以视作无损,而对于易反感内容,即使用户不点击,也应当视作一个负向反馈,拉长此类内容的二次探索周期。
以推荐蛇和NBA 内容给女性用户为例。如果用户都没有点击,那么可以将NBA 内容在下一个周期(比如 5 天)再次推荐给用户,作为二次探索尝试;但蛇的内容就应该推迟多个周期后才推荐,以降低对用户可能的影响。
在令用户反感的行为上亦然。用户往往只会点击页面上的关闭按纽,而不会选择具体原因。如果一篇内容同时命中多个点的话,容易引起反感的原因理应受到更大的惩罚值。
由于易反感内容多发生在探索环节,主要影响用户的列表页体验,故在统计上并不会显著影响留存。但对此类内容进行更细致化的处理印证是做内容分发的初心:如你所愿,阅你所悦。
4.时空限定内容
作为一种消费品,内容是有特定消费时空限定的。如果以商品做对比的话,就如同端午节卖月饼、在上海卖豆汁儿一样,销量必然惨淡。深入理解内容的时效性和空间性消费特点,能够帮助我们更好地提升消费体验、促进内容消费规模增长。
在时效性上,不同的内容有不同的保鲜期。
短时效性内容,以赛事、股市信息为代表。这类内容具有保质期短、时效性强的特点。它们可能会每半小时更新一次。在新版本的消息出来后,旧的消息就完全没有价值了。比如:演唱会预告的内容,就不应该在演唱会之后再推荐出来;赛事结束后,中场的消息就不应该再展示了。
中时效性内容,通常可以覆盖绝大多数新闻内容,涉及最近发生的新闻事件,以天和周为时效性周期。比如,与电视剧《权力游戏》相关的内容生产与消费通常与电视剧播出节奏保持一致,在剧集播出之后,其热度逐渐衰减。
长时效性内容,具有跨时间维度的消费价值,可以是知识、案例分析等非虚构内容,也可以是小说、散文等虚构内容。对大型推荐系统来说,在处理内容时效性问题上,需要平衡两方面的问题:长时效性内容推荐的日期短了,会造成资源浪费;短时效性内容推荐的时间长了,会对用户体验造成伤害。因此,推荐系统会基于内容的特点预判不同内容的衰减周期和推荐策略。
对于短时效性内容,在识别层面,可以首先基于消费规模进行头部类目的覆盖(如介入可枚举的天气、股市、赛事、时事等信息),其次进行通用的时效性识别。
在推荐层面,短时效性内容需要更快速地传播到用户消费列表和推送场景上去。如果一篇内容正常需要一个小时的缓慢冷启动过程的话,短时效性内容可以依赖规则触发机制,在半小时内完成全量传播。比如天气、股市等信息,是完全可以对接权威官方机构,实现自动化分发乃至推送的。
对于中时效性内容,大多数在两三天的维度内均可消费(如娱乐、汽车、游戏、行业分析等),系统通常会视自己的内容产出速度来制定对应的衰减周期。大平台的衰减周期短一些,小平台的衰减周期长一些。
对于长时效性内容,最典型的应用场景就是搜索,什么时候被用户主动检索出来都具有一定的消费价值。对推荐系统而言,越大的候选集理论上能够产出的推荐效果越好。所以,我们实际做的是计算资源与点击收益的平衡,即什么样的内容值得被长时间保留在推荐候选集当中。用内容在垂类中的消费量衡量是个相对简便的方法。比如,围棋视频的平均消费量是 1 万次,而其中柯洁大战AlphaGo(阿尔法狗)的消费量是 10 万次,那么,就可以把它视作围棋领域内相对经典的内容,从而获得更长的推荐周期。
除了时效性,内容还具有地域消费性的特点:即时天气、本地新闻、同城活动、新店试吃等内容,都应当局限在特定的城市进行分发。如果分发到错误的城市,内容的实用性就会降低。
对于地域的识别,我们通常从正反两方面着手。正面的地域识别,可以通过标注本地媒体的方式来区分内容分发的范围(如《金陵晚报》的内容直接往南京分发),也可以通过内容中的关键词密度进行补充识别,如大篇幅提到海淀、朝阳,可能就是北京地区的内容。
反面的识别豁免,需要对如旅游、历史等类目的内容进行豁免,此类内容中会频繁出现地名,容易造成误伤。
本文摘选自闫泽华新书《内容算法:把内容变成价值的效率系统》

《内容算法:把内容变成价值的效率系统》
(闫泽华 著;中信出版社出版)





行业专家共同推荐的软件
包图网
- 4.2
(241)咨询产品免费试用稿定设计
- 4.0
(193)咨询产品免费试用fotor懒设计
- 4.1
(49)咨询产品免费试用



限时免费的在线作图软件
千图网
- 4.1
(293)咨询产品免费试用创客贴
- 3.9
(243)咨询产品免费试用摄图网
- 4.2
(86)咨询产品免费试用



新锐产品推荐
BRAVOWHALE祺鲲科技
- 0.0
(0)咨询产品免费试用一叶智能
- 0.0
(0)咨询产品免费试用章鱼IO
- 0.0
(0)咨询产品免费试用DataEye
- 0.0
(0)咨询产品免费试用爆米兔
- 3.0
(1)咨询产品免费试用pp匠
- 3.1
(2)咨询产品免费试用







