一张图解读《财富》人工智能万字长文,关于深度学习的前世今生
本文来自“百度大脑”(ID:baidubrain),36氪经授权发布。
导读:
自然语言处理、语音识别、用户画像、无人驾驶……这些和深度神经网络(即深度学习)相关的技术在最近几年突然火了起来,但深度学习并不是凭空冒出来的。它从最初的概念诞生,到现今备受技术和资本的青睐,历经了几十年的起起伏伏。读完这篇文章,你将弄清楚深度学习的前世今生。
这篇文章主要解读的是美国《财富》杂志(Fortune)近期发布的一篇名为「为何深度学习将突然改变你的生活」(Why deep learning is suddenly changing your life)的文章。这篇文章翻译成中文有上万字,但我们将只用一张图表和 10 分钟向你拆解这篇长文,讲述深度学习是如何成长为今天的样子的。
神经网络最早的概念诞生于 20 世纪 50 年代,而一些关键的算法突破则是在 80 至 90 年代才出现,今天深度神经网络能够得到广泛应用,得益于计算机硬件性能的大幅提升,以及海量数据的产生。
用百度首席科学家吴恩达的话来说,深度学习的进展和计算能力的提高和数据的增长密不可分。通俗地讲,我们可以把它类比于建造太空火箭:「你需要大功率火箭发动机,你也需要大量的燃料。如果你有许多燃料但只拥有小功率发动机,你的火箭大概无法飞离地面。如果你拥有大功率发动机但只有一点点燃料,你的火箭即使飞上天也无法进入轨道。」
计算能力的提高相当于发动机功率的提高,而数据就像是燃料。
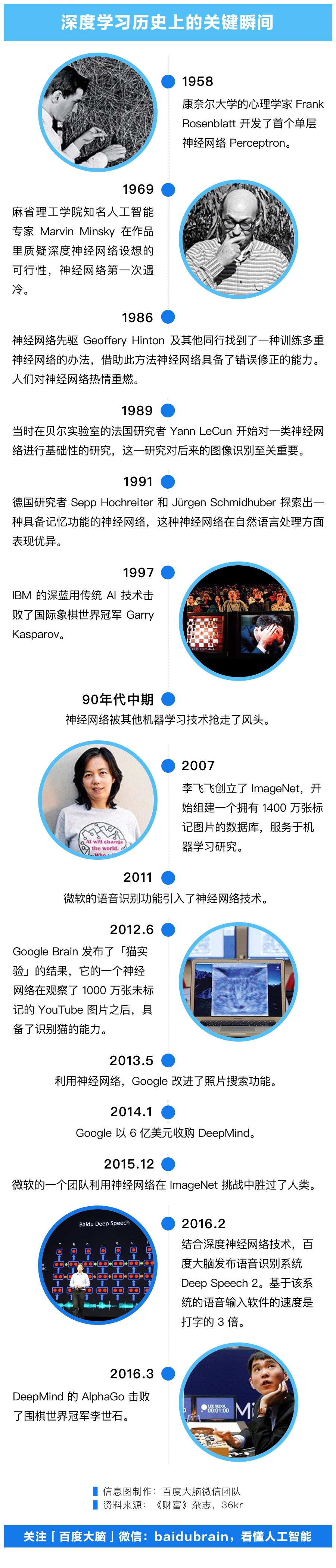
上世纪 50 年代,神经网络的研究潮流才刚刚在计算机科学家们之间流行起来。
1958 年,在一项受美国海军支持的项目中,康奈尔大学的心理学家 Frank Rosenblatt 搭建了神经网络的原型并给它取名为 Perceptron,它利用的是占据了整整一个房间大小的穿孔卡片计算机。经过 50 次测验,Perceptron 能够区分两种不同的卡片,其中一种左侧带有记号,另一种右侧带有记号。
Perceptron 软件结构和神经元类似,但和人脑神经的多层结构相比,只具有单层神经元的 Perceptron 能力有限,于是人们开始研究如何开发多层神经网络,也就是我们现在所说的深度神经网络。
神经网络先驱 Geoffrey Hinton 举了个例子:深度神经网络辨认图片里的一只鸟的过程。
它会先对输入的像素进行分析,如果其中的一些线条两侧亮度相差很大,它会判断出这可能是鸟的轮廓,并把数据传递给下一层神经网络。后者继续沿着线条去寻找一些和鸟类贴合的特征,比如线条转折交汇处形成的角度是不是和鸟类的喙的尖角相似。如果得到确认,数据会进入下一层,神经网络寻找更加复杂的外型,比如同样的线条有没有大致地围成一圈,形状和鸟类头部的相似性。再下一层,神经网络确定类似鸟嘴的形状和头部的形状是不是以恰当的方式接合在一起,如果是的话它就有相当充分的证据来说明这是一只鸟的头部了。
深度神经网络以类似的方式来对数据进行分析,每一层神经网络都基于上一层极的判断去分析更加复杂和抽象的特征,直到最高一层形成对整体形象的判断。
在 Hinton 提出他的想法之前,60 年代末乃至整一个 70 年代,人们都怀疑深度神经网络的可行性,例如著名的人工智能科学家 Marvin Minsky。直到 Hinton 和其他科学家找到了训练深度神经网络、纠正其错误的方法时,深度神经网络才重回人们的视野。
改变深度学习的这个关键过程就是,除了像前面描述到的那样将信息层层推进分析,如果最后得出的结果是不匹配,深度神经网络还需要把这一信息逐层返回给更低一级的类神经元,以便它们调整激活来优化最后的结果,这就是深度神经网络学习的过程。
1986 年,Hinton 和他的两位同事发表了一篇论文,其中他们提供了一种算法来解决这种错误修正难题,深度神经网络学习能力的质疑得到了解决,神经网络的第二波潮流由此开始。
之后直到 20 世纪 90 年代中期,图像识别、手写数字辨识、自然语言处理等系列技术都取得了奠基性的成果,这些技术成果至今仍然在广泛应用。
20 世纪最后的几年里,受限于当时的计算能力,深度学习还不是机器学习中最高效的工具,这种有点超前的技术不可避免地再次遇冷。1997 年,IBM 著名的人工智能深蓝打败了当时的国际象棋冠军 Garry Kasparov,但它采用的并非深度神经网络技术。
直到 2007 年,斯坦福大学教授李飞飞成立了 ImageNet 并开始组建一个有标记图片的数据库,两年后该数据库组建完成,1400 万张经过标记的图片免费开放给机器学习研究者使用。此时硬件的计算性能也已提高到了足够处理这些数据的程度,火箭需要的发动机和燃料都有了,是时候试飞了。
这里我们需要解释一点,为什么 ImageNet 出现之前互联网上大量的开放数据不能被应用于深度学习?这也是目前深度学习面临的局限,大部分深度学习创造的价值仍然来自于监督学习技术。监督学习技术需要基于系统曾经接受过的其他实例输入,来学习对东西进行分类或对结果进行预测。
例如前面提到的,给你一张图片,请你把鸟从图片里找出来。或者像给你一封邮件,请你判断它是不是垃圾邮件。在监督学习的过程中,深度神经网络先前接受的这些输入信息需要有一个标记信息,它相当于我们做训练题时的参考答案,深度神经网络把自己的分析结果和它进行对比,从而优化分析过程和纠正错误。如果输入的信息中没有关于实际上图片里有没有鸟的标记,或者关于这封邮件实际上是不是垃圾邮件的标记,它就无从学习。这就像我们做完练习题却并不知道自己答得对不对,这对于我们下一次碰到类似的题目大概毫无助益。因此,ImageNet 这样「有参考答案的习题」就显得十分关键。
当然我们还知道另一种深度学习技术:无监督学习。
2012 年 6 月,谷歌推出的「猫实验」项目就是对无监督学习的一次探索。在「猫实验」中,谷歌大脑开发的一个大规模神经网络凭借 1000 万张来自 YouTube 的未标记图片学会了分辨猫。吴恩达当时正是谷歌大脑的负责人,他当时发现经过无监督学习的神经网络对人脸也有辨识,但也有一些神经网络辨识出来的特征他们没能找到对应的词汇,无监督学习方面的算法在很大程度上仍然处于摇篮期。
随后的几年里深度神经网络技术被运用到谷歌的语音识别、图片搜索乃至前一阵子的谷歌中英文互译当中。它最耀眼的时刻仍然是配备神经网络的 AlphaGo 击败韩国世界级棋手李世石的那一刻。
而在商用方面,能够将深度学习进行商业应用的仍然是几家掌握了海量数据的公司,例如百度、Google、微软和 Facebook。目前百度大脑已经将深度神经网络技术应用到语音识别、翻译、图片搜索以及百度无人车等领域中,并且取得了一些惊人的成就。
以语音识别为例,来自斯坦福、百度以及华盛顿大学的数据科学家们在今年进行了一项研究,对语音识别输入效率和打字输入效率做了对比,该研究采用的深度学习技术来自百度深度网络语音识别系统 Deep Speech 2,其对中文(普通话)和英文的语音识别输入速度比打字快 3 倍左右,错误率则明显少于后者。参与其中的一位斯坦福计算机科学博士表示,尽管他们有过大概的预期,但实验结果还是让人吃惊。
「在过去,许多标普 500 指数公司的 CEO 希望自己能早点意识到互联网战略的重要性。我想从现在开始的今后 5 年也会有一些标普 500 指数公司的 CEO 后悔没有早点思考自己的 AI 战略。」这是吴恩达对人工智能战略地位的概括,人工智能技术的重要性已不言而喻,而深度学习也许是其中最值得期待的一项。





行业专家共同推荐的软件
包图网
- 4.2
(241)咨询产品免费试用稿定设计
- 4.0
(193)咨询产品免费试用fotor懒设计
- 4.1
(49)咨询产品免费试用



限时免费的在线作图软件
千图网
- 4.1
(293)咨询产品免费试用创客贴
- 3.9
(243)咨询产品免费试用摄图网
- 4.2
(86)咨询产品免费试用



新锐产品推荐
联客SCRM
- 0.0
(0)咨询产品免费试用微链云SCRM
- 0.0
(0)咨询产品免费试用金山AIDAtrans
- 4.4
(2)咨询产品免费试用微量云SCRM
- 2.5
(1)咨询产品免费试用微有米
- 4.0
(1)咨询产品免费试用鱼塘多销SCRM
- 0.0
(0)咨询产品免费试用







