野心不小:谷歌知识图谱计划让计算机获得"常识"
计算机是傻瓜,在人类看来是常识的东西,它却一无所知。
比如我们在搜索一条登山路径的路况时,从常识就能判断,其它登山路径的路况也是我们所需要的。但计算机没有“常识”,它不会自动把其它登山路径的信息放入我们的搜索结果。Metaweb的联合创始人John Giannandrea在1979年就认识到了计算机的这一局限。当时还在Netscape工作的他就开始想办法通过使计算机获得常识,从而使人们能够获取一些他们原本一无所知的信息。
八年之后,Giannandrea与Danny Hillis和Robert Cook合作创立了Metaweb。
Metaweb试图克服计算机没有常识的这一局限,而解决方案就是用模型数据库去刻画整个世界,使计算机获得一个常识知识库。
Giannandrea认为应该把世界上的所有事物以及他们之间的关系作为实体放进一个模型数据库。比如当我们要把Mojito鸡尾酒放进数据库时,首先我们会把Mojito作为实体放入数据库,接着作为Mojito成分的薄荷、朗姆酒、冰也会被作为实体放进数据库。和其他一些标准数据库不同的是,薄荷、朗姆酒、冰与Mojito的这样一种组成关系本身也会作为实体放进Giannandrea所构想的数据库。有了这样一个模型数据库做支撑,计算机就可以带着“常识”工作了。比如:
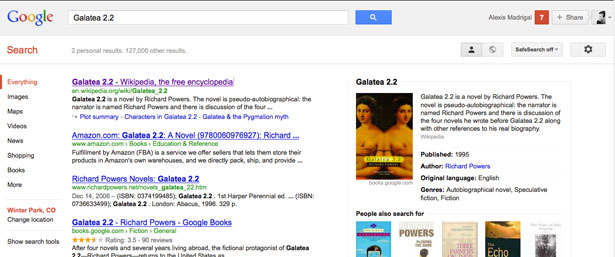
当我们用搜索引擎搜索Mojito(一种鸡尾酒)时,具有“常识”的计算机就能判断用户可能对Mojito的成分也会感兴趣。于是关于薄荷、朗姆酒和冰等Mojito成分的信息也会出现在搜索结果的相关列表里。
抱着这样的想法,Giannandrea和他的同事们开始了模型世界数据库的建立工作。工作前五年,数据库收录了1200万个实体。之后Metaweb被Google收购,并且在上个月被作为
谷歌知识图谱(Google Knowledge Graph)正式推出。被Google收购的第一年,Metaweb数据库的实体量增长到了2500万。除了钱,Google的收购为Metaweb还带来了什么?当然是数据。收购以前,Metaweb只能猜测用户可能想知道的信息。而Google为Metaweb带来了海量关于用户搜索习惯的数据,通过它Metaweb能够对用户的搜索需求做出更准确的判断。
把世界放进一个数据库,这似乎是一个庞大的有点可笑的事。但谷歌知识图谱的发布说明至少Giannandrea带着他的团队已经走出了第一步。同时计算机这种带着“常识”的搜索方式,也在大胆的挑战着人们传统的搜索习惯。人们是否能接受这种搜索新功能,作为
占有全球搜索引擎市场超过70%市场份额的Google必须谨小慎微。
via
theatlantic





大厂都在用的在线作图软件
包图网
- 4.2
(241)咨询产品免费试用稿定设计
- 4.0
(193)咨询产品免费试用fotor懒设计
- 4.1
(49)咨询产品免费试用



限时免费的在线作图软件
千图网
- 4.1
(293)咨询产品免费试用创客贴
- 3.9
(243)咨询产品免费试用摄图网
- 4.2
(86)咨询产品免费试用



新锐产品推荐
英檬科技
- 0.0
(0)咨询产品免费试用百度智能云-文字识别
- 0.0
(0)咨询产品免费试用极客OCR
- 0.0
(0)咨询产品免费试用汉王OCR
- 3.7
(4)咨询产品免费试用开源IM
- 3.7
(2)咨询产品免费试用华为云WeLink
- 3.6
(13)咨询产品免费试用