日本少年教你用姿势估计把自己变成3D人物,动作实时同步,iOS上也能实现
编者按:本文来源于微信公众号“大数据文摘”(ID:BigDataDigest),作者 刘俊寰,36氪经授权发布。
不知道从什么时候开始,3D动画就热起来了,但是很多经典动画3D化后就变味了,人物的肢体动作看上去僵硬了不少。并且,传统3D靠一帧一帧制作,费时费力。

现在,你就拥有一个拯救3D动画的机会!
一位日本中二少年自学了机器学习后,就给自己做了个酷炫的模型,可以把自己的动作实时变成流畅的3D人物动作,而且整个过程非常简单易操作。
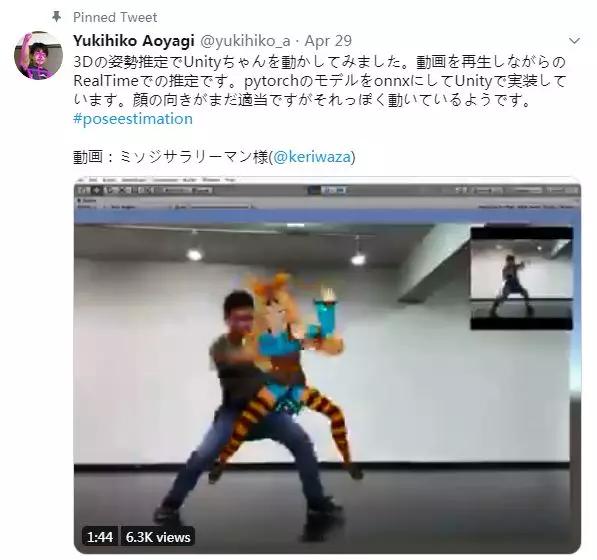
话不多说先看效果图:
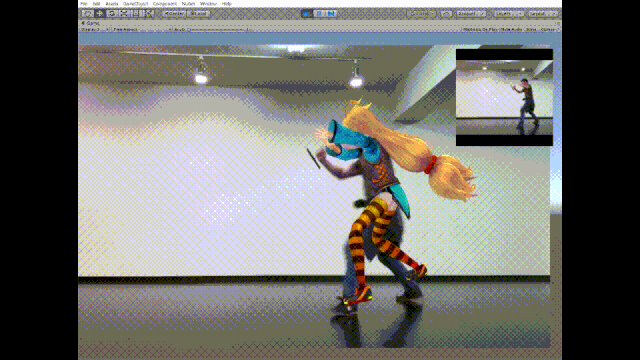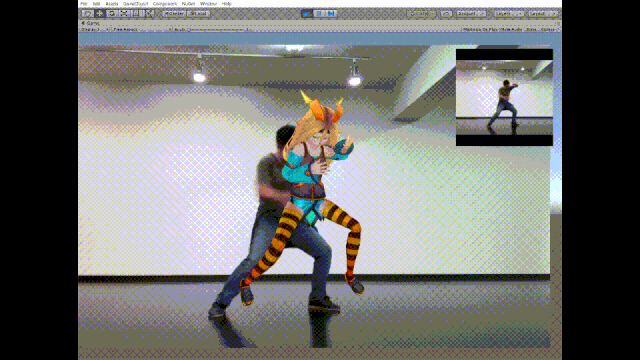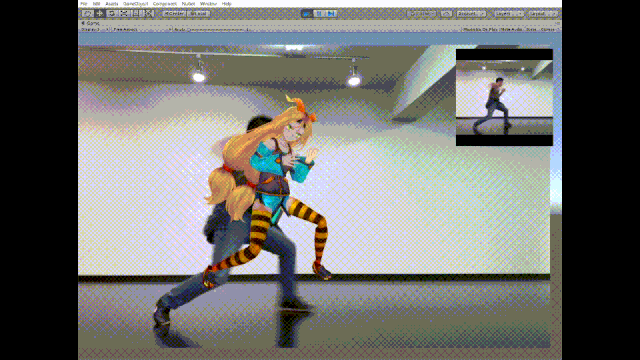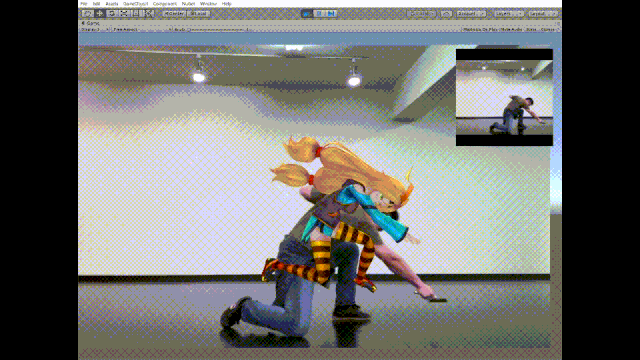
这个推特名为幸彦青柳(Yukihiko Aoyagi)的日本小哥将3D姿态估计与3D开发平台和一些渲染引擎(比如Unity)相结合,于此更够跟准确地跟踪3D空间中的人体运动。上面的动图就是针对动作的实时估计和生成。
不过可惜的是,这个项目目前还只支持单人动作,不能实现双人对打。
项目已经在GitHub上开源:
https://github.com/yukihiko/ThreeDPoseUnitySample?source=post_page-----e74d7d347c2----------------------
趁着它还没刷爆朋友圈,赶紧上手试一试!
用3D姿势估计的Onnx模型移动Unity
青柳君尝试过多种实现方式,包括WindowsML,ML.Net,Onnx Runtime等,但最终选择了OpenCVSharp,也就是OpenCV模型导入功能,在Unity中加载和执行Onnx,因为OpenCVSharp在Unity和.Net环境中可以用相同的方式处理,图像也不会被转换为Mat格式。
尽管看上去处理起来很容易,但目前还缺少相关数据,青柳君特意总结了他的这次尝试,将文章公布在了Qiita上。
相关链接:
https://qiita.com/yukihiko_a/items/386e3a86a5e523757707
有关Onnx的部分代码(点击链接查看)
模型输入224x224的图像,输出的关节数为24个,热图(Heatmap)为14x14。
2D热图格式是24x14x14,3D的是24x14x14x14。将其作为与热图的坐标偏移值,输出的2D(x,y)变为2x24x14x14,3D(x,y,z)变为3x24x14x14x14。
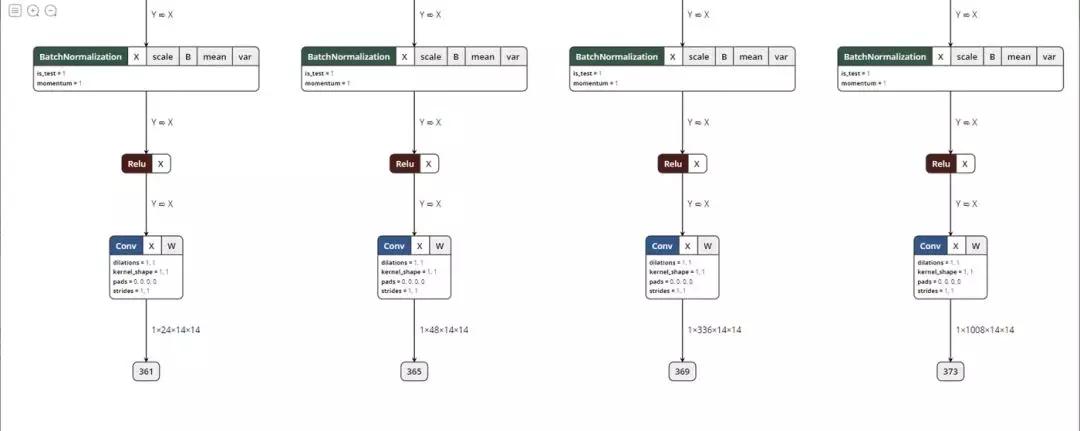
代码部分内容可点击链接查看
首先,使用InitONNX()读取Onnx文件。
由于OpenCV的输出是通过Mat对象返回的,需要准备四个数组。
代码部分内容可点击链接查看
Predict方法参数的Mat对象是正常的CV_8UC3 Mat图像数据,需要将其转换为Blob Mat才能传递给Onnx,这个过程利用BlobFromImage就能完成。
在Output中,“369”和“373”是3D,“361”和“365”是2D。但如果是Mat对象,处理起来就稍微复杂一些,因为还需要将其转换为float数组。
然后,通过改变关节数和热图大小,找到最大热图。
由于3D是一个相当大的循环,最好再做一些改进,但是由于它现在移动得足够快,保持原样也是可以的。
在iOS上也能实现3D姿势估计
去年的日本黄金周,青柳君第一次接触机器学习,也一直在3D姿势估计这块有所钻研。
今年3月份,他在iOS上实现了3D姿势估计。据本人推特发言称,他用了一天时间学习,然后做出了这个模型。

根据青柳君本人介绍,iOS项目的学习环境是Windows10/PyTorch0.4,执行环境是iPhone XS Max,至于选择iPhone XS Max的原因,青柳君说,iPhone XS Max的A12处理器功能非常强大。
还是先看看效果如何:
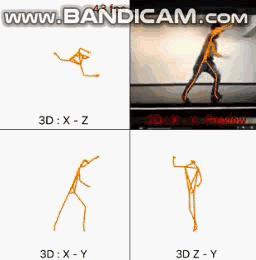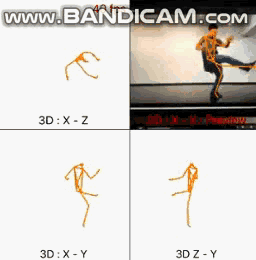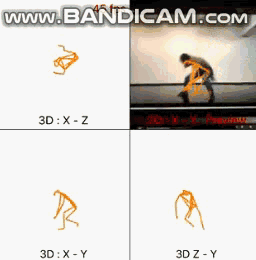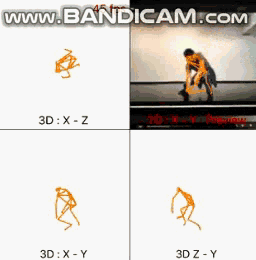
青柳君准备了2D和3D的数据集,2D数据集是利兹运动姿势数据集,利兹运动姿势扩展训练数据集、MPII人类姿势数据集、Microsoft COCO;而3D数据集是原始数据集。
在此之前他还做了很多准备,包括从AssetStore购买的数据等,当然还有Unity。
然后就可以利用Unity创建3D角色动画了,创建角色图像和坐标,包括肩膀、肘部、手腕、拇指、中指、脚、膝盖、脚踝、脚趾、耳朵、眼睛、鼻子,以输出身体的中心位置,即肚脐。
该数据集由于许可原因结果变得十分复杂,导致发布失败。
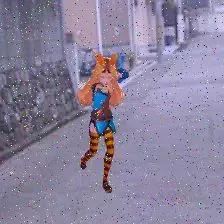
由于这是CG,因此可以随意更改角色的纹理和姿势。最初,他希望更改每个时期数据集的内容,以提高泛化性能,但没有效果,为此大约有100,000个副本用于学习。
即使是用3D版本的图像,也可以照原样学习,最后可以获得相似的图像,但是无法获得预期的性能。
将通过PyTorch学习得到的模型导出到Onnx,用coremltools转换为CoreML模型,此时就算是估计到了相同的图像,结果也会有所不同,所以准确度未知。
将模型导入Mac,使用XCode的iPhone版本,通过实时捕获后方摄像机图像执行3D估计。
XS Max能以大约40fps的速度运行,但是,一段时间,手机会变热,速记也会下降至约30fps。如果仅用于学习2D模型,其运行速度会接近100fps。
由于这是个3D项目,显示时无法从摄像机看到的部分,判断热图的阈值已降低到几乎为零。例如,如果手臂正常可见,热图的最大部分为0.5或更高(最大值为1.0);如果看不到手臂,将得到0.2或0.1的值,阈值降低。
但就结果而言,无论身在何处,系统都可以判断为有人。
Adobe发布最新动作追踪软件
上周,Adobe也发布了一款用于视觉效果和动态图形软件After Effects,该软件的AI功能能够自动跟踪人体运动并将其应用于动画。
简单地说,就是能够把现实人物的动作直接转换成为动画。

与青柳君的机器学习项目的效果相差无几!
Adobe研究科学家Jimei Yang在演示中说,这一功能利用了Adobe的人工智能平台Sensei,该平台用超过10000张图像进行了训练,从而能够识别人体的关键点。
据了解,人体跟踪器在源视频中能够检测到人体的运动,胳膊、躯干和腿部的18个关节点将生成相关跟踪点,然后将跟踪点转移到动画角色上,利用该功能,快速创建2D人物动画根本不在话下!
怎么样,有没有觉得打开了新世界的大门?
当然,对于姿势估计的实现还远远不止现在的程度,未来希望不仅是青柳君和Adobe,有更多人都参与到这个领域的研究和学习中来,促进相关领域的发展。





行业专家共同推荐的软件
包图网
- 4.2
(241)咨询产品免费试用稿定设计
- 4.0
(193)咨询产品免费试用fotor懒设计
- 4.1
(49)咨询产品免费试用



限时免费的在线作图软件
千图网
- 4.1
(293)咨询产品免费试用创客贴
- 3.9
(243)咨询产品免费试用摄图网
- 4.2
(86)咨询产品免费试用



新锐产品推荐
WotoHub卧兔
- 0.0
(0)咨询产品免费试用钛动科技UniAgency
- 0.0
(0)咨询产品免费试用NoxInfluencer
- 0.0
(0)咨询产品免费试用亚思博-网红营销
- 0.0
(0)咨询产品免费试用Scrumball
- 0.0
(0)咨询产品免费试用宝兰德软件-应用服务器软件Application Server
- 0.0
(0)咨询产品免费试用







