Facebook狂撒20万美元,悬赏用AI检测P图盗版问题
本文来自微信公众号“量子位”(ID:QbitAI),作者:博雯,36氪经授权发布。
只要你能检测出右边这张图片与左边的原图相似,说不定就能拿走Facebook的10万美元(64万人民币)奖金!

而对于这场寻找相似图片的比赛,Facebook AI共拿出了20万美元:

看上去像是你赚了Facebook亏了?
先来看看具体的比赛内容。
比赛内容
首先,在实际比赛中修改后的图片,并不像是开头那样简单。
而是会经过裁剪、翻转、填充、像素级转换、颜色过滤、亮度调整等多种变化:

参赛者拿到的这种修改图片大概有5万张。
而需要去对比的将是100万原图。
这些图片都来自于Facebook为比赛所建的一个新的数据集:ISC21数据集(DISC21)。
在这种情况下,参赛者可以从两个方向参与挑战:
- 无约束匹配
建立一个模型,直接检测某个修改后的图片是否来自给定的数据集。
- 受限匹配
生成图像向量表示(最多256维),将这些表示与欧氏矢量距离进行比较,以检测修改后的图片是否来自给定的数据集。
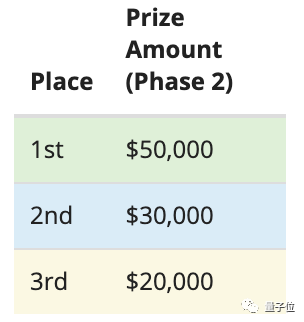
在挑战的最终阶段,两个方向的前三名都会获得奖金:
参赛者的模型将通过微观平均精度(micro-average precision)进行评估。本次比赛参考的基准如下:
而这次挑战主要面向美国地区18岁以上的成年人。
分为两个阶段
这项挑战也分为两个阶段:
一、2021年6月到10月,模型开发
参赛者研究官方的ISC21数据集来开发和完善模型。模型会被评估出一个分数,并展示在公共排行榜上。
建立模型时允许添加图像,但不能在图像之间做交互分析,只能对每张图像进行单独处理。
二、2021年10月26日到2021年10月27日,最终评分
参赛者的模型将面对一个新的5万张修改图像的数据集。
这时,除了要单独处理图像之外,也不能创建额外的图像标签。
最终用于社交媒体
比赛内容要求单独处理百万量级的图片集,很明显对标的就是现实情况。
而新图片不断增加、旧图片被不断删除、图片修改手法也更多的现实世界,比起这次挑战要复杂得多。
Facebook作为一个每天都在产生数10亿张图片的平台,每天都要面对监管违法图片、标记错误信息和广告、内容追踪、版权保护等各种任务。

△可能涉及到版权保护问题的添加了表情包的图片
他们希望比赛中所产生的相似图片检测技术能够用在像他们这样的社交媒体上。
比赛官网:https://www.drivendata.org/competitions/79/competition-image-similarity-1-dev/






行业专家共同推荐的软件
包图网
- 4.2
(241)咨询产品免费试用稿定设计
- 4.0
(193)咨询产品免费试用fotor懒设计
- 4.1
(49)咨询产品免费试用



限时免费的在线作图软件
千图网
- 4.1
(293)咨询产品免费试用创客贴
- 3.9
(243)咨询产品免费试用摄图网
- 4.2
(86)咨询产品免费试用



新锐产品推荐
法大大
- 3.9
(319)咨询产品免费试用石墨文档
- 4.0
(89)咨询产品免费试用Teambition
- 3.7
(90)咨询产品免费试用微盟微商城
- 3.8
(36)咨询产品免费试用有道云笔记
- 4.0
(73)咨询产品免费试用聚水潭erp
- 4.1
(5)咨询产品免费试用







