人类独特的三维感知能力,计算机能学会吗?
编者按:凭借一张平面图,人类能够毫不费力地推断出其潜在场景下完整的三维结构。将平面图像转换为三维图像是一项复杂的工作,所以我们必须要依赖之前的视觉经验。我们的视觉经验其实完全是由三维(3D)世界中的二维(2D)投影所组成的,因此,我们的三维感知能力的学习信号很可能是来源于3D现实中与不同视角所建立起一致的联系。在本文中,我们提出了一些预测3D模型系统的方法,这些方法建立起的系统同样能够以类似的方式进行三维感知学习。
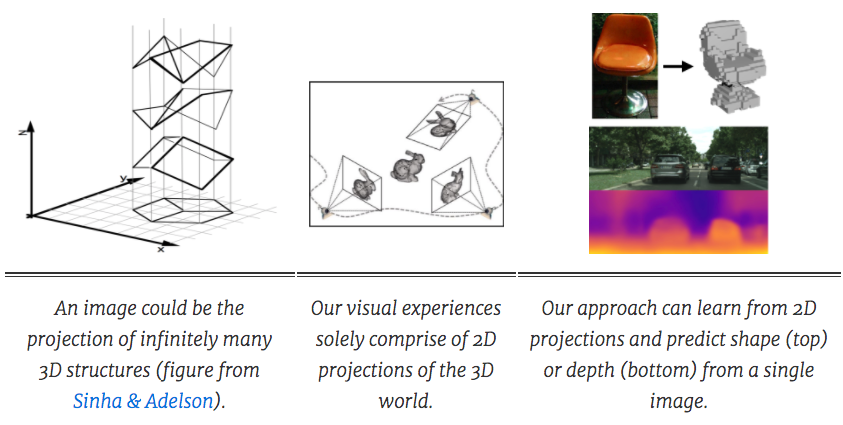
建立单张图像三维结构推断的计算模型,是计算机视觉界长期存在的一个问题。早期的一些尝试,比如Block World,都是利用了对几何线索的精确推理来优化3D结构的。近年来,监督学习使之前的方法在许多更现实的情境中也适用,还能推断出定性的3D表示(如Hoiem等)或定量3D表示(如Saxena等)。大规模地获取3D监督的成本非常高,所以我们希望我们的计算系统能够像人类视觉系统一样,在没有3D监督的情况下同样可以学习3D预测。
带着这个目标,我们探索了另一种学习3D结构的监督形式——多视角观察。有趣的是,我们研究工作虽然不同,但都有着共同的多视角监督目标;并且我们采用的方法也遵循着同样的原则。这些方法都是建立在学习与几何学的相互作用之上的,在这个过程中,学习系统做出的预测与多视角的观察应该是具有“几何一致性”的。因此,几何学充当着学习系统和多视角训练数据之间的桥梁。
通过几何一致性进行学习
我们的目的是去学习一个能够从单张平面图像推断出3D结构的预测器 P(通常是一个神经网络)。在监督环境下,训练数据包含来自不同视角的多种观察结果。正如之前所说的,几何学就是一个桥梁,它使用训练数据来学习预测器 P。这是因为我们清楚地知道在几何方程的形式下,一个3D 表征与其对应的 2D 投影之间的关系。因此我们可以训练预测器 P ,使其进行3D结构预测。

为了详细地说明这个训练过程,我们设置了一个检验器 V。我们首先给预测器 P 提供了一张图像 I,然后它预测出了一个 3D 形状 S。接着,我们给检验器V提供了这个预测结果S,以及从C视角得到的观测图O。检测器V会用几何方程式来验证它们是否一致。我们让 P 去预测一个能够通过V验证的3D结果S。这其中的关键在于由于预测器 P 并不知道(O,C)是用于验证其预测结果的,所以它需要预测与所有可能观察结果一致的 S(与未知的真实值 Sgt 相似)。
l 随机选取一张训练图像 I和从视角 C 得到的观察图O。
l 预测 S=P(I),用 V 来检测(S,O,C)的一致性。
l 更新 P,使用梯度下降,使 S 与(O,C)更一致。
l 重复上述操作,直到达到收敛。
最近采用多视角监督进行3D预测的方法都是遵循这个规律的,其差异就在于被推行的 3D 预测形式(例如深度或形状)和所需多视角观察结果的种类(例如彩色图像或者前景模板)。我们接下来将要看两篇能够推进多视角监督模型的论文。第一篇论文利用经典的射线一致性公式介绍了一个通用的检验器,这个检测器可以测量 3D 形状与不同的观察图 O 之间的一致性;而第二篇论文说明了我们甚至可以进一步放宽所需要的监督,并且提出了一种无需视角C就能学习从平面图到得出3D结构的方法。
可微分射线一致性
在近期的论文中,设置了一个检测器V来测量3D形状与2D观察图之间的一致性。通用的公式能够利用不同类型的多视角观测结果来学习体积式3D预测结果。
设置检测器V的原因之一是观测图O中的每个像素都与一条带有相关信息的射线相对应。这样一来,我们就不需要计算观测图O与形状S之间的一致性了,我们只需要判断形状S与射线r之间的一致性。

上图介绍了指定射线一致性的各方面的基础。a) 3D预测形状射线与样本射线一致性的测量;b,c)通过3D形状来追踪射线,并计算概率;d)可以测量终止射线和信息射线之间的差异;e)通过将射线一致性成本定义为预期的事件成本,我们可以计算梯度,并调整和更新至更具一致性的预测。在这个案例中,我们将一个深度观测图O可视化了,这个公式的优势之一在于它能够通过简单地定义对应事件的成本函数,组合各种观察结果(如颜色图片、模糊场景等)。
下图是在不同的情境中,二维图像通过我们的框架进行三维预测的结果。需要注意的是,所有的预测都是从预测器 P 训练的单张 RGB 图像中获得的。

从未标记的视频中进行深度和视角学习
在上述步骤中,输入至检测器V中的是一张从已知视角得到观测图。从一个具有感觉功能的有机体的角度看,这是非常合理的。但是在非结构化的数据源(比如视频)的应用中,这就不那么合理了。在近期的另一篇文章中,我们介绍了视角需求是可以放宽条件的,甚至,我们可以联结单张图像进行3D预测的学习。
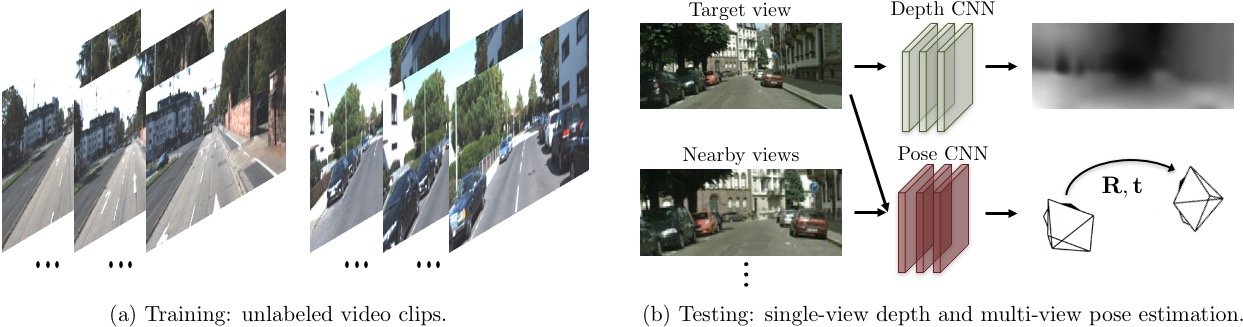
具体而言,在这个案例中的检测器V是建立在一个可微的深度视角合成器的基础之上的,这个深度视角合成器会用预测的深度投影和来自源视角的像素来输出一个目标视角。这里的深度投影和摄影视角都要被预测,而其一致性是由像素重建失误定义的。通过场景几何学习与摄影视角的结合,我们能够在未经标签的视频片段上,无需直接的监督,就能完成对系统的训练。
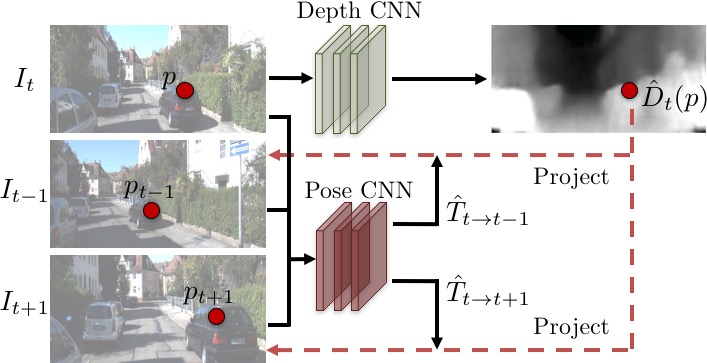
我们是在KITTI和Cityscapes数据集上训练和评估我们的模型的,这两个数据集中包含了大量汽车行进中捕获的视频片段。下面的视频中一帧一帧地展示了我们的单视角深度网络做出的预测。

令人惊喜的是,我们的单视角深度模型虽然未经过实际标签的训练,但是与成熟的SLAM系统达到了持平的效果。
在计算机视觉下,没有3D监督的情况下学习单张图像的3D结构是一个激动人心的话题。把几何学作为学习系统和多视角训练数据间的桥梁,让我们轻松地避开繁琐的操作程序和高昂的操作成本。更宽泛地说,我们可以讲几何一致性是理解元监督的一种形式。我们相信这样的方式对训练其他数据缺乏的解决问题的模型都能够发挥起作用。
注:本文由「图普科技」编译,您可以关注微信公众号tuputech,体验基于深度学习的「图像识别」应用。






大厂都在用的在线作图软件
包图网
- 4.2
(241)咨询产品免费试用稿定设计
- 4.0
(193)咨询产品免费试用fotor懒设计
- 4.1
(49)咨询产品免费试用



限时免费的在线作图软件
千图网
- 4.1
(293)咨询产品免费试用创客贴
- 3.9
(243)咨询产品免费试用摄图网
- 4.2
(86)咨询产品免费试用



新锐产品推荐
估图-KYC尽调
- 3.0
(1)咨询产品免费试用网达软件-智慧超商系统
- 0.0
(0)咨询产品免费试用网达软件-运营管理系统
- 0.0
(0)咨询产品免费试用噢易云管理平台
- 0.0
(0)咨询产品免费试用噢易云教室系统
- 0.0
(0)咨询产品免费试用潮汐.模拟攻击系统
- 0.0
(0)咨询产品免费试用







