女神照片模糊看不清?CMU用「PixelNN」完美还原马赛克照片
编者按:本文来自微信公众号“机械鸡”(ID:jixieji2017),36氪经授权发布。

其中,YASER AJMAL SHEIKH教授曾带领团队研发出大规模社交互动采集的多视角系统。

CMU的研究人员提出一种简单的近邻分类取样(NN)算法,从“不完全”信号(如低分辨率图像,表面法线图或边缘)合成高清晰度的写实图像。
目前用于这种条件图像合成的、最先进的深度生成模型缺乏两方面:
首先,由于mode collapse问题,它们无法生成大量不同的输出
其次,它们不可解释,难以控制合成输出
我们证明NN方法可能解决这样的限制,但在小数据集上的准确性受到影响。我们设计了一个结合了两种方式的最佳方式:
第一阶段使用卷积神经网络(CNN)将输入映射到(overly-smoothed)图像,并且在第二阶段使用 pixel-wise近邻算法,以可控的方式,将平滑的输出映射到多个高质量的高频输出。
我们展示了我们对各种投喂模型的方法,从人脸到猫和狗到鞋子和手袋的各个领域。
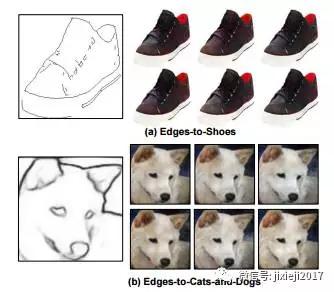
利用GANs测试六种不同质量的图像输出

生成.在第二阶段,我们期待用同样的训练图像匹配similarly-smoothed。重要的是,我们匹配像素使用的多尺度描述符,能捕捉合适的卷积层(例如,眼睛像素往往只匹配眼睛)。


最终输出的傅立叶变换与原始高分辨率图像非常接近



猫狗、鞋包以及人的训练效果
原文链接






大厂都在用的在线作图软件
包图网
- 4.2
(241)咨询产品免费试用稿定设计
- 4.0
(193)咨询产品免费试用fotor懒设计
- 4.1
(49)咨询产品免费试用



限时免费的在线作图软件
千图网
- 4.1
(293)咨询产品免费试用创客贴
- 3.9
(243)咨询产品免费试用摄图网
- 4.2
(86)咨询产品免费试用



新锐产品推荐
maxblox
- 0.0
(0)咨询产品免费试用Built.io Flow
- 0.0
(0)咨询产品免费试用Triggermesh
- 0.0
(0)咨询产品免费试用Cloud Foundry
- 4.2
(20)咨询产品免费试用tsuru
- 0.0
(0)咨询产品免费试用KENV
- 0.0
(0)咨询产品免费试用







