走捷径修Bug却引起全球大宕机,Salesforce哭着处理了“肇事”工程师
编者按:本文来自微信公众号“InfoQ”(ID:infoqchina),作者:核子可乐、Tina,36氪经授权发布。
日前,因某位维护工程师的错误操作,Salesforce 惹上了意外的大麻烦。
几天前,Salesforce 遭遇了一次长达 5 个小时的全球宕机。向外宣布 5 个小时的宕机不是一件容易的事情,特别是让 Salesforce 的 15 万客户受到严重影响的情况下。
这次宕机的起源,是因为一位维护工程师想用一个简单办法规避批准从而快速修复问题,没想到最后引起 Salesforce 的域名系统(DNS 服务器)配置错误,导致人们长时间无法访问该公司的多款核心软件即服务产品。在这段时间内,客户无法稳定登录,甚至服务状态页面也无法正常访问。
而对这位决心绕开既有管理政策、意外肇事的工程师本人,Salesforce 表示“我们已经对这位员工做出了适当处理。”
1 最开始,Salesforce 也搞不明白为何宕机
Salesforce 是目前最受欢迎的云软件应用程序之一。据报道该软件应用程序已被全球大约 150,000 个组织中的数百万名员工使用。Salesforce 提供的服务涉及客户关系管理的各个方面,从普通的联系人管理、产品目录到订单管理、机会管理、销售管理等。用户无需花费大量资金和人力用于记录的维护、储存和管理,所有的记录和数据都储存在 Salesforce.com 上面。
本月 11 日约 21:00(UTC),Salesforce 的服务开始不可用。因为许多公司都使用了 Customer Cloud 来满足用户请求,所以这些客户都受到了影响。有着急的客户被迫拨打 Salesforce 的电话,却得不到应答。自动应答表明他们正处于服务中断中,呼叫者被定向到了在线页面。
Salesforce 的首席技术官和联合创始人帕克·哈里斯(Parker Harris)随后在 Twitter 上发推并暗示该问题与 DNS 有关。
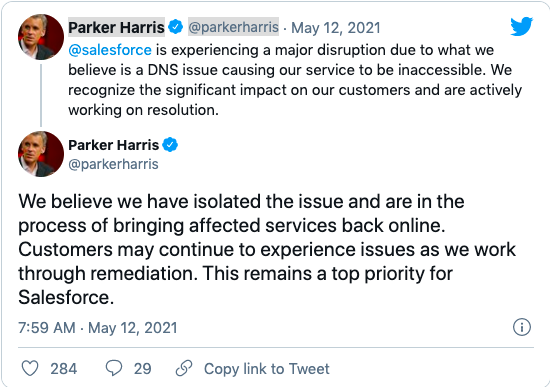
尽管哈里斯(Harris)所表现出来的态度还算乐观,但实际上问题迟迟得不到解决。更不幸的是,因为状态页面一起离线了,他们只能通过社交媒体与客户进行沟通。
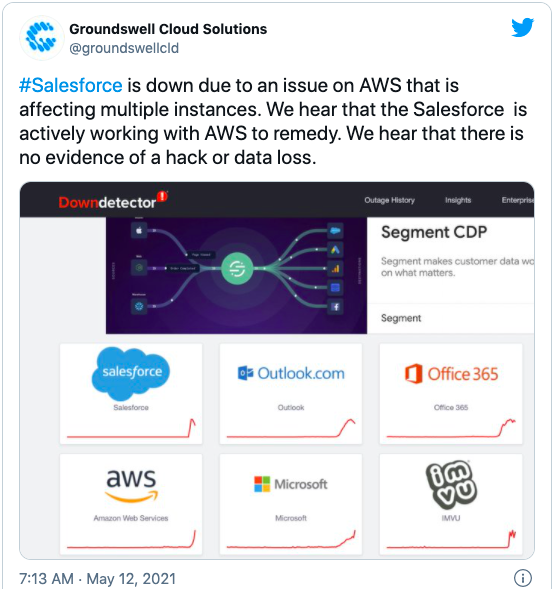
由于这次中断太过异常,因此有人推测这可能是受到网络攻击的结果,尤其是考虑到最近美国燃油网络攻击事件。Salesforce 合作伙伴 Groundswell Cloud 还猜测该故障与 AWS 有关,因为他们认为在此阶段并没有任何受到攻击的迹象。
2 工程师到底做了什么
Salesforce 公司在事件发生后不断更新原因分析进度。几个小时后,公司首席可用性官 Darryn Dieken 组织了一次客户简报会,他在会议上强调,他们还需要一定调整才能全面完成修复。
也正是在这次简报会上,Salesforce 完整披露了事件情况与相关工程师的操作流程。虽然 Salesforce 向来以高度自动化的内部业务流程为傲,但其中不少环节仍然只能手动操作完成——DNS 正是其中之一。当时,一位工程师正打算执行一项配置变更,负责将 DNS 系统对接澳大利亚的一处新 Salesforce Hyperforce 环境。
DNS 变更并不是什么罕见操作,这位工程师使用的配置脚本也拥有着四年的稳定记录。但 Salesforce 一直强调以“交叉”升级方式减小错误的影响半径,因此工程师只能以手动方式缓慢完成这项变更。
但实际情况并不顺利。根据 Dieken 的介绍,这位工程师错误地决定使用所谓“紧急停机修复(EBF)”流程缩短常规变更。而 EBF 实际只适用于发生严重问题,或者需要快速部署大量应急补丁的情况。因此选择 EBF 流程,就意味着走上一条规避批准的非渐进式“捷径”。但这位工程师想得很简单——结合多年的工作经验,再加上这套稳定可靠的脚本,有什么可担心的?
后来的情况大家都清楚了,又是“小丑竟是我自己”的经典场景。
Dieken 补充道,“出于我们也搞不明白的某些原因,这位员工决定执行全局部署。”绕过常规的交叉更新之后,DNS 变更需要各服务器重新启动。
这本身并不是什么大事,也许会带来短暂的中断,但还不至于引发灾难性的后果。但事件证明,这套“稳定可靠”的脚本内存在一个 bug。在实际负载下,此脚本可能发生超时并导致其余内容无法正常运行。事实也正是如此,随着更新在 Salesforce 各数据中心内不断部署,超时点也被不断引爆。这意味着服务器在重新启动后未能正常启动某些任务,导致服务器自身无法正确运行。于是乎,客户当然不能像往常那样顺畅访问 Salesforce 产品。
后来的情况变得更糟。Salesforce 团队决定使用不良服务器处理工具,以“拉下紧急开关”的方式强制执行回滚与设备重启。
Dieken 无奈地表示,“但到这个时候,我们才发现其中的循环依赖关系。这些生产工具的起效前提,正是 DNS 服务器处于活动状态。”“我们才发现其中存在循环依赖关系——这些生产工具的起效前提,正是 DNS 服务器处于活动状态。”
当然,工作人员最终还是成功介入并完成了服务器修复。但事件已经给客户造成了重大影响,Salesforce 也不得不投入大量精力平息由此引发的混乱事态。
为了避免再次发生类似的问题,Salesforce 决定采取保障措施以防止任何手动形式的全局部署操作,并实现整个流程的全面自动化。Dieken 还坦言,事实证明 Salesforce 在测试覆盖率仍然不够完善——换言之,对脚本的测试并不充分。最后,Salesforce 还需要解决恢复工具依赖于 DNS 系统的大问题。
这次宕机事件中,最让客户不爽的是,因为 Salesforce 状态网站一并陷入瘫痪,他们只能在 Salesforce 的社交媒体上跟进官方停机消息。如果状态页面显示不了故障状态,还要它何用?Dieken 解释道,“我们一直备有充裕的容量来应对种种峰值需求,但从来没想到会出现这样的负载情况。”但不必担心,自动规模伸缩已经正式上线,后续情况肯定会有所好转,至少状态查看页面应该不会如此“拉胯”。
至于这位维护工程师,Dieken 虽然之前说到“我们并不打算指责员工本人”,但之后又表示“我们已经对这位员工做出适当处理。”
参考链接:
https://help.salesforce.com/articleView?id=000358392&type=1&mode=1
https://www.theregister.com/2021/05/19/salesforce_root_cause/



私域运营(SCRM)相关的软件
快鲸SCRM
- 4.4
(68)咨询产品免费试用圈量SCRM
- 4.9
(208)咨询产品免费试用咚咚来客
- 4.7
(423)咨询产品免费试用



行业专家共同推荐的软件
尘锋SCRM
- 4.7
(315)咨询产品免费试用慧营销
- 4.6
(143)咨询产品免费试用小裂变SCRM
- 4.4
(165)咨询产品免费试用



限时免费的私域运营(SCRM)软件
探马SCRM
- 4.5
(254)咨询产品免费试用卫瓴·协同CRM
- 4.6
(35)咨询产品免费试用句子互动SCRM
- 4.1
(40)咨询产品免费试用



新锐产品推荐
GTCOM-大数据智能分析
- 0.0
(0)咨询产品免费试用Moran
- 0.0
(0)咨询产品免费试用迅法网
- 0.0
(0)咨询产品免费试用英檬科技
- 0.0
(0)咨询产品免费试用百度智能云-文字识别
- 0.0
(0)咨询产品免费试用极客OCR
- 0.0
(0)咨询产品免费试用







