是什么让你的客户流失?
编者按:本文来自“经纬创投”(ID:matrixpartnerschina) 。36氪经授权转载。
最近这一两年,增长黑客十分流行。
对于创业公司来说,增长非常重要。在流量红利已不明显的今天,对于每一个创业者来说,找到可执行的、有效的增长途径非常重要。
但与此同时,很多人都忽视了对客户流失的管理。
数据显示,获得一个新客户的费用要比留存一个旧客户的成本高七倍。当客户留存率提高5%时,收益可以增加25%到95%。
这些数字相当惊人。由此可见,提高客户留存率是企业最重要的目标之一。流失管理的核心在于能够识别潜在吸引力的预警信号,并采取积极措施来防止它发生。这篇文章介绍了客户流失管理的方法,操作路径以及注意事项,希望能为你带来一些可供借鉴的启发。以下,Enjoy:

让我们来看看从贝恩公司的调查中发现的两个事实:获得一个新客户的费用要比留存一个旧客户的成本高七倍。当客户留存率提高5%时,收益可以增加25%到95%。
这些数字相当惊人。因此,提高客户留存率是企业最重要的目标之一。
从历史上来看,客户流失仅仅被看作一个衡量消费者兴趣的度量标准,企业几乎很难影响这个数值。作为度量标准,客户流失的衡量是反应性的,而不是主动性的。因此,大部分企业过去所能做的就是搞清楚哪些因素可能增加流失量,然后改进这些因素。
如今,情况已经变了。企业能够捕捉丰富的用户的数据,通过复杂的人工智能和数据分析技术进一步利用这些数据,从而更加高效地解决客户流失问题。
现如今大部分公司,尤其是那些B2C领域的公司,对于客户流失问题都设计好了详细的解决措施。因此,全面了解客户流失问题的各个方面非常重要。
什么是客户流失?
客户流失,简单来说就是一段特定时间内失去的客户在总客户数中的占比,总客户数中不包括这段时间内新增的客户。换句话说,这个数据是一个衡量你在留存客户方面你做得有多么成功或者多么糟糕的指标。
在对“失去的客户”的解释上,有一些需要考虑的细微差别。
“绝对”vs“假定”流失:在某些情况下,客户会主动停止与你的关系(比如,一个银行账户持有人关闭了他的账户);也有这样的情况,客户可能已经停止了与你的联系,但是纸面上你们的客户身份并没有改变(比如一位顾客不再去她从前常去的零售商那里买东西)。
不同行业判定流失的时间长度不同:对于电信公司来说,当一个客户已经一个月没再使用该公司的网络服务时可能就要判定他是流失客户了。而对于一个航空公司来说,由于客户使用服务的频率一般都比较低,所以判定客户流失的时间可能要延长到6个月到12个月。
“反应性”vs“预期性”流失:客户流失可以以两种截然不同的方式发生。有时,是特定的不愉快的事件或者经历使客户离开你的公司,这通常被称为‘反应性’流失。例如,信用卡用户可能会因为未预期到的收费,不满意的客服体验或者漫长的争端解决流程等而选择离开。也有的时候,流失是一个渐进的过程,而不是由特定的事件引起的。这就叫做‘预期性’或者‘沉默’流失。显然,这类流失更难被管理。

如何进行客户流失管理?
客户流失管理的核心在于识别潜在流失者发出的预警信号。如果能够及时发现一位客户很可能要离开,那就可以采取主动措施来防止这种情况发生。这时数据分析就可以发挥信息转换的作用。让我们一起来看看这种信息转换在不同方面的作用:
确定已知负面触发事件和它们的影响之间的关系:通过研究负面消费经历的历史数据以及不同类型的消费者作出的反应,我们可以建立起一个模型来预测反应性流失。之后,我们可以利用这个模型,追踪当前消费者所经历的相似触发事件,以确定它们可能会作何反应。从而可以让那些会因为一次或者多次负面经历而流失的消费者走上“恢复”的道路。
(注意:外部触发事件和内部触发事件都是很重要的,即使外部触发事件的数据的获取会更困难。通常,一些竞争者的行为会构成外部触发事件,比如一次因竞争产生的大幅降价,竞争者的客户忠诚度方案的变化,收购驱动等。)
基于过去数据来理解逐渐流失行为:历史数据也可以用来预测非触发性事件驱动的流失。根据对现有用户的360度全方位评估,把他们和历史流失客户进行对比,从而帮助预测出具有高流失风险的客户。换句话说,如果一个客户表现出了与过去逐渐流失的客户相似的行为——包括购买商品类别的减少,购物频率的降低,忠诚度积分兑换行为的减少等,那么他可能就会走上和他们类似的道路。
识别高流失风险客户群:也可以使用类似决策树之类的模型将客户划分为具有不同行为特征的客户群,从而识别具有高流失风险的客户群。举一个电信企业的例子——模型表明,过去一年新加入的,有70%的花费都在数据服务上的用户的流失风险是平均值的十倍。可以挑选出这些群体来作为高风险客户群,并且对他们适当的进行特别对待。

注意误报
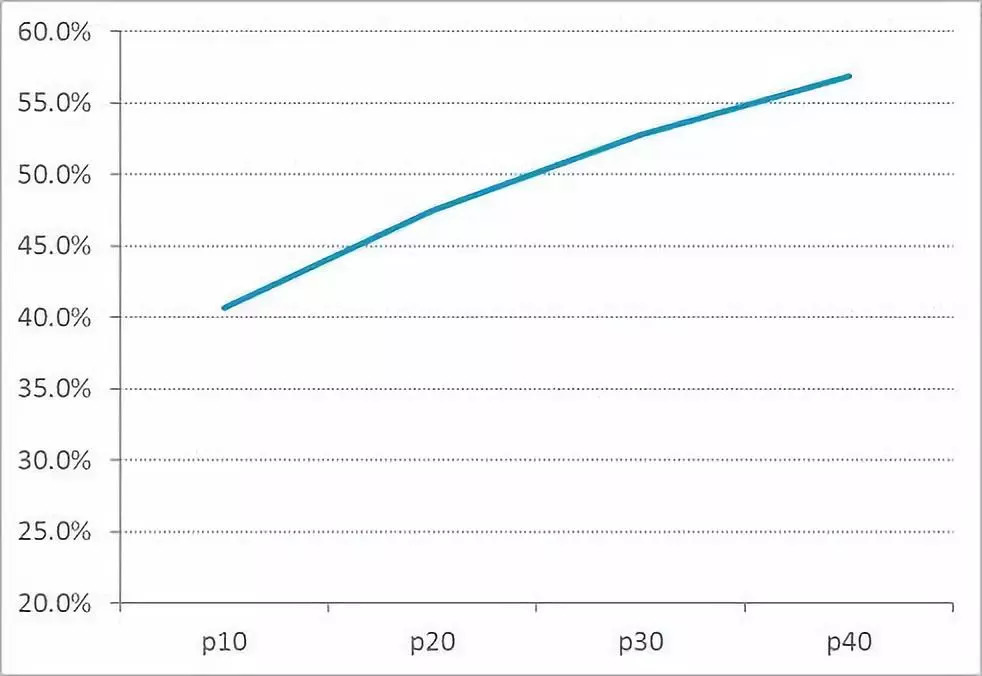
要进行高效的客户流失管理,一个很重要的问题就是流失预测模型误报率很高。因为这些错误的预测,你不得不花费很多钱来试图留住那些从未存在过流失风险的客户。
在对预期性流失的预测中,这种假阳性的预测通常会高于50%。下图中是一条典型的基于逻辑模型进行流失预测的假阳性预测率曲线。
当然,也有一些普遍适用措施来改善假阳性预测率。
首先,可以增加数据点的数量:既要在数据类型上增加(比如,根据用户体验数据和营销活动数据等来丰富交易数据),也要在数据量上增加(比如,数据月份的增加)。
另一个解决假阳性问题的可能措施是利用模型异质性来增强模型的性能。对特定类型的预测选择对应的最有效的模型,然后把他们组合在一起以优化整体性能。
客户流失管理需要哪些数据?
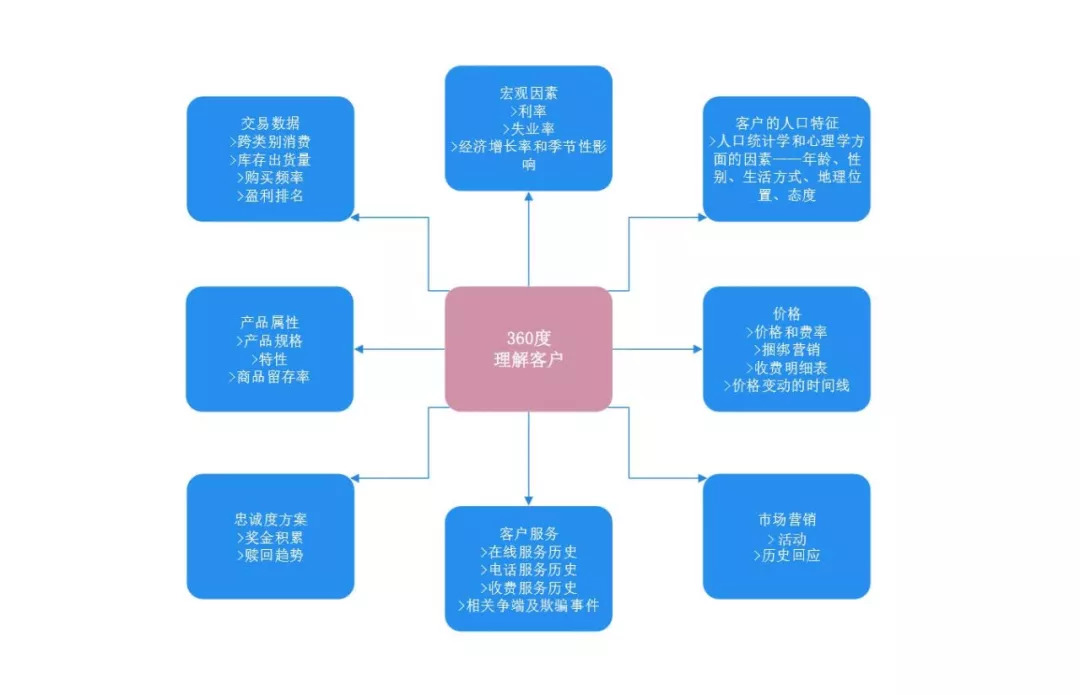
与任何处理客户行为的用例一样,可以利用的数据越多,效果就越好。对客户参与业务的各个方面有一个全方位的认识,可以让你有一个整体性的策略。
下图提供了一些可以协同考虑的关键数据集。
投资回报率这个至关重要的问题
仅仅识别出来有高流失风险的客户是不够的。全面的客户流失管理需要确定出最佳的行动方案,在每一个客户层面上解决流失危机。幸运的是,AI和数据分析在这方面有巨大的价值。有效管理潜在流失者有以下的三个关键步骤:
确定客户吸引力:不同的客户对企业有不同的价值。因此,第一步要做的是确定每一个客户对你的重要性,从而可以将改善费用花在对你有最高终身价值的客户上。
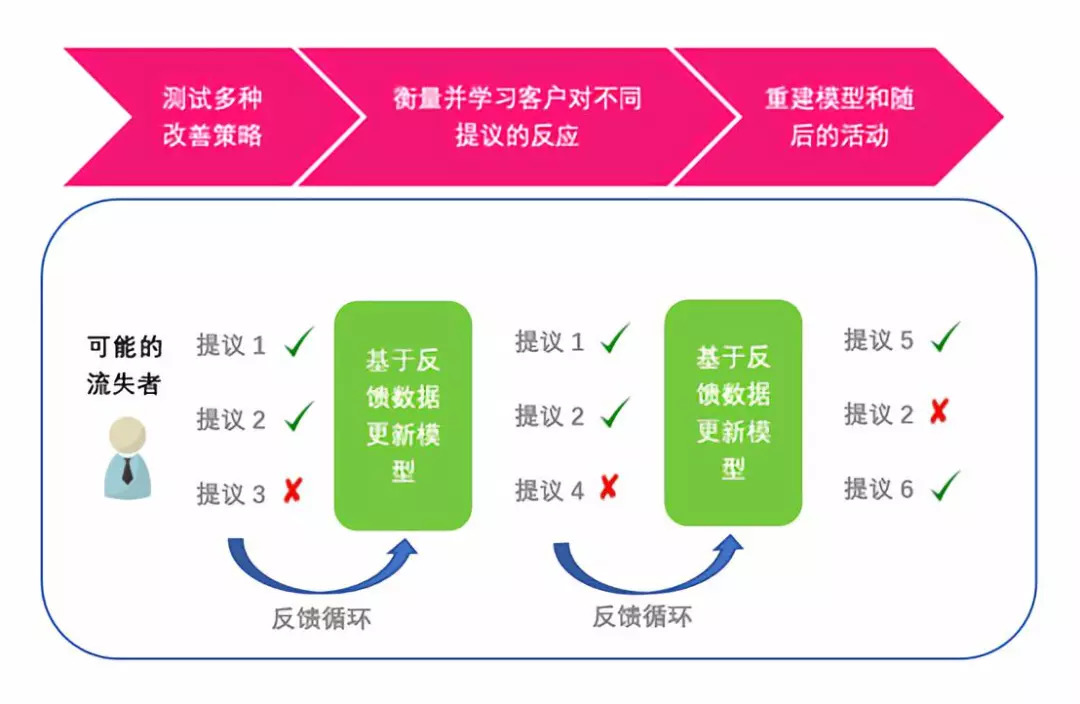
确定用户对改善策略的敏感度:下一步是确定对每一个客户个体最有效的改善策略是什么。改善策略通常由两个因素组成——他们对哪种活动或者干预做出最佳反应?以及他们最佳回应的沟通渠道是什么?
测试并学习反馈循环:最后,即使你已经搞清了所有具有流失风险的客户中对你最有价值是哪些,以及可能重新吸引他们的最有效策略是什么,但有一个灵活的操作流程也是至关重要的,因为这能让你快速地从你的提议和他们的反馈中学习并改善。这种反馈循环可以不断地调整模型来提高模型性能。
识别和恢复有流失风险的客户能够带来巨大的商业利益。因此,人们开发了一系列的解决方案。
有一些现成的流失预测工具可以让企业以自助的方式操作。这种工具主要的问题通常来自于这些模型的有效性,因为它们在很大程度上依赖于一刀切、千篇一律的方法。
而与此相对的另一种极端是,企业可以选择构建内部专用的数据科学功能部分,以便在包括客户流失在内的多种情况中使用。这通常需要大量的前期和持续投资,不是对所有企业都是可行的。通常也会有更长的上市时间。
位于这两个极端中间的解决方案,将世界一流的外部专业知识与内部业务知识结合在一起,通常是解决流失问题的最有效方法。
题图及内文图片均来自pexels.com,图片授权基于:CC0协议。



私域运营(SCRM)相关的软件
快鲸SCRM
- 4.4
(68)咨询产品免费试用圈量SCRM
- 4.9
(208)咨询产品免费试用咚咚来客
- 4.7
(423)咨询产品免费试用



大厂都在用的私域运营(SCRM)软件
尘锋SCRM
- 4.7
(315)咨询产品免费试用慧营销
- 4.6
(143)咨询产品免费试用小裂变SCRM
- 4.4
(165)咨询产品免费试用



限时免费的私域运营(SCRM)软件
探马SCRM
- 4.5
(254)咨询产品免费试用卫瓴·协同CRM
- 4.6
(35)咨询产品免费试用句子互动SCRM
- 4.1
(40)咨询产品免费试用



新锐产品推荐
爱快
- 0.0
(0)咨询产品免费试用奥琦玮
- 0.0
(0)咨询产品免费试用刻度嘟嘟-运营辅助系统
- 0.0
(0)咨询产品免费试用康总管
- 3.9
(8)咨询产品免费试用寄云NeuSeerDA
- 0.0
(0)咨询产品免费试用万维广告
- 0.0
(0)咨询产品免费试用