微软麻将 AI 论文发布,首次公开技术细节
编者按:本文来自微信公众号“HyperAI超神经”(ID:HyperAI),作者:神经小兮,36氪经授权发布。
场景描述:还记得去年 8 月微软发布的「雀神AI」Suphx 吗?今天,该研究团队在 arXiv 上发布了更新版的论文,进一步介绍了 Suphx 背后的技术。
关键词:麻将 AI, Suphx,卷积神经网络
2019 年 8 月 29 日,微软发布了一个名为 Suphx(超级凤凰)的「麻将 AI」,在专业的麻将竞技平台上,Suphx 的实力胜过了顶级人类选手的平均水平。
当时一经发布,Suphx 便引起了广泛的关注,不仅是人工智能领域,不少麻将爱好者也都赶来围观讨论。(可点击此文回顾《一家胡三家的人工智能来了》)
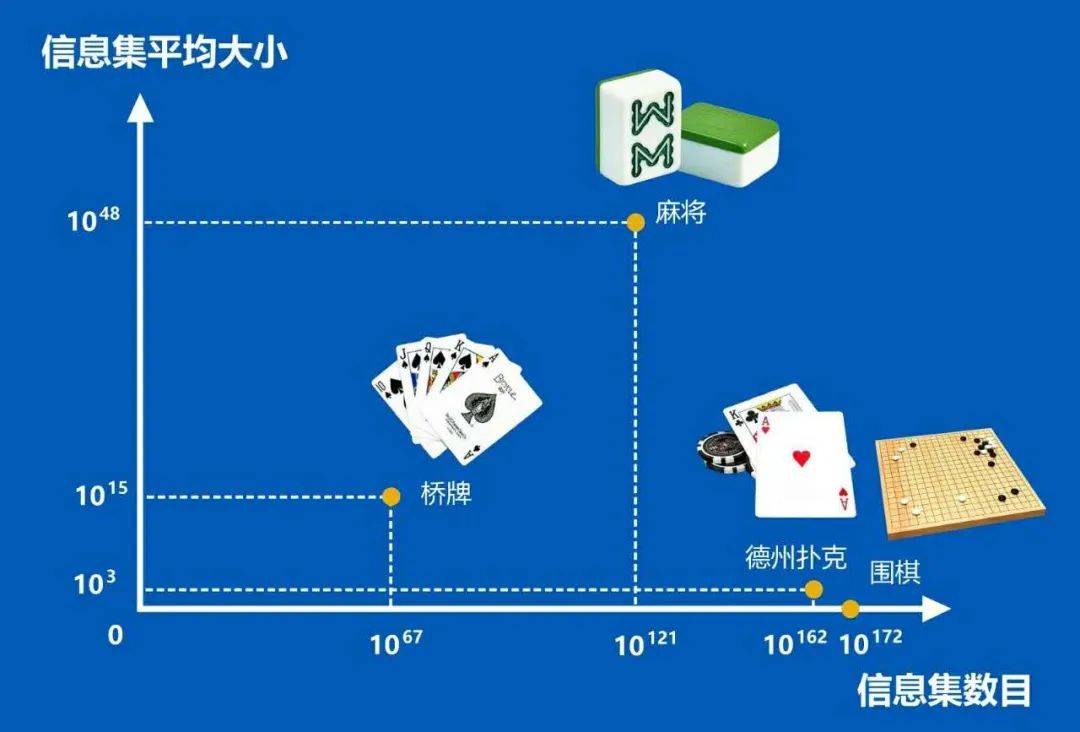
麻将的信息集数目和信息集平均大小
超过了桥牌、德扑和围棋
人们评价该系统比战胜了职业围棋手的 AlphaGo 更复杂,被誉为「最强日麻人工智能」。
今天,该系统的研发团队在 arXiv 上发表了论文《Suphx: Mastering Mahjong with Deep Reinforcement Learning》(《Suphx:掌握麻将与深度强化学习》),更深一步地讲解了 Suphx 背后的技术。

《Suphx:掌握麻将与深度强化学习》
论文地址:https://arxiv.org/pdf/2003.13590.pdf
Suphx 愈战愈勇:已超越 99.99% 玩家
此前我们已经介绍过,Suphx 系统利用深度强化学习,从 5000 场比赛中学习、吸取经验之后,在日本专业的麻将竞技平台「天凤」上击败了众多麻将玩家,取得平台「特上房」的最高段位十段。
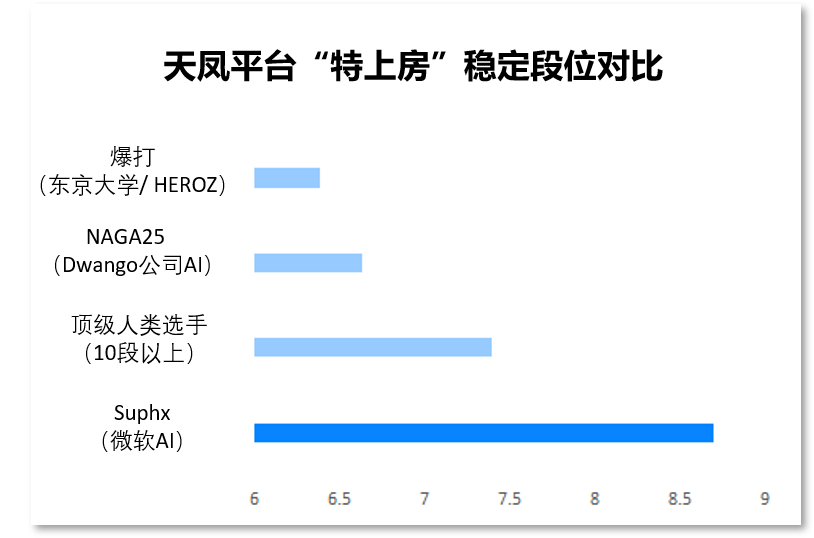
Suphx 在天凤平台的段位,远高于其它麻将 AI
这样一个强悍的麻将 AI,究竟是如何打造的?来自微软亚洲研究院、京都大学、中国科学技术大学、清华大学以及南开大学的研究团队,在最新版的论文中,进行了深入的介绍。
从论文中,我们也得知,Suphx 在进一步的学习下,水平也更进一步。在拥有超过 35 万位玩家的「天凤」平台上,被官方评为水平超越 99.99% 以上玩家,这是计算机程序首次超过麻将中大多数顶级人类玩家。
五大模型与强化学习,造就雀神 AI
Suphx 包含一系列卷积神经网络,它学习了五种模型来处理不同的场景,包括 discard(丢弃模型)、Riichi 模型、chow 模型、Pong 模型和 Kong 模型。
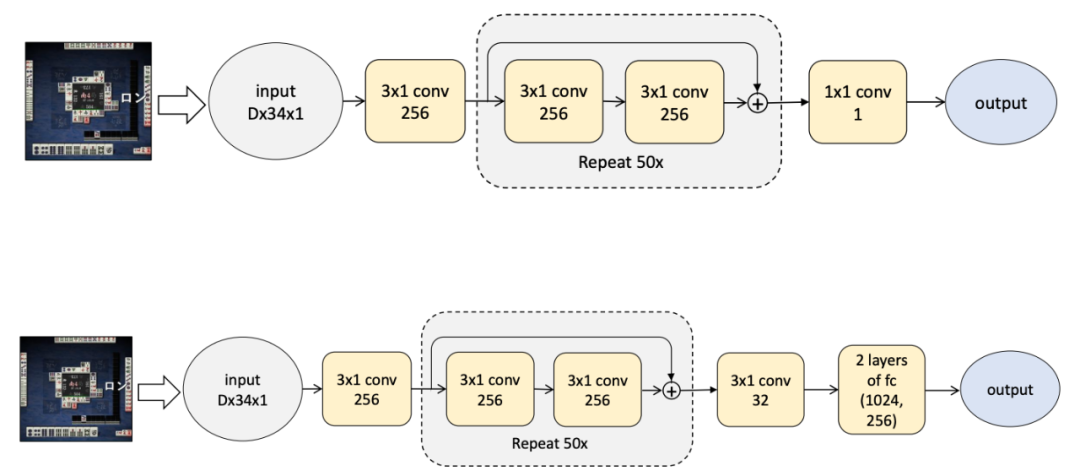
discard 模型(上)与其它四个模型的架构(下)
在此基础上,Suphx 采用另一种基于规则的模型,来决定是否宣布赢家并进行下一轮,检查是否赢牌可以从其他玩家丢弃的牌中来判断,或者从排墙上抽出来的牌来判断。
据介绍,Suphx 的训练过程一共分为三步。
首先,它的 5 个模型都使用从「天凤」平台收集的顶级人类玩家的日志进行训练。
然后,使用包含一套基于CPU 的麻将模拟器和基于 GPU 的轨迹生成推理引擎,通过自我博弈强化学习对系统进行微调。
最后,在在线游戏期间,使用运行时策略调整被用来观察当前轮的结果,从而使系统执行得更好。
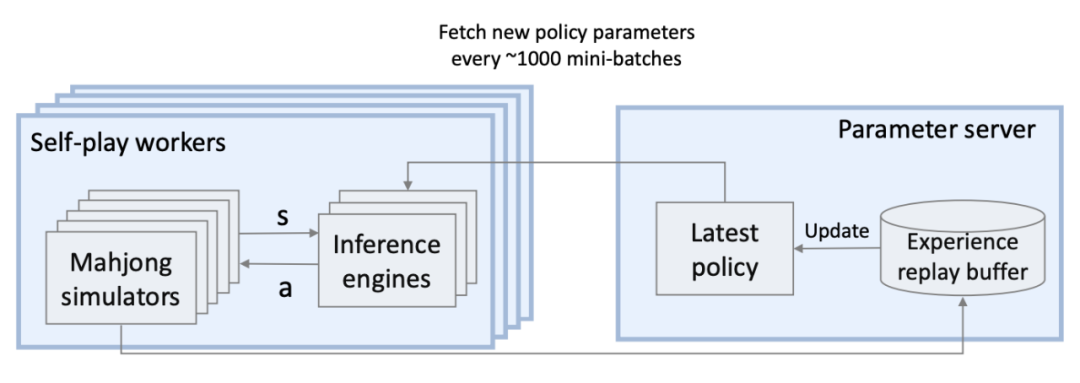
Suphx 中的分布式强化学习系统
由于麻将牌局中,对手的信息都是未知的,因此,Suphx 尝试了先知教练技术来提升强化学习的效果。在自我博弈的训练阶段,利用隐藏信息引导模型训练方向 ,从而增强 AI 模型对可见信息的理解,并找到有效的决策依据。
评估 :5760 场角逐,创造十段纪录
在实验之前,团队在 44 个 GPU (包括4个 Nvidia Titan XPs 用于参数服务器,40 个 K80s 用于自我博弈玩家)上,使用 150 万次牌局,对每个模型进行了为期两天的训练。
该团队对 20 个 Nvidia Tesla K80 GPU 上的 Suphx 进行了评估。为了减小稳定排名的方差,他们从 100 多万场的麻将牌局数据集中,随机抽取了 80 万牌局的数据,并从中进行了 1000 次取样。
评估结果为,在「天凤」平台与人类玩家进行了超过 5760 场比赛后,Suphx 创造了十段的纪录——大约只有 180 个玩家曾经达到过这个水平。而 Suphx 稳定的排名是 8.74 段(人类玩家最高水平是 7.4 段)。
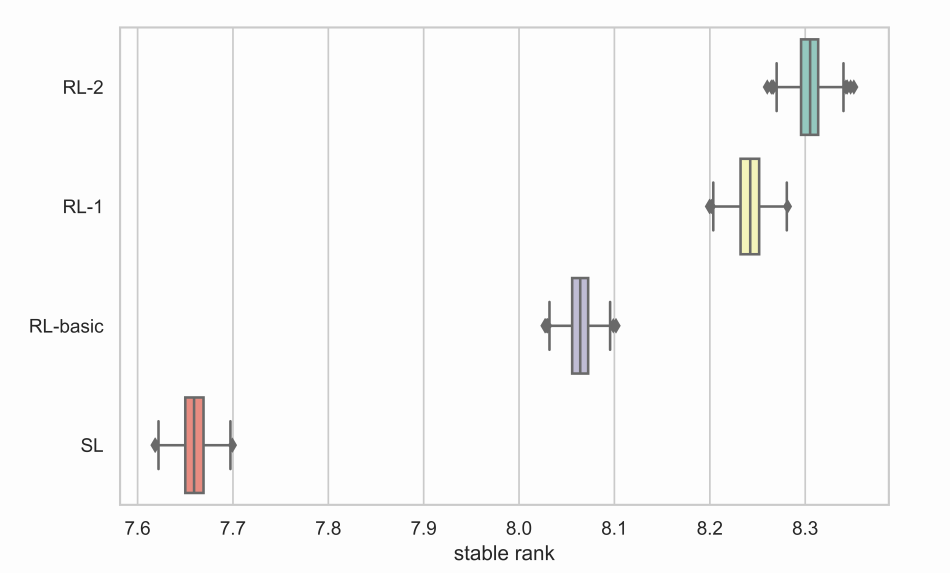
强化学习 agent 最终稳定排名统计
在不断优化中,RL-2 最终取得更好的表现
有趣的是,研究人员写道,Suphx 的防守「非常强」,放胡的概率很低,只有 10.06%,而且它开发了自己的游戏风格,可以保证牌的安全,并以半平手取胜。
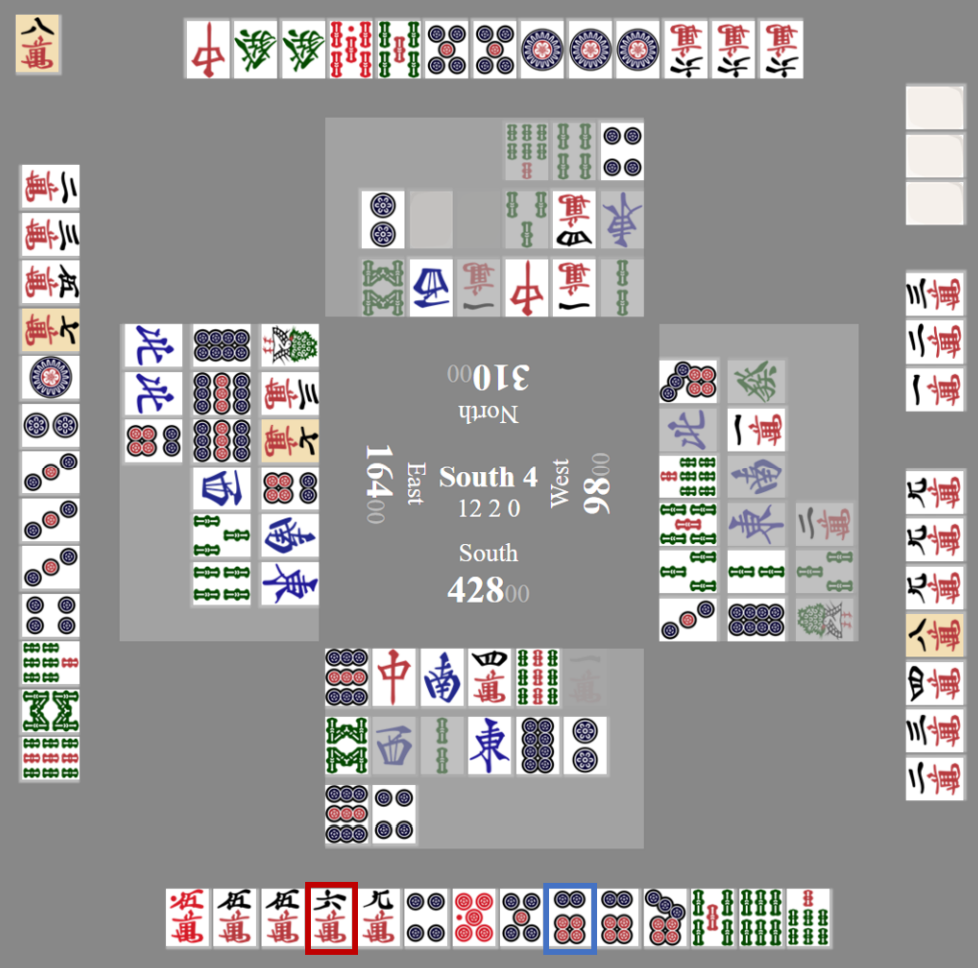
AI 玩家(南方)会选择保守打法
放弃篮筐内的六筒,因为牌桌上已有该牌
此外,论文的合著者写道,大多数现实世界的问题,如金融市场预测和物流优化与麻将有相同的特点。比如复杂的操作/奖励规则、非完美信息问题等等。
作者相信,在 Suphx 中设计的麻将技术,包括全局奖励预测、先知引导以及政策调整等,都有巨大的潜力,将来可广泛应用于现实世界,帮助解决真实而复杂的实际问题。

看到这里,你也跃跃欲试了吗?天凤麻将对战平台:https://tenhou.net/, 一起来一局呀!



私域运营(SCRM)相关的软件
快鲸SCRM
- 4.4
(68)咨询产品免费试用圈量SCRM
- 4.9
(208)咨询产品免费试用咚咚来客
- 4.7
(423)咨询产品免费试用



行业专家共同推荐的软件
尘锋SCRM
- 4.7
(315)咨询产品免费试用慧营销
- 4.6
(143)咨询产品免费试用小裂变SCRM
- 4.4
(165)咨询产品免费试用



限时免费的私域运营(SCRM)软件
探马SCRM
- 4.5
(254)咨询产品免费试用卫瓴·协同CRM
- 4.6
(35)咨询产品免费试用句子互动SCRM
- 4.1
(40)咨询产品免费试用



新锐产品推荐
盈鱼MA
- 0.0
(0)咨询产品免费试用神州云动-办公云
- 0.0
(0)咨询产品免费试用慧人力智能人事
- 4.4
(14)咨询产品免费试用茧数科技-短链接
- 0.0
(0)咨询产品免费试用腾讯企点营销
- 3.2
(2)咨询产品免费试用深澜软件-IDevM 智能设备认证接入管理系统
- 0.0
(0)咨询产品免费试用







