亚马逊、GitHub、Reddit 等全球性网站无法登陆,带火了一家云计算公司
编者按:本文来自微信公众号“AI前线”(ID:ai-front),整理:施尧,36氪经授权发布。
北京时间 6 月 8 日晚,据外媒报道,包括亚马逊、Reddit、Twitch、GitHub、eBay、Etsy、Pinterest 和 Stack Overflow 在内的多家全球性网站出现故障。其中影响最严重的是美国和欧洲的新闻媒体网站,例如《纽约时报》《卫报》《金融时报》《美国有线电视新闻网》《世界报》《纽约杂志》《纽约客》等。
图片来源:rt.com
社交媒体方面,除了 Twitter 的表情包无法使用外,社交媒体网站相关功能并未受到影响。但由于受影响的网站平日承载的流量巨大,全球各地的人们开始在社交媒体上热议此事,都想知道究竟发生了什么。
事发原因找到了,系云服务商 Fastly 出故障
从社交媒体的反应来看,包括美国、英国、澳大利亚等来自世界各地的人们都报告了网站服务中断的消息,表明这是一个全球性的事件。
据彭博社消息,此次事件是由于美国云计算服务商 Fastly 当天发生了技术故障,从而引发的大规模网站无法解析问题。
Fastly 是美国一家基础设施软件和服务提供商,其主要业务是为企业提供内容分发服务,帮助终端用户并更加快速地获取、访问内容。
当天 9 时 58 分开始,Fastly 网站即进入问题诊断状态,其后多次更新时间状态。到 12 时 41 分,最新消息显示其已解决此问题,随着全球服务的回归,客户会遇到一段时间的负载增加,也就意味着网页(初次)加载缓慢。可以看到,从网站进入问题诊断状态到最终宣布问题解决,Fastly 花了接近 3 小时。
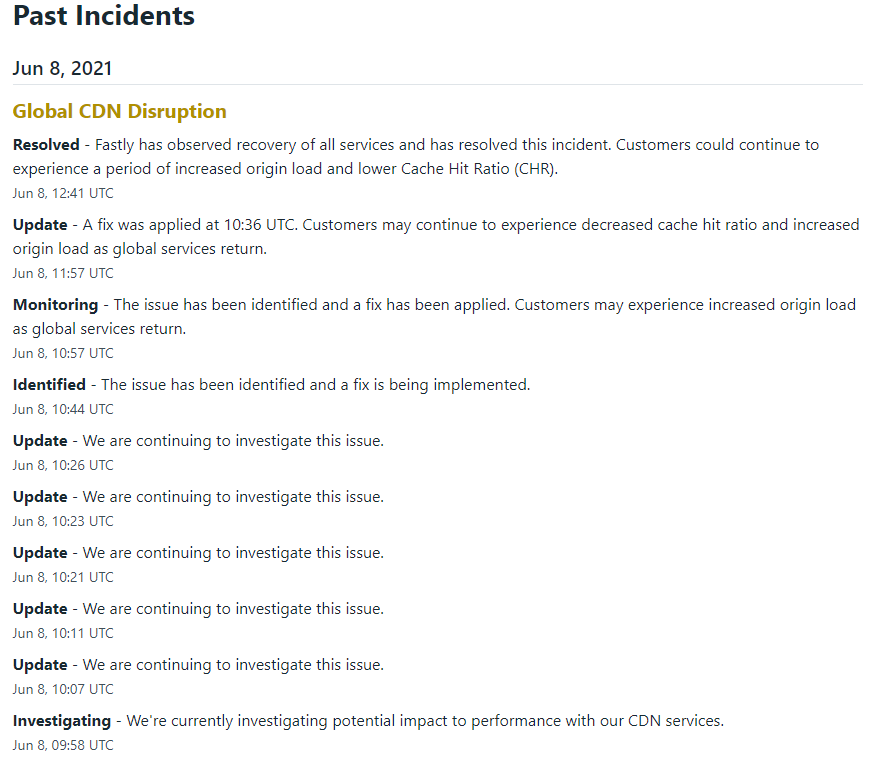
图片来源:nbd.com
当前,受影响的英美媒体网站以及 Amazon、Reddit 等网站已经陆续恢复正常服务,Twitter 表情包也已经能够正常使用。而对于此事件,暂未有媒体报道黑客攻击的相关消息。
云厂商宕机常有,4 个 9 的安全性是否靠谱?
云厂商宕机故障,这些年一直不是什么新闻。
2019 年,3 月 2 日,阿里云疑似出现大规模故障情况,华北众多互联网公司发现服务器异常。当天晚些时候,阿里云回应称:华北 2 地域可用区 C 部分 ECS 实例状态异常,导致该区域众多网站和 APP 都无法正常使用。
2018 年 6 月 27 日,阿里云也曾出现重大技术故障,当天 16:50 分开始陆续恢复,官方给出的故障时间为 30 分钟左右,恢复时间大概花费一小时。经过技术复盘,阿里给出的故障原因为工程师团队上线自动化运维新功能时,执行了一项变更验证操作,该操作在测试环境中未发生问题,上线后触发未知 bug。
2017 年 2 月 28 日,云计算巨头 AWS S3 故障,事件的起因是 AWS S3(云存储)团队在进行调试时输入了一条错误指令,本应该将少部分的 S3 计费流程服务器移除,可是最终意外移除了大量服务器。被错误移除的服务其中运行着两套 S3 的子系统,从而导致 S3 不能正常工作,S3 API 处于不可用状态。
2017 年 3 月 22 日,微软云服务又一次出现宕机。Outlook、 Hotmail、 OneDrive、 Skype 和 Xbox Live 都出现了网络故障,全球用户都无法登录。
根据笔者统计,仅去年一年,全球主流云计算厂商就曾发生数十起宕机事故,众多安全事故频发,云厂商承诺的 99.99% 的安全可靠性是如何定义的?
熟悉云计算的读者都知道,业界常用 3 个 9、4 个 9,来计算每年的服务故障时间。头部互联网公司对他们的关键服务,通常提出的承诺是 4 个 9,也就是每年最多故障 53 分钟。
不久前,笔者曾就云服务的可靠性一事询问相关技术专家的看法,他表示,云计算厂商得出 99.99% 可靠性这一数字是经过验证的,通过客户部署反馈,确实故障率在 0.01% 以下。并且,一旦出现故障,云厂商也都有非常完善的容灾方案,目前主流云厂商已经在提供一定程度上的异构灾备能力,用户也可以自己搭建跨 DC 方案,技术上能够满足异构容灾需求。
如果客户追求极致容灾能力,有可能建设混合云或者采购多家云厂商,这就会带来很大的成本压力,但这种选择应该比较少,就好比对安全可靠性要求极高的金融数据库领域,也很少有客户同时选择两种数据库方案。
由此可以看出,对于安全性的衡量,不论是 3 个 9 还是 4 个 9 的安全性承诺,其实都需要云服务商的客户有一定的宕机容忍度。而且在具体出问题时,修复时间的长短还得就事论事。也就是说,云服务商承诺的安全性只是一个经过测试认证的达标值,并不是每次服务的水平下限。
但其实,相比上云,如今众多企业自己拥有服务器的成本会更高,并且安全性不如云服务商提供的服务来的优质。因此,对很多企业来说,上云与否已经不再是问题,而是如何选择更适合自身的云上服务 / 解决方案。






行业专家共同推荐的软件
SUSE Linux Enterprise Server
- 4.1
(40)咨询产品免费试用Teradata Vantage
- 5.0
(1)咨询产品免费试用华胜天成
- 4.0
(1)咨询产品免费试用



限时免费的云计算软件
云站中国
- 3.8
(3)咨询产品免费试用华为云-云计算
- 0.0
(0)咨询产品免费试用青云QingCloud
- 0.0
(0)咨询产品免费试用



新锐产品推荐
chinaZ站长工具
- 3.2
(14)咨询产品免费试用中企动力
- 3.9
(5)咨询产品免费试用斗鱼营销平台
- 3.7
(4)咨询产品免费试用爱站网站长工具
- 0.0
(0)咨询产品免费试用Alexa排名优化工具
- 3.9
(20)咨询产品免费试用小红书蒲公英
- 0.0
(0)咨询产品免费试用







