微软HoloLens技术解谜(上):如何还原三维场景
本文作者张静是前微软上海Xbox ATG软件工程师,微信公众号“黑客与画家”(HackerAndPainter),欢迎各位童鞋与他交流探讨。
HoloLens 是什么?
HoloLens 是微软发布的可穿戴式增强现实计算设备,它拥有这么几个关键要素:
它是增强现实产品,即 Augmented Reality(AR),AR 技术将计算机生成的图像与真实的世界相叠加。类似的产品有图像投射到视网膜上的 Google Glass,以及叠加在手机摄像头画面上的手机 AR 应用。
它拥有是独立的计算单元,自带 CPU + GPU +HPU,不需要外接计算机。它的 CPU 和 GPU 基于英特尔的 14纳米工艺的 Cherry Trail 芯片,HPU 是微软发明的缩写,全称是 Holographic Processing Unit,即全息处理单元。按照知乎匿名用户的回答,HPU 是一块 ASIC(Application-specific integrated circuit),是微软为 HoloLens定制的集成电路,对此,我只能说“有钱任性”。
HoloLens 不是什么?

看完微软栩栩如生的宣传视频后,如果你的反应是
卧槽,Matrix 要来了。
那么你要好好看这一段,因为 Matrix 是 Virtual Reality / VR / 虚拟现实,VR 的特点是让参与者置身于计算机生成的三维图像世界中,淡化真实的世界。VR 近期的代表产品是 Oculus Rift,戴上 Rift 后你是看不到真实世界的。在我看来 VR 最大的问题是:这个虚拟世界很真实很精彩,但是有什么用呢?也就是说 VR 只能做到更逼真的三维世界,它无法帮助人们更好地理解真实的世界。

HoloLens 也不是 Google Glass(以下简称GG),它比 GG 多了:
三维感知能力,可以对身边的三维场景进行建模。而 GG 只能看到 RGB 像素值。
三维渲染能力。
人机交互能力,可以用手势来进行控制。
HoloLens 也不是市场上常见的的 AR,常见的基于摄像头的 AR 应用基于摄像头有:
基于丑陋的黑白标记图片的 AR

以及基于任意图片的 AR。

很炫是吗,但是它们只能检测到图片所在的那个平面。HoloLens 比它们都牛,它能检测到各个角度的三维场景!
HoloLens 的 AR 是如何得到三维场景深度信息的?
我们回到 AR 的定义,想要实现增强现实,必须先理解现实,那么对于 HoloLens 而言现实是什么呢?是传感器的数据。
传感器是啥?是摄像头。
同样是摄像头,为什么 HoloLens 就可以感知深度呢?微软的 Kinect 在这方面很成功,那么是不是 HoloLens 上放了一台嵌入式的 Kinect 呢?
答案在下面的原型图片中:

HoloLens 拥有有四台摄像头,左右两边各两台。通过对这四台摄像头的实时画面进行分析,HoloLens 可覆盖的水平视角和垂直视角都达到 120 度。
也就是说它采用的是立体视觉 / Stereo Vision 技术来获取类似下图的深度图 (depth map)。

立体视觉是计算机视觉学科的一个子学科,专注于从两个摄像头的图像数据中得到真实场景中的物体离摄像头的距离。示意图如下:
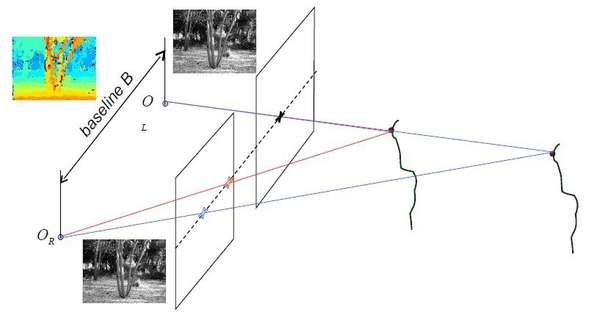
下面是基本的步骤,查阅 OpenCV 文档可以了解具体到函数用法 :
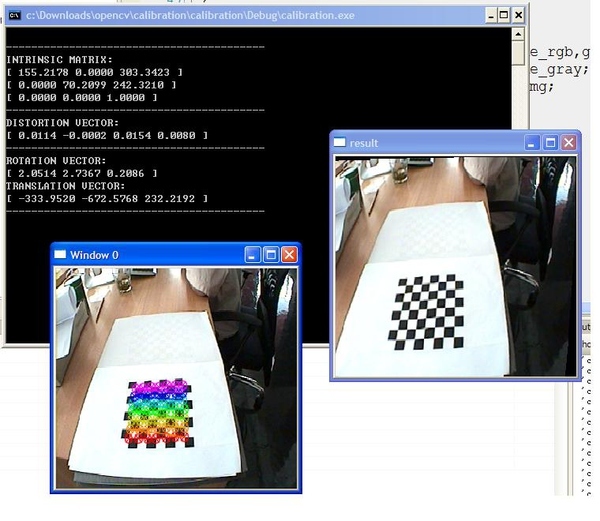
摄像头校正,undistortion。由于摄像头的镜片出厂时都存在扭曲,为了得到精确的数据需要在使用前进行较正。常用的方法是基于棋盘的各个姿态拍几次,然后计算相机的矩阵参赛。下图便是常见的标定界面。
图像对齐,rectification。因为两个摄像头的位置不同,因此它们各自看到的场景是有偏差的,左边的摄像头能看到最左的场景,右边的看到最右的场景。图像对齐的目的是得到相同的场景部分。
左右图像匹配,correspondence。可以使用 OpenCV ,得到 disparity map。
通过重映射函数,比如 OpenCV 中的 cv::reprojectImageTo3D,得到一张深度图。
只有一张深度图是不够的,它只是某一时刻真实的场景在摄像头中的映射。要想得到完整的三维场景,我们需要分析一系列的深度图。
HoloLens 如何从多张深度图重建三维场景?
答案是 SLAM,Simultaneous Localization And Mapping,即同步定位与建图系统。这个技术被用于机器人、无人汽车、无人飞行器的定位与寻路系统。解决的是非常哲学的问题:
我现在在哪里?
我可以去哪里?
SLAM 有很多实现的方式,有一个开源的方式,实现了很多深度图的处理和匹配算法,可以认为是三维版本的 OpenCV。
而微软围绕着 Kinect 的深度图数据发明了 Kinect Fushion 算法,并发表了两篇论文:
KinectFusion: Real-time 3D Reconstruction and Interaction Using a Moving Depth Camera;
KinectFusion: Real-Time Dense Surface Mapping and Tracking。
为什么我认为 HoloLens 与 Kinect Fushion 有关?答案在这个页面中 。 Shahram Izadi 是微软剑桥研究院的 principal researcher 及 research manager。他所领导的互动3D技术组 / interactive 3D technologies 为微软的多项产品提供了研究力量,包括 Kinect for Windows, Kinect Fusion 以及 HoloLens。顺便说一句,他们组在招人:)
Kinect Fushion,通过在室内移动 Kinect 设备,获取不同角度的深度图,实时迭代,对不同对深度图进行累积,计算出精确的房间以及房间内物体的三维模型。
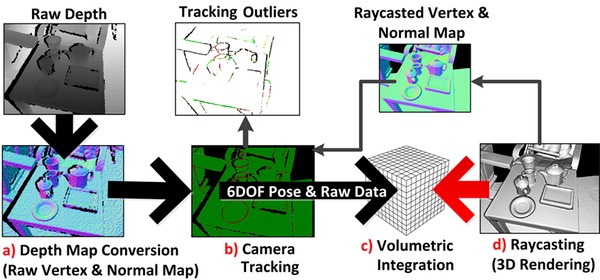
它分四个阶段:
深度图格式转换,转化后的深度的单位是米,用浮点数保存。并计算顶点坐标和表面的法向量。
计算世界坐标系下的相机姿态(包含位置和朝向),通过迭代的对齐算法跟踪这两个值,这样系统总是知道当前的相机与最初的姿态相比变了多少。
第三阶段将姿态已知情况下的深度数据融合到单个三维乐高空间里,你也可以叫它为 MineCraft 空间,因为这个空间的基本元素不是三角形,而是方格子。演示视频中频频出现 MineCraft 场景估计也和这个阶段有关。
基于 Raycasting 的三维渲染,Raycasting 需要从当前的相机位置发出射线,与三维空间求交集。乐高空间特别适合Raycasting,可以用八叉树来加速射线的求交运算。Raycasting、Raytracing 以及 Rasterization 是三种常见的渲染方式,这里就不展开了。
在 HoloLens 的应用中我们运行到第三步,即获取三维乐高模型就可以了,第四步并不是必需的。因为 HoloLens 的屏幕是透明的,不需要再把房屋的模型渲染一遍,我们自带的眼睛已经渲染了一遍了:)
HoloLens 炫酷的 demo 都是怎么制作的?
还剩下三个难点,留待后续文章叙说:
手势识别怎么做的?
眼球跟踪怎么做的?
非常贴合的三维渲染是怎么做的?


文档编辑工具相关的软件
永中Web Office在线编辑
- 4.7
(14)咨询产品免费试用石墨文档
- 4.0
(89)咨询产品免费试用MindMaster
- 3.7
(64)咨询产品免费试用



大厂都在用的文档编辑工具软件
伙伴云表格
- 4.6
(35)咨询产品免费试用够快云库
- 4.2
(17)咨询产品免费试用金山文档
- 4.0
(84)咨询产品免费试用



限时免费的文档编辑工具软件
伙伴云分析
- 4.8
(17)咨询产品免费试用万兴PDF
- 4.7
(3)咨询产品免费试用金山数字办公平台
- 4.6
(2)咨询产品免费试用



新锐产品推荐
极联软件-银行投融资撮合系统
- 0.0
(0)咨询产品免费试用易赏营销自动化
- 0.0
(0)咨询产品免费试用易赏SCRM
- 0.0
(0)咨询产品免费试用pscloud营销自动化
- 0.0
(0)咨询产品免费试用同鑫eHR
- 3.9
(7)咨询产品免费试用璐华企业eHR系统
- 3.9
(8)咨询产品免费试用







