俄勒冈州立大学研发脱口秀机器人,全美巡演数十场获好评
编者按:本文来自微信公众号“HyperAI超神经”(ID:HyperAI),作者 神经小兮,36氪经授权发布。
场景描述:俄勒冈州立大学的学者一直在研究,如何让机器人掌握幽默感,并学会更好地进行脱口秀表演。为此,团队带着脱口秀机器人 Jon 进行了数十场表演,并总结出了一些成功窍门。
关键词:机器人脱口秀 人机交互 幽默感
在我们传统印象中的机器人,大多数是冷酷的金属质感,即使是 Siri 一类语音助手,虽然没有实体形象,冷冰冰的声音也传递着一种机器人气质。
有句话说,「等到人机交互与人类交流一样自然时,真正的智能时代就来了。」
在人机交互方向上,科学家和工程师们一直在努力,也希望机器人、AI 可以获得幽默感,以更好地与人类相处,毕竟幽默感,是人类最宝贵的特质之一。
比如 Siri、微软小冰,都在努力学习讲好(leng)笑话。
让机器人讲笑话:提升人机交互的好办法
想让机器人或者语音助手 AI ,拥有幽默感并不容易,甚至被认为是领域内的终极难题。
(我们之前已经讨论过 AI 拥有幽默感的问题,详见《让人工智能学会幽默,人机对话不尴尬》。)
2019 年 5 月,一个叫做「泰坦」的机器人登上脱口秀节目《笑傲江湖》的舞台。自称是来搞笑的它,段子频出,逗得台下观众捧腹大笑。
这位「泰坦」机器人有问必答,还是个话痨
但是「泰坦」在动作和语言互动上过于真实的表现,反而引起了观众的质疑。而之后也证实,它确实只是一个机器人外壳,里面藏着一个真人来操控它的动作和表演。
社交机器人发展至今,它的交互性、对人类情绪的理解,一直以来都十分具有挑战性,像「泰坦」可能有一定配合节目需要的成分,这样收放自如、超能接梗的机器人,在现实中还很难做到。
俄勒冈州立大学有一支研究团队,从 2011 年开始,就致力于人机交互、机器人幽默感的研究。为了解决这个难题,让社交机器人用幽默感更好地吸引人们、更像人类,机器人学助理教授 Naomi Fitter 打算从打造脱口秀机器人入手。
团队首先选择了软银机器人开发的 NAO 机器人,作为载体和表演者,运行他们研发的脱口秀表演程序。
至今,Naomi Fitter 带着她的脱口秀机器人 Jon 进行了 32 场西海岸巡回演出,发现了机器人如何逐步理解和学习人类的幽默感。

Naomi Fitter 认为娱乐机器人技术 能够为科学交流提供好机会
32 场表演,不断提升的演出技巧
我们知道,脱口秀一般由「开场白-抖包袱」组成,而除了笑话内容外,讲笑话的语速,以及开场白和抖包袱之间的停顿时间,对于脱口秀表演也是至关重要的。
由于现阶段研究方向,是让机器人与人类的幽默互动更加自然,而不在于笑话自动生成。所以,研究人员遵循脱口秀的一般套路,为 Jon 预先撰写了适合机器人的表演素材。
这些素材都是从机器人的角度出发,主题包括人际关系、日常生活、政治、梦想和挫败感。
比如:最近我侄子问我「机器人来自哪里」的时候我总是很尴尬,我只能告诉它,机器人来自它的妈妈——快递的卡车。
Jon 在表演时通过收音判断现场观众的反应,来决定下一个梗是否需要停顿,还是需要加强语气。
俄勒冈州立大学团队剪辑的脱口秀表演花絮
研究人员撰写了大约 8 分钟的素材,包括 26 个笑话,22 个情感标签。然后使用 NAO 机器人作为表演者,来运行其喜剧表演的程序。

表演过程中通过机器人的麦克风来收集表演记录并评估观众的反应
机器人 Jon 在两个开放麦的表演共 32 场,分别在洛杉矶地区和俄勒冈州两个开放麦场地进行。
第一项研究:停顿技巧为表演加分
第一项研究在洛杉矶地区进行,共包括 22 场表演,现场有 10 -20 名成年观众,他们之前并未看过机器人脱口秀。
机器人分别进行了两种模式的表演。
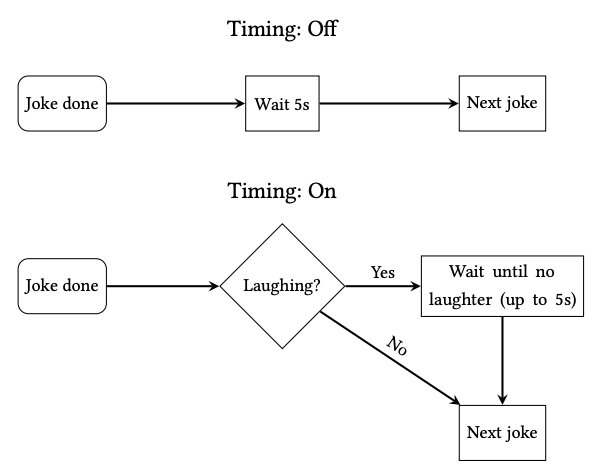
两种模式流程示意图
第一种模式为 bad-timing(不良时机)模式:即讲完每个笑话,固定地等待 5 秒钟再开始下一个。在该模式下,机器人完成了 12 个笑话;
团队用基于音量和声音计数的两种方法来判断观众是否仍在笑和鼓掌。
然后给机器人设定了 170ms 的基准等待时间,如果观众在此期间保持安静,则会开始,如果一直没有回复安静,则会等到 5 秒超时时开始下一个笑话(专家建议,通常 5 秒就足够了。)
第二种模式为 appropriate timing (适当时机)模式:机器人根据现场观众的反应来决定暂停或继续讲。如果观众在笑,则暂停;观众恢复安静,则继续。在该模式下,Jon 完成了 10 个笑话。
该项研究表明,若一个机器人喜剧演员的表演时机把握得好,即给观众适当的反应时间等,会比没有把握好时机的机器人自顾自地进行表演要有趣得多。
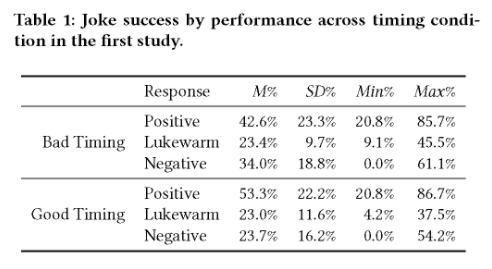
两种模式下成功率对比,适当时机模式成功率更高
因为,当一个笑话成功的时候,观众经常会笑或鼓掌,但由于机器人会在固定延迟时间之后就开始下一个笑话,从而使观众错过下一个笑话的一部分,导致失败。
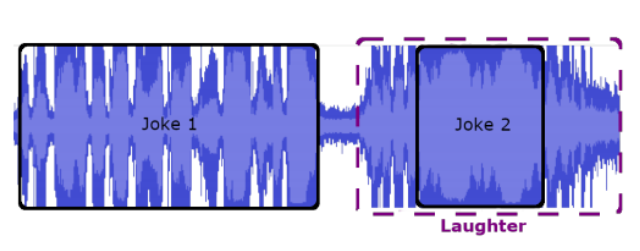
该图显示了,观众在讲笑话 2 时一直在笑
因为他们还沉浸在笑话 1 中
第二项研究:边讲边「察言观色」
第二项研究,是基于俄勒冈州的 10 场表演。团队将观众对于表演的不同响应结果考虑进去,称为「自适应表演」。
研究团队给笑话素材中新增了带有标签的笑话,标签分为激烈,不冷不热和沉默三种。
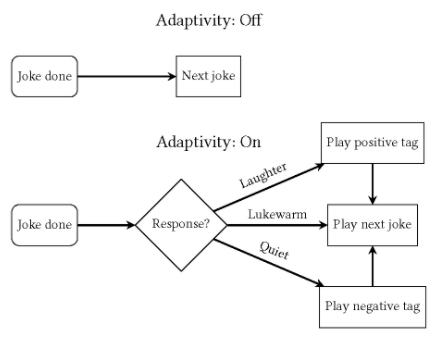
自适应表演会根据观众不同反应选择不同笑话
非自适应表演则单纯地「死记硬背」即可
每当机器人讲完一个笑话后,根据发出观众笑声水平来选择哪种「标签」的笑话。在第二个研究中,所有的表演都选择了适当的时机模式(appropriate timing)。
不过,这项研究结果显示,是否带标签,对于表演的成功率影响不大。
结论:适时抖包袱,成功概率高
综合以上研究,Fitter 总结道:「在坏时机模式(bad-timing mode)下,机器人总是在每个笑话之后等了整整 5 秒钟,不管观众的反应如何。
而在自适应模式(appropriate-timing mode)下,机器人会使用的时机策略在笑声想起时暂停,并在笑声平息后继续进行,就像一个优秀的人类喜剧演员一样。
因此总的来说,当笑话在适当的时机讲出来时,观众的回应率更高。这个技巧上, Jon 已经比较轻车熟路了。
研究意义:提高机器人对人类幽默感的理解
Fitter 说,这 32 场表演,为研究团队提供了足够的数据,以确定机器人脱口秀在不同模式之间的显著差异。而且,这些数据可以帮助「自主社交机器人提高幽默能力」。
同时,这项研究也有助于为喜剧社交互动的关键问题提供一些答案。它将帮助机器人技术和 AI 领域的研究人员,了解现实环境中,人类群体对娱乐化社交机器人的回应情况,也将帮助喜剧演员评估一个笑话或套路的成功与否。

在人类演员主导喜剧世界中,机器人是否会带来变革
比如,下次表演之前,李诞、池子可以先让机器人帮自己彩排一下,如果效果不好,再及时改进。这么说来,脱口秀演员以后可能不需要上台表演,只在幕后专注于写笑话就好了?
就像 Jon 讲的一个笑话:如果你们喜欢我,那就预定我吧!我不仅会讲笑话,还能取代你们的工作


思维导图/流程图相关的软件
MindMaster
- 3.7
(64)咨询产品免费试用亿图图示
- 3.4
(43)咨询产品免费试用ProcessOn
- 3.9
(431)咨询产品免费试用



行业专家共同推荐的软件
Xmind
- 4.0
(626)咨询产品免费试用幕布
- 3.8
(65)咨询产品免费试用万彩脑图大师
- 3.8
(21)咨询产品免费试用



限时免费的思维导图/流程图软件
坚果云思维导图
- 3.8
(23)咨询产品免费试用知犀
- 3.6
(52)咨询产品免费试用迅捷画图
- 3.6
(57)咨询产品免费试用



新锐产品推荐
法大大
- 3.9
(319)咨询产品免费试用石墨文档
- 4.0
(89)咨询产品免费试用Teambition
- 3.7
(90)咨询产品免费试用微盟微商城
- 3.8
(36)咨询产品免费试用有道云笔记
- 4.0
(73)咨询产品免费试用聚水潭erp
- 4.1
(5)咨询产品免费试用







