微软Skype Translator的过去、现在和将来

微软Skype Translator的过去、现在和未来
只会说中文的人和只会说英语的人怎么能交流呢?微软本月初在中国市场发布了Skype Translator中文预览版,还真帮那些不会中文或者英文的人实现了实时交流。
作为一个英语专业的学渣,听到这个消息简直整个人都不好了,我联系了微软亚洲研究院自然语言计算组首席研究员周明博士,聊了聊Skype Translator中文预览版的前世、今生和未来。
Skype Translator中文预览版诞生记
别小看了Skype Translator,微软这个产品的背后,其实是整个科技界近50年集体智慧的结晶,背后涉及到了加密代码的思想、机器学习的突破、深层神经网络的技术进步、语音合成技术的发展等。
故事还要从2012年说起。微软研究院创始人里克•雷斯特(Rick Rashid)博士在天津的“21世纪的计算”大会上,现场演示了中英文的实时语音翻译(亮点在视频第8分钟以后)。里克博士每说一句英文,机器就会以合成的里克博士的口音,同声传译成中文。后来这段视频也在网上被广泛的传播。其实,这背后原始技术主要来自微软亚洲研究院,包括了语音识别、机器翻译、语音合成等三大部分。
这次演示的成功,让微软决定将其产品化,调动了中美两地的相关研发团队,开始了长达两年的研发。
在美国微软研究院的机器翻译产品开发团队的工作就是做好一个通用的机器翻译训练平台,支持各种语言对的翻译系统的训练、测试和实施。微软分布在北京、埃及等各地的团队将自己负责的语言对的翻译系统做好之后可以直接对接上来。该团队除了要负责软件架构的设计、测试,还要负责用户体验,比如说语音、翻译、语音合成的体验,还有速度、空间的考虑等。“他们把这个平台都做得非常好”,采访时周明博士对美国团队给出了如是评价。
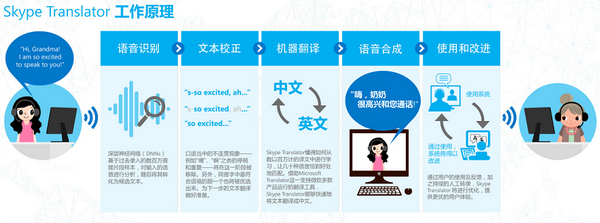
周明博士率领的微软亚洲研究院自然语言计算组,在北京一直努力提升中英语机器翻译的质量。 除了这个组,还有语音组的同事们,跟微软在太平洋两岸的有关产品部门合作,不断努力提升语音识别和语音合成。这其实也正好对应了用机器做翻译的几个主要环节——语音识别、文本校正、机器翻译、语音合成。
做这个项目时,周明已经在微软工作了13年。团队里还有四位博士,“其中两位都是长期从事机器翻译,有十年左右的功力了;还有一位是毕业三年的博士,一位是刚刚毕业的博士。他们分别做数据挖掘、语言模型、翻译模型、解码各个方面的实验,也有人专门去做系统,再把这些模型集成在一起,实现一个端到端(end to end)的翻译过程。”
他们还要负责语音识别结果的调整,高大上的说法叫“语音识别文本的正则化”。主要是断句、消除语音识别的噪声,处理各种口语的现象。此外,还需要对接整个翻译系统,确保整个翻译结果最优。
这个可以轻描淡写的“机器翻译”的过程,背后却是困难重重。周明博士说,这其中涉及到三项关键技术:第一是需要超大规模的双语对照的语料库;第二,需要研究良好的机器学习方法,做好语言模型、翻译模型、调序模型;第三,在指数级的候选集里,以效率最高的一种搜索方法找到最佳的译文。
Skype Translator中文预览版使用的语料库拥有数亿对的中英双语对照句子,比任何翻译大师一生中见过的翻译要多得多得多,用于训练翻译模型。除此之外,还有百亿句子的单语语料库,可用于训练语言模型。这是自然语言计算组通过大规模网络挖掘建立起来的。学习了词汇之间的翻译概率和短语之间的翻译概率。为了加大训练数据,他们也收集了散落在互联网上的UGC内容,譬如各种论坛等。将其中正确率高的东西挑出来,去粗取精。此外,团队还购买了很多专业领域的语料库,譬如技术领域、人文领域的的语料数据。
虽然所有语言都有自己的难点,但中文是意合语言,语序表灵活,省略现象严重,比起英语和日语等语言,缺少形式标志。这期间还真遇到了不少问题。第一个是断词,很多西方语言基本上不需要断词,中间都有空格;第二个是词性,中文的词性从来没有严格定义过,比如说英文、日文里都是很清楚的,这是名词型,这是动词型,但中文里很难从词本身断定词性。;第三个是语序,中文的词序是比较灵活的,比如“我吃饭”、“饭我吃”,都能被理解。第四个是中文随时可以组词,任何两个字凑到一起都是一个词,电脑里面有多少词都永远不够,你很难区分出“中巴友谊万古长青”,到底这是“巴西”还是“巴基斯坦”。此外,中文的上下文连贯,省略得特别严重,有时候动词、形容词都省略了。这些问题使得中文的翻译真不容易。周明博士表示,“我们组虽然做了那么多努力,也没有说能完全解决,依然有很多新的问题等待我们进一步解决”。
Skype Translator中文预览版的未来
过去一两年,因为深层神经网络,语音识别取得了飞跃进展,未来取得突破困难重重,但机器翻译则方兴未艾。微软亚洲研究院自然语言计算组现在也在多方尝试,包括深度学习的方法,直接进行翻译解码,希望取得突破。
在周明博士看来,在中英语间的机器翻译领域,最有可能取得突破的还是这样几个方面:
第一,如何由单句变成考虑上下文的翻译。现在Skype Translator都是一句句的翻译,其实它翻第N句的时候,没有考虑N-1句的翻译。举个简单的例子,比如“driver”这个词,可以翻成司机,也可以翻成驱动程序。假设上面已经翻成驱动程序了,下面说“I want a driver”,有的时候机器依然会傻傻地翻成“我还需要一个司机”。所以第一个是如何由单句翻译进入到考虑上下文的篇章级的翻译,将会是一大突破。这个目前学术界也比较关心。
第二,语音识别之后它有很多的噪音现象。原来做机器翻译的人,基本不考虑噪音,都假设句子完全正确,预处理、分词、正则化、补全等做的都不多。这也是他们目前正在做的。
第三,机器翻译的本地化。在中国不同的城市,有些词汇的翻译也是很微妙的,现在是大一统的翻译。就像有各地的离线地图包一样,未来可能会存在一个语言地图,任何一个城市都有一个语言地图,到天津去就下载一个天津的语言地图。
第四,个性化。不同领域的人用Skype Translator,他们心里是有不同的词汇表,也有不同的领域倾向。微软也很想了解用户的特点,使得翻译更贴近他本人的需要,比如说用户是石油领域的人,他整天用Skype开会,那就尽量用这个领域的词汇表达出来。
仔细想想,这个过程和搜索还是很像的,机会可以完全对应,要做到跟时间、地点、人物能够对应上,还要个性化。


新锐产品推荐
析客在线直播系统
- 0.0
(0)咨询产品免费试用欧众电商直播系统
- 0.0
(0)咨询产品免费试用HiShop直播电商
- 4.5
(1)咨询产品免费试用布谷科技-直播系统
- 0.0
(0)咨询产品免费试用好视通-云直播
- 0.0
(0)咨询产品免费试用AVCast串流直播
- 0.0
(0)咨询产品免费试用







