曾获马斯克资助,取代Google的BERT,史上最强NLP模型GPT 2.0究竟有多特别?
编者按:本文来自微信公众号“脑极体”(ID:unity007),作者藏狐,36氪经授权发布。
元宵一过,年就算正式过完了。没曾想OpenAI和马斯克,居然抓住了春节的小尾巴,携手为全球人民贡献出一个大瓜。
事情是这样的,上周OpenAI推出了一个号称“史上最强通用NLP模型”的新算法GPT-2.0,却没有按照惯例开放该模型和数据集。
研究人员们的溢美之词还没来得及说完,立马被OpenAI这波操作气得怒从心头起,纷纷斥责它全忘初心、恶意炒作。
有人吐槽它应该改名叫“ClosedAI”,还有人把怒火烧到了OPENAI的资助者之一的埃隆·马斯克身上。后者却立马甩锅,表示“没有参与OpenAI 公司事务已超过一年”,“早就理念不合”,正式发推要求“和平分手”……
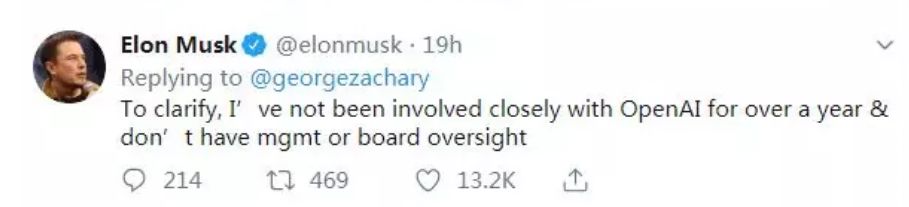
不但惹了众怒,还把创始人兼金主爸爸给玩跑了,OpenAI这是摊上大事,顺手承包了一个瓜田啊。
想要有技术、有品位地吃瓜,先得了解一下,能搅乱技术社区的一池春水、让OpenAI心甘情愿背锅的“罪魁祸首”——GPT2.0,到底有什么神奇之处?
风暴中心的GPT2.0究竟有多特别?
我们知道,训练大型神经网络语言模型一直是NLP领域最具含金量的研究。其中,语义的连贯性,也就是语言生成模型预测上下文的准确度,一直是一个“老大难”问题。
为了解决这个难题,性能更好的通用语言模型就成了研究人员关注的重点。从AI2的 ELMo,到OpenAI的GPT1.0,再到前不久Google的BERT,都是为了让机器不再尬言尬语颠三倒四,说话更加通顺连贯。
但万万没想到,几个月前号称“引领NLP走进新时代”的BERT,这么快就被GPT2.0取代了。
按照深度学习四大要素来对比一下,GPT 2.0到底强在哪里呢?
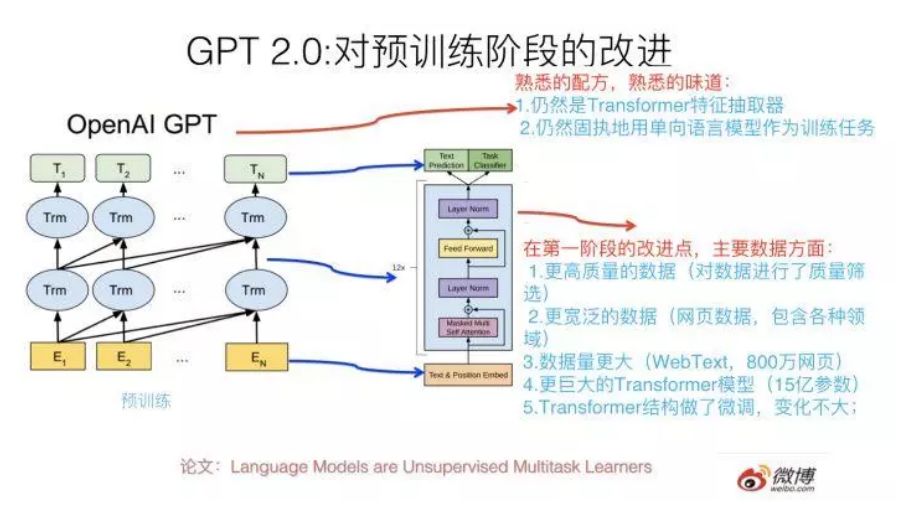
1. 训练数据。引发广泛关注的BERT,使用了3亿参数量进行训练,刷新了11项NLP纪录,这在当时是前所未有的。
而OpenAI推出的GPT-2,则参数量则“丧心病狂”地达到了15亿之多,在一个800 万网页数据集上训练而成,覆盖的主题五花八门。不夸张的说,GPT-2 可能是当前最大的深度模型了。
2. 模型。在深度学习方法上,“先进代表”BERT和GPT-2都采用了Transformer 技术。与传统的特征抽取器RNN、CNN相比,Transformer无论是特征抽取、计算效率,还是翻译任务的综合能力上,都稳操胜券。
不同之处在于,BERT用双向语言模型做预训练,而GPT2.0则使用了古早时代的单向语言模型。坦率地说,GPT-2在预训练中可以使用的架构类型因此受到了限制,无法全面地融合语境,结果就是在下游任务中展现出来的性能远没有当初BERT来得惊艳。
至于为什么不“见贤思齐”,采用更先进的双向语言模型,大概是用长矛干翻步枪这种挑战,更能彰显出“艺高人胆大”的极客风范吧。

3. 算力。“巨无霸”GPT-2的预训练数据量规模横扫所有玩家,使用了约 1000 万篇文章的数据集,文本集合达 40GB。这样训练出来的语言模型优势很明显,比使用专有数据集来的通用性更强,更能理解语言和知识逻辑,可以用于任意领域的下游任务。
但要完成这项任务,必须使用超大规模的GPU机器学习集群,OpenAI为此不得不去争夺紧张而昂贵的GPU训练时间,光是庞大的开销就足以劝退很多想复现其工作的研究者了。
4. 应用。说了这么多,GPT-2的实际应用效果究竟如何呢?来欣赏一下它的文学作品:
输入乔治·奥威尔《一九八四》的开场白:“这是四月的一天,天气晴朗而寒冷,钟敲了十三下”。系统就识别出模糊的未来主义基调和小说风格,并继续写道:
“我在去西雅图找新工作的路上开着车。我把汽油放进去,把钥匙放进去,然后让它跑。我只是想象着那天会是什么样子。一百年后的今天。2045 年,我在中国农村的一所学校教书。我从中国历史和科学史开始。”
不仅情绪模仿到位,GPT-2还能创新观点(哪怕是错误的)。比如发表“回收对世界不利。这对环境有害,对我们的健康有害,对经济不利。”这样毫不政治正确、似是而非的言论。
从实际效果来看,GPT-2理解上下文、生成段落、语序连贯性的能力还是有目共睹的。难怪有专家说,未来加上情节的约束,GPT-2续写《红楼梦》后40回也是有可能的。
俨然是一颗冉冉升起的写作新星,也确实能忽悠到一大部分不明所以的群众。但连“跨时代”的BERT都爽快开源了,也就优秀了那么一小点的GPT-2的闭源,就显得有些耐人寻味了。
从技术斗士到众矢之的:OpenAI是如何打错一手好牌的?
甩出一个“怕被恶意用来制造假新闻”的说辞,自然说服不了经历过大风大浪的人民群众。假视频都见识过了,机器人代笔写点新闻算什么呢,何况也就是小学生水平,至于“敝帚自珍”吗?
同业们开始口诛笔伐,马斯克走得是潇洒无比。细数一下,OpenAI为之诟病的三宗罪:
1.违背了开放的行业“潜规则”
今日的互联网,开源文化早已枝繁叶茂,在AI领域,开放更是默认选项了。
底层技术的更新换代,需要更广泛的生态系统、更多的顶尖技术人员、更多的机构参与才能做好,开放合作显然能最快地催生出更多尖端的创新。
正是因此,绝大多数研究成果及源码,都可以通过博客、会议、社区等公开形式获取,这样做的另一个好处是,避免研究资源被浪费,最大限度地保证研究的合理性和真实性。OPENAI的闭源显然违背了这一基本规则。

2.惯性炒作带来的“晕轮效应”
心理学上有个规律,叫“晕轮效应”,当认知者对一个人的某种特征形成固定印象后,还会再从这个判断推论其他方面的特征。OPENAI就很不幸地背上了一个“欺骗性炒作”前科的“光环”,并成功引发了大家的联想。
之前在一对一DOTA2中打败顶级人类玩家 “Dendi”,OPENAI就发出了诸如“攻陷DOTA2”“AI完虐人类”“碾压AlphaGo”等宣言,就被指过于浮夸。
过度夸大、诱导媒体报道的事情OPENAI实在没少干。目光回到GPT-2,普遍观点是,为了避免造假风险而不开放,既对安全毫无帮助,也对技术进步无益。
面对非要采用过气模型的固执,和“碾压人类作者”的语气,大家立马从熟悉的套路中嗅到了“同样的配方和味道”。那点可取之处,也被既往炒作“AI焦虑”的后遗症所反噬了。

3.助长AI集权的真实阴影
如果说上述指责都难免带点理想主义情绪的话,那么GPT-2私有化带来的实实在在的影响,恐怕才是点燃大众恐慌的真正导火索。
作为“新的石油”,数据资源早就显示出封闭的迹象。谷歌、亚马逊、Facebook这些科技巨头手里积累了大量的数据财富,并且越来越强大。各国都将AI成果视为国家战略资源,德法等已经开始对数据收集及使用征税。
而以GPT-2为代表的无监督学习趋势,又意味着技术进步与创新愈加依赖于更大容量的模型和超大规模的数据集支持。

也就是说,一旦大公司不愿意开放源码和数据集,财力不足的学府和中小开发者极有可能就会被请出牌桌。
当初说要“为全人类AI 技术保驾护航”的OpenAI都搞起了私有化,显然令开源文化“腹背受敌”,起到了很恶劣的示范作用,怎么怼都不冤。
不过,只是一味指责,咱们这瓜就吃的太没有技术含量了。关键要搞清楚,为什么明知会被喷,OpenAI还非要这么干呢?
开源和私有化:算法公司的商业困境
OpenAI选择技术私有化,虽然有着种种的不合情,在知识产权归属上却并没有什么可指摘的地方。而逼得它不得不违背理想的根本原因,或许才是AI和全人类真正的敌人。
简单来说,正是算法公司们集体商业化失守。
美国当代技术哲学家芬伯格(Andrew Feenberg)在上个世纪90年代就曾经提出过,技术的开放是为了提高全社会的技术福利,而非打击技术的商业价值。但直到今天,算法的商业化之路依然道阻且长。
在高昂的数据及研发成本下,算法公司想要支撑长期的研究,主要有三种方式:
1.售卖专利。算法研发可算是AI产业链中最上游、最具价值的业务,但即便算法公司手握专利,在更深层次的软硬件应用方案不成熟的大环境下,也很难养活自己。
2.开源,从其他业务获益。借鉴互联网“羊毛出在猪身上”的商业模式,算法的价值可以通过其他业务的补充来实现。
比如Facebook一直致力于开放其所有代码和技术架构的源代码,吸引来不少优秀的开发者,品牌和口碑也借此大涨。但前提是,Facebook不靠售卖软件盈利,开源不会冲击自有业务。对于单纯的算法公司来说,显然不可行。
3.找金主“包养”。目前看来,寻找一个大型商业机构得到资助,几乎是算法公司最好的归宿了,比如谷歌之于Deepmind,特斯拉之于OpenAI。但受制于人的日子显然也并不好过。
两者结合的结果就是,一边需要满足投资人追求回报的愿望;一边还要提防着主业务受创耽搁自己搞技术。此次马斯克退出董事会,OpenAI的未来顿时就不明朗起来。

总而言之,OpenAI的开源困境背后,也暴露出一种纯技术公司的集体无奈:你得开源,要不然没法维持技术生态;又不能啥都开源,捧着金碗要饭。这个度真的是很难把握。
不难意识到,随着数据封闭的浪潮,AI开源的未来不容乐观已是既定事实,OpenAI只不过是加了一把火而已,私有化的锅它一个可背不动。
要解决这个问题,靠的不是道德绑架或者祈求大机构的仁慈,口水战可以休矣。而是集全社会之力,更快催熟完善的产业链体系,激活更多元的商业模式和应用场景。
算法的商业化价值初现曙光的时候,才是科技企业有力量承担社会责任的时候。





大厂都在用的知识产权软件
知协科技
- 4.0
(5)咨询产品免费试用知果果
- 3.5
(1)咨询产品免费试用库音 COOLVOX
- 0.0
(0)咨询产品免费试用



限时免费的知识产权软件
顶呱呱
- 0.0
(0)咨询产品免费试用权大师
- 0.0
(0)咨询产品免费试用创业树-企业服务平台
- 0.0
(0)咨询产品免费试用



新锐产品推荐
Yeastar 智慧办公
- 4.5
(5)咨询产品免费试用ABIS多模态生物识别统一平台
- 0.0
(0)咨询产品免费试用国双知识智能平台
- 0.0
(0)咨询产品免费试用国双工业互联网平台(GridsumCOMPaaS)
- 0.0
(0)咨询产品免费试用国双分布式关系型数据库管理系统 Gridsum DB
- 0.0
(0)咨询产品免费试用国双大数据平台
- 0.0
(0)咨询产品免费试用







