处理35亿张图片+42台服务器+336块显卡,硅谷可怕的AI算力就是这么来的
编者按:本文来自微信公众号“硅谷洞察”(ID:guigudiyixian),作者 Zhang Zhan,首发于腾讯科技,36氪经授权发布。
01.三十五亿张照片,树立人工智能新标杆
上周日,Facebook人工智能研究院(Facebook Artificial Intelligence Research)首席科学家,人工智能界的先驱 Yan Lecun(杨立昆)宣布开源了他们在图像识别以及整个计算机视觉领域的最新模型——“在Instagram的图片标签上预训练,在ImageNet上微调(finetune)的ResNext101模型”。
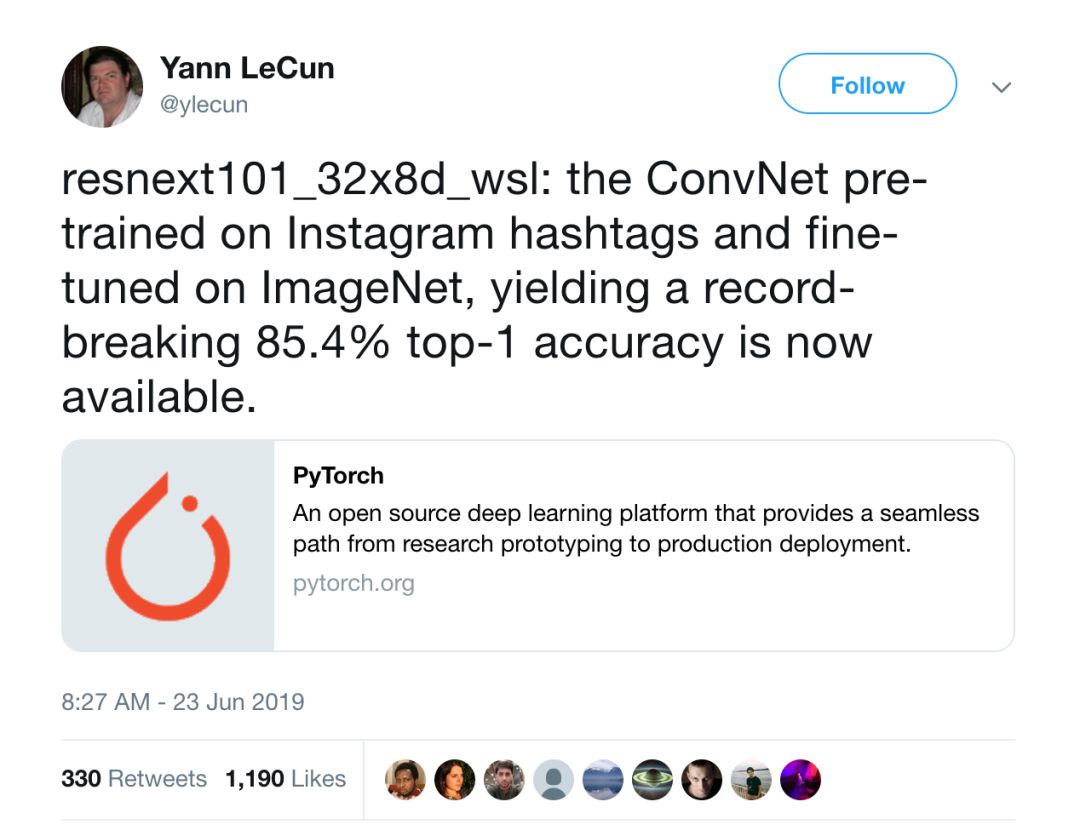
Yann Lecun Twitter
若你对这一领域有所了解,再着重关注一下上面引号里的那句描述,你可能就会不由自主地飙出一句:“有钱真 [敏感词] 好啊!”。

ImageNet数据集
时过境迁,对 FAIR 来说,角色一转,ImageNet 居然成了迁移、微调的对象。
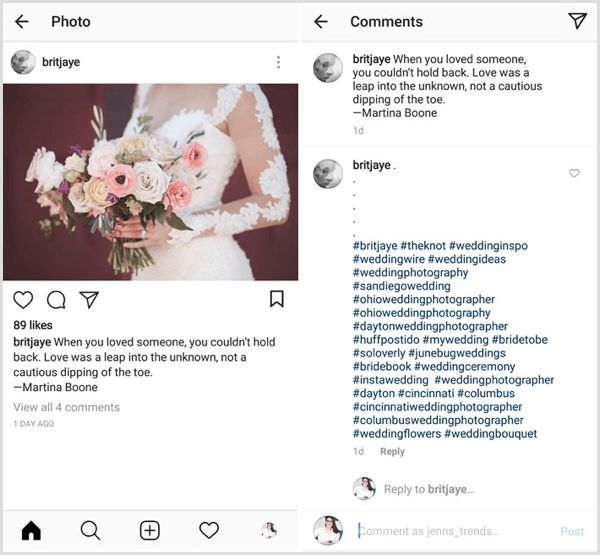
Instagram标签(右边蓝色#开头短语即为图片标签hashtag)
史无前例的海量数据之下,算力亦是重头戏。
颇有股“有钱使得鬼推磨”的气派。
其实从一开始,游戏的规则就是如此 。
近些年的人工智能革命,其实大抵建立于人工神经网络模型的大放异彩。
而究其根本,在上世纪70年代,人工神经网络模型的理论架构已经基本成熟,却在之后的几十年里一直没能得到认可、应用,直到近来才得以重见天日。
这其后的根源,就在于算力的限制。上世纪的计算机算力和你手中的新款手机比起都可谓云泥之别,遑论吸纳海量数据,对神经网络模型进行训练。
时至2012年,算力的突飞猛进,加上 ImageNet 等前所未有的“巨型数据集”的出现,神经网络才真正再次登台,绘下人工智能新时代的夺目图景。
不过,又过了 7 年,直到现在,ImageNet 才终于被更大的数据集所取代,在这背后,弱监督学习功不可没。
02.强监督、弱监督、自监督
"弱"监督学习,自是相对于"强"监督学习而言。

ImageNet数据集里的一张图片,标注为波斯猫
在这种情况下,人工智能模型还能学到图片与含混描述之间的对应关系吗?
从此,人工标注不再是计算机视觉领域的最大瓶颈,弱监督标签搭配巨头的强大算力,就能得到比悉心雕凿,训练于 ImageNet 之上的“小数据”模型好得多的性能表现。
不同于 Facebook 视觉新模型的弱监督训练,在自然语言处理领域,更进一步的自监督训练已成主流。
Google 去年开源的 BERT 模型,在训练时会将输入句子的随机单词盖住,然后让模型根据上下文的内容预测被盖住的单词是什么,通过这一方式,模型可以学习到自然语言隐含的句法,亦能对词义句义有所掌握。
更重要的是,这一方法不需要任何人工标注,可谓“人有多大胆,地有多大产”,数字时代无数的自然语言资源 —— 电子书、网站、论坛帖子等等等等都能成为训练数据的来源。句子以自身信息作为监督,对模型进行训练,故称自监督学习。
在 BERT 原论文里,Google 用了 16 块自主研发的人工智能芯片——张量处理器(Tensor Processing Unit,TPU)训练了四天四夜,才最终收获了突破性的结果。
若你想以显卡为标准作以比较,英伟达足足用了64张自家的顶级显卡,在多方优化之下训练了三天有余,才成功复现这一成果。

谷歌TPU芯片
今年卡耐基梅隆大学(CMU)和 Google 合作研发的 XLNet 模型,则在BERT的基础上更进一步,在足足 512 块 TPU 上训练了两天半时间。
以 Google Cloud(谷歌云服务)的计价标准计算, 训练一次 XLNet 模型总共需要二十四万五千美元 (合人民币一百六十余万)。若再考虑上模型研发过程中的不断试错,调参验证等等过程,XLNet 模型的开销简直天文数字。
03.算力垄断之下,中小团队如何应对?
相互竞争之中,算力巨头们多会将自己训练好的模型对外开源,让没有训练资源的团队也能得以在模型上进行微调,得以应用。虽然这一过程亦对算力有所要求,但却已比从头训练现实的多。
目前,不少国内互联网公司已将BERT开源模型应用于自然语言处理系统之中,大大提升了系统的自然语言理解能力。视觉领域公司则可以从FAIR的新模型入手,对自身的图像识别系统的骨干模型进行更新升级,以期取得更好的成效。
中小团队在算力上对大公司望尘莫及,亦因而无力在如多类别图片分类等基础问题上与算力巨头逐鹿竞技,却可以基于自身的独特优势,在细分特定问题上夯实基础。
在去年年底拿到四亿美元C轮融资的Zymergen,便立足于自身在生物领域的深厚技术研发,将AI运用于药物、材料研发中,避开了与巨头在图像、自然语言处理等领域的白热化竞争,成就了自己独特的技术护城河。

Zymergen公司
https://www.vox.com/2015/6/16/11563594/synthetic-biology-startup-zymergen-emerges-from-stealth-with-44
“ 更高更快更强 ”还是根本。
对AI芯片公司来说,这更是机遇所在。
若是通过不断的芯片研发,提高人工智能算法的训练、运行效率,以更低的成本提供更多的算力,AI芯片创业公司便能在这个算力为王的时代脱颖而出,成为英伟达显卡、谷歌TPU之外的重要选择。
拿到微软、三星投资,估值过亿美元的独角兽公司GraphCore便推出了自家研发的智能处理芯片(Intelligence Processing Unit, IPU),在从训练到推理的整个流程之上,试图与GPU和TPU一决高下。根据测试,IPU在能耗、速度、时延等方面都显出了自己的独特优势,有望成为AI算力战场的又一有力竞争对手。

GraphCore IPU芯片
https://www.theverge.com/circuitbreaker/2018/11/26/18112462/graphcore-new-ai-chips-server-processors-design-colorful
“差异化”核心的重要性又一次凸显。
巨头企业也应负起自身的社群责任,为技术、模型的开源化作出贡献,让更多的开发者、团队、科研人员受益于业界最新技术的发展。这也将有助于巨头公司自身的形象确立,吸引更多人才加入,为自身发展添砖加瓦。
不过,无论中小团队还是巨头企业,算力的提升都是重点议题。 现如今,为图形计算而生的显卡仍是我们人工智能系统的主要硬件。


数据库相关的软件
华为云-云数据库 RDS for MySQL
- 4.3
(2)咨询产品免费试用悦数图数据库
- 4.3
(4)咨询产品免费试用滴普科技
- 4.3
(44)咨询产品免费试用



行业专家共同推荐的软件
PostgreSQL
- 4.3
(42)咨询产品免费试用MySQL
- 4.0
(30)咨询产品免费试用Snowflake
- 4.0
(41)咨询产品免费试用



限时免费的数据库软件
Redis
- 4.1
(31)咨询产品免费试用Microsoft Access
- 4.1
(27)咨询产品免费试用Quickbase
- 4.0
(40)咨询产品免费试用



新锐产品推荐
Zoho Workplace
- 3.9
(42)咨询产品免费试用轻速云
- 4.9
(3)咨询产品免费试用云报餐
- 4.8
(12)咨询产品免费试用YOP有谱项目管理
- 0.0
(0)咨询产品免费试用华为云-需求管理 CodeArts Req
- 4.1
(160)咨询产品免费试用Remember the milk
- 3.6
(8)咨询产品免费试用







