2016 AI 巨头开源 IP 超级盘点,Top 50 最常用深度学习库
编者按:本文来自微信公众号”新智元“(ID:AI_era),36氪经授权发布。
Data Science Central 网站主编、有多年数据科学和商业分析模型从业经验的 Bill Vorhies曾撰文指出,过去一年人工智能和深度学习最重要的发展不在技术,而是商业模式的转变——所有巨头纷纷将其深度学习 IP 开源。 毋庸置疑,“开源浪潮”是 2016 年人工智能领域不可忽视的一大趋势,而其中最受欢迎的项目则是谷歌的深度学习平台 TensorFlow。下文就从TensorFlow 说起,盘点2016年AI开源项目,最后统计了 Github 最常用深度学习开源项目 Top 50。
谷歌开源:围绕 TensorFlow 打造深度学习生态圈
1. Google第二代深度学习引擎TensorFlow开源
2015年11月,谷歌开源深度学习平台 TensorFlow。2016年4月,谷歌推出了分布式 TensorFlow。现在,TensorFlow 已经成为业内最受欢迎的深度学习平台之一。
2. 谷歌开源全球最精准语言解析器SnytaxNet
2016年5月13日,Google Research宣布,世界准确度最高的自然语言解析器 SyntaxNet 开源。谷歌开源再进一步。据介绍,谷歌在该平台上训练的模型的语言理解准确率超过90%。SyntaxNet 是一个在TensoFlow中运行的开源神经网络框架,提供自然语言理解系统基础。谷歌公开了所有用户自己的数据训练新SyntaxNet模型所需要的代码,以及谷歌已经训练好的,可用于分析英语文本的模型 Paesey McParseface。
Paesey McParseface 建立于强大的机器学习算法,可以学会分析句子的语言结构,能解释特定句子中每一个词的功能。此类模型中,Paesey McParseface是世界上最精确的,谷歌希望它能帮助对自动提取信息、翻译和其他自然语言理解(NLU)中的应用感兴趣的研究者和开发者。
3. 谷歌推出 Deep&Wide Learning,开源深度学习 API
2016年6月29日,谷歌推出 Wide & Deep Learning,并将 TensorFlow API 开源,欢迎开发者使用这款最新的工具。同时开源的还有对 Wide & Deep Learning 的实现,作为 TF.Learn 应用程序接口的一部分,让开发者也能自己训练模型。
4. 谷歌开源 TensorFlow 自动文本摘要生成模型
2016年8月25日,谷歌开源了 TensorFlow 中用于文本信息提取并自动生成摘要的模型,尤其擅长长文本处理,这对自动处理海量信息十分有用。自动文本摘要最典型的例子便是新闻报道的标题自动生成,为了做好摘要,机器学习模型需要能够理解文档、提取重要信息,这些任务对于计算机来说都是极具挑战的,特别是在文档长度增加的情况下。
5. 谷歌开源图像分类工具TF-Slim,定义TensorFlow 复杂模型
2016年8月31日,谷歌宣布开源 TensorFlow 高级软件包 TF-Slim,能使用户快速准确地定义复杂模型,尤其是图像分类任务。自发布以来,TF-Slim 已经得到长足发展,无论是网络层、代价函数,还是评估标准,都增加了很多类型,训练和评估模型也有了很多便利的常规操作手段。这些手段使你在并行读取数据或者在多台机器上部署模型等大规模运行时,不必为细节操心。此外,谷歌研究员还制作了 TF-Slim 图像模型库,为很多广泛使用的图像分类模型提供了定义以及训练脚本,这些都是使用标准的数据库写就的。TF-Slim 及其组成部分都已经在谷歌内部得到广泛的使用,很多升级也都整合进了 tf.contrib.slim。
6. 谷歌开源大规模数据库,10亿+数据,探索 RNN 极限
2016年9月13日,谷歌宣布开源大规模语言建模模型库,这项名为“探索RNN极限”的研究今年2月发表时就引发激论,如今姗姗来迟的开源更加引人瞩目。研究测试取得了极好的成绩,另外开源的数据库含有大约 10 亿英语单词,词汇有 80 万,大部分是新闻数据。这是典型的产业研究,只有在谷歌这样的大公司才做得出来。这次开源也应该会像作者希望的那样,在机器翻译、语音识别等领域起到推进作用。
7. 谷歌开源 TensorFlow 图说生成模型,可真正理解图像
2016年9月23日,谷歌宣布开源图说生成系统 Show and Tell 最新版在 TensorFlow 上的模型。该系统采用编码器-解码器神经网络架构,分类准确率达 93.9%,在遇到全新的场景时能够生成准确的新图说。谷歌表示,这说明该系统能够真正理解图像。
8. 谷歌开源超大数据库,含800万+视频
2016年9月28日,谷歌在官方博客上宣布,将含有800万个Youtube 视频URL 的视频数据库开源,视频总时长达到了50万个小时。一并发布的还有从包含了4800个知识图谱分类数据集中提取的视频级别标签。这一数据库在规模和覆盖的种类上都比现有的视频数据库有显著提升。例如,较为著名的Sports-1M数据库,就只由100万个Youtube 视频和500个运动类目。谷歌官方博客上说,在视频的数量和种类上,Youtube-8M代表的是几乎指数级的增长。
9. 谷歌发布 Open Images 图片数据集,包含900万标注图片
2016年10月1日,继前天发布800万视频数据集之后,谷歌又发布了图片数据库Open Images,包含了900万标注数据,标签种类超过6000种。谷歌在官方博客中写到,这比只拥有1000个分类的ImageNet 更加贴近实际生活。对于想要从零开始训练计算机视觉模型的人来说,这些数据远远足够了。就在 12月,谷歌还开源了 Open Images 并行下载工具的脚本,5 天速度最高超过 200 M。
10. DeepMind 开源 AI 核心平台 DeepMind Lab(附论文)
2016年 12月 5日,DeepMind 宣布将其AI 核心平台 DeepMind Lab 开源。DeepMind 实验室把全部代码上传至 Github,供研究人员和开发者进行实验和研究。DeepMind Lab 这一平台将几个不同的 AI 研究领域整合至一个环境下,方便研究人员测试AI 智能体导航、记忆和3D成像等能力。值得一提的是,这些代码也包括 AlphaGO 的代码,谷歌希望以此增加 AI 能力的开放性,让更多开发者参与 AI 研究,观察其他开发者是否能够挑战并打破 DeepMind 现在的纪录。
Facebook 开源:贯彻理念
1. Facebook 开源围棋引擎 DarkForest
6 个月前,Facebook 将其围棋引擎 DarkForest 开源。现在训练代码已经全部发布。Github 链接:https://github.com/facebookresearch/darkforestGo。
2. Facebook 开源文本分类工具 fastText,不用深度学习也可以又快又准
2016 年 8 月19日,Facebook AI 实验室(FAIR)宣布开源文本分析工具 fastText。fastText 既可以用于文本分类,又能用于学习词汇向量表征。在文本分类的准确率上与一些常用的深度学习工具不相上下,但是在时间上却快很多——模型训练时间从几天减少到几秒。除了文本分类,fastText 也能被用于学习词语的向量表征,Facebook 称 fastText 比常用的 Word2vec 等最先进的词态表征工具表现都要好得多。
3. Facebook 开源计算机视觉系统 deepmask,从像素水平理解图像(附论文及代码)
2016 年 8 月 26日,Facebook 宣布开源计算机视觉系统 deepmask,称该系统能“从像素水平理解物体”,Facebook 希望开源能加速计算机视觉的发展。不过,Facebook 并没有在自家产品中使用这些工具,像这样落实到具体应用前就开源,跟通常所说的“开源”有些不同。对此,Facebook 人工智能团队 FAIR 的负责人 Yann LeCun 曾表示,正是因为 FAIR 做基础的、不受制于公司短期效益的研究,才能真正推进人工智能技术发展。
4. Facebook 开源 AI 训练和测试环境 CommAI-env
2016 年 9 月 27日,Facebook 宣布开放 AI 训练和测试环境 CommAI-env,可以用任何编程语言设置智能体。据介绍,CommAI-env 这个平台用于训练和评估 AI 系统,尤其是注重沟通和学习的 AI 系统。与用强化学习从玩游戏到下围棋都能做的 OpenAI Gym 不同,Facebook 的 CommAI-env 侧重基于沟通的训练和测试,这也是为了鼓励开发人员更好地打造能够沟通和学习的人工智能,呼应该公司的十年规划。Facebook 还表示,CommAI-env 会持续更新,并在成熟后举办竞赛推进 AI 的开发。
在AI 测试环境方面,Facebook 还开源了 CommNet,这是一个让基于神经网络的代理更好交互、实现合作而研发的模型,与 CommAI-env 配套。12 月,Facebook 还开源了 TorchCraft,在深度学习环境 Torch 与星际争霸之间搭起了桥梁,方便研究人员使用控制器,编写能够玩星际争霸游戏的智能代理。
5. Facebook 贾扬清发文介绍 Caffe2go,手机就能运行神经网络
2016 年 11月 8日,Caffe作者、Facebook 研究员贾扬清在官方网站上发文介绍了新的机器学习框架 Caffe2go,并表示在接下来的几个月将其部分开源。Caffe2go 规模更小,训练速度更快,对计算性能要求较低,在手机上就行运行,已经成为 Facebook 机器学习的核心技术。
OpenAI
1. OpenAI 推出代理训练环境 OpenAI Gym
创立于 2015 年底的非盈利机构 OpenAI 的成立打破了谷歌、Facebook 等巨头霸占 AI 领域的格局,但其创始人、特斯拉CEO马斯克多次发表人工智能威胁论。马斯克创立 OpenAI 目的何在?2016年 5 月 4日,OpenAI 发布了人工智能研究工具集 OpenAI Gym,用于研发和比较强化学习算法,分析 OpenAI Gym 或可找出马斯克的真正动机。
2. 另一种开源:OpenAI 介绍深度学习基础框架
2016 年 8 月 30 日,OpenAI 研究员在博客发文,结合实例介绍了 OpenAI 进行深度学习研究时采用的基础设施配置,并且提供了相关开源代码。文章激起了很多反响,相对于软硬件开源,OpenAI 从另一个侧面,对深度学习模型的实际部署提供了帮助。
3. OpenAI 重磅发布 AGI 测试训练平台 Universe
2016年12月 4日,在今年 NIPS 大会召开的前一晚,OpenAI 发布了 Universe,用于训练解决通用问题 AI 的基础架构。据悉,这是一个能在几乎所有环境中衡量和训练 AI 通用智能水平的开源平台,目标是让智能体能像人一样使用计算机。目前,Universe 已经有1000种训练环境,由微软、英伟达等公司参与建设。有了 Universe,任何程序都能被接入到 OpenAI Gym 的环境中。很快,OpenAI 还推出了 Mini World of Bits(MiniWoB),这个与 OpenAI Universe 配套的环境基准可以测试代理与常见网页浏览器元素的交互能力,比如按钮、文本框、滑块。
微软开源:CNTK 升级版
根据 Github 2016 年度的《Octoverse 观察报告》,微软不仅是拥有开源项目最多的公司,也是贡献人数最多的公司。
在人工智能方面,微软的开源项目有很多,包括 CNTK计算网络工具包、DMTK分布式机器学习工具包,Send2vec语义相似映射器, 以及 CodaLab 研究平台(基于Web的开源平台,旨在通过其在线社区帮助解决数据导向的许多常见问题,从而促进机器学习和高性能计算的研究领域的发展)。
2016 年 10 月 27日,微软开源深度学习认知工具包 CNTK 升级版,其中最瞩目的功能是增加了 Python 绑定,支持增强学习。新版的 CNTK 性能大幅提升,尤其是在多台机器上处理较大数据集的情况下能高速运行,这种类型的大规模部署对于多GPU上的深度学习是不可或缺的,也是开发消费产品和专业产品的必需。
微软研究人员表示,在多服务器间运行的能力是一大进步。CNTK 升级版还包含了一些算法,用于将大规模数据处理的计算消耗降到最低。
百度
1. 百度开源深度学习代码 Warp-CTC 详解
2016 年 1月 15 日,百度公布了代码 Warp-CTC,能够让 AI 软件运行得更高效。说 Warp-CTC 知道的人可能还少,百度语音识别系统 Deep Speech 2 就是用它搭建的。百度位于硅谷的 AI 实验室主管 Adam Coates 在接受 Re-Work 采访时表示,他们在构建深度语音端对端系统的过程中发明了Warp-CTC 方法,进而使用 CTC 提高模型的可伸缩性。“由于没有相似的工具,我们决定将其分享给人们。它是一款很实用的工具,可以用到现有的AI框架中。现在有很多深度学习的开源软件,但是之前用于训练序列数据的端对端网络一直很慢。我们在Warp-CTC上的投入是对“我们坚信深度学习与高性能计算技术(HPC)的结合会有巨大潜力”的一种证明。”
2. 百度开源分布式深度学习平台,挑战 TensorFlow(附教程)
2016 年 8 月 31日,百度宣布开源深度学习平台 PaddlePaddle。实际上,百度深度学习实验室在几年前就投入 PaddlePaddle 的开发,业内对这个云端托管的分布式深度学习平台赞誉有加:代码简洁、设计干净,没有太多抽象……PaddlePaddle 对于序列输入、稀疏输入和大规模数据的模型训练有着良好的支持,支持GPU运算,支持数据并行和模型并行,仅需少量代码就能训练深度学习模型,大大降低了用户使用深度学习技术的成本。
3. 百度公开硬件基准 DeepBench,推动深度学习专用芯片研发竞争
2016 年 9月,百度发表论文,开源 DeepBench 基准测试,AI研究者和芯片制造商可以用它测试不同的芯片运行软件时的性能,尤其是哪款硬件加速深度学习性能最好。目前 DeepBench 只能测试深度学习的训练模型,能提供在三种 Nvidia GPU和一种 Intel Xeon Phi 处理器的基准化测试结果,未来还可能测试用于图像和语音识别之类任务的“推理”模型。百度希望 DeepBench 能促进特定任务深度学习加速器的研发,“GPU显然不是终点,我们希望这能鼓励竞争”。
GitHub 最受欢迎的深度学习项目
最后,在这里附上一份非常有用的资料表:GitHub 最常用的 54 个深度学习项目,最后更新时间是今年 8 月。表格的整理人ID分别是 aymericdamien、lenck、pjreddie、vmarkovtsev、JohnAllen。
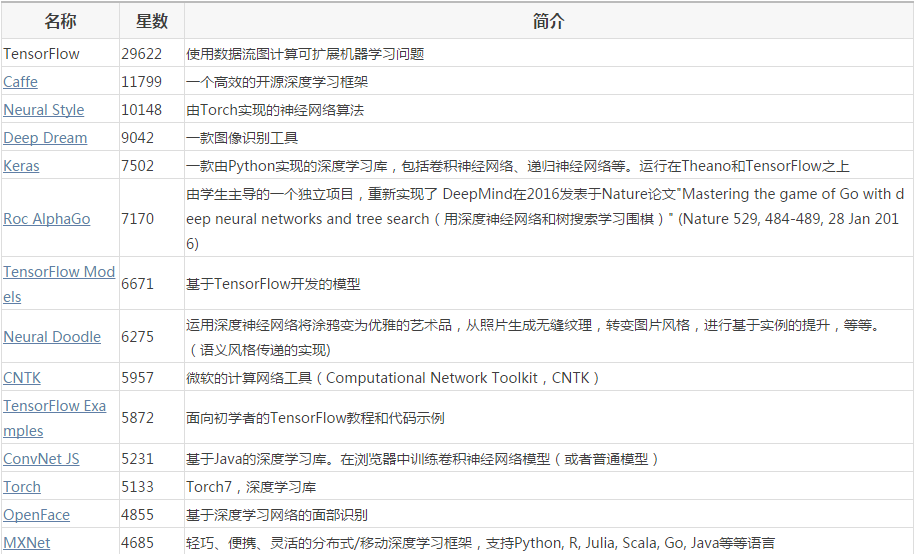

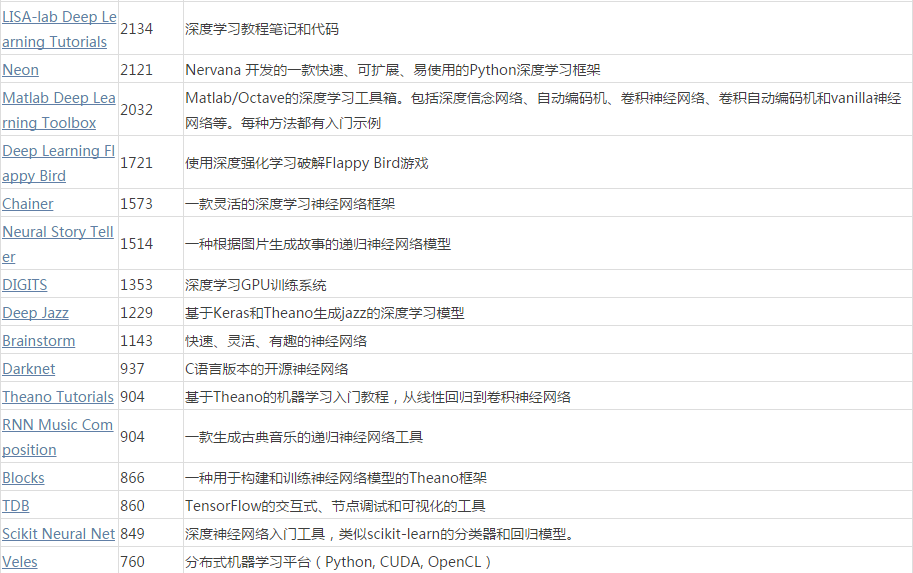
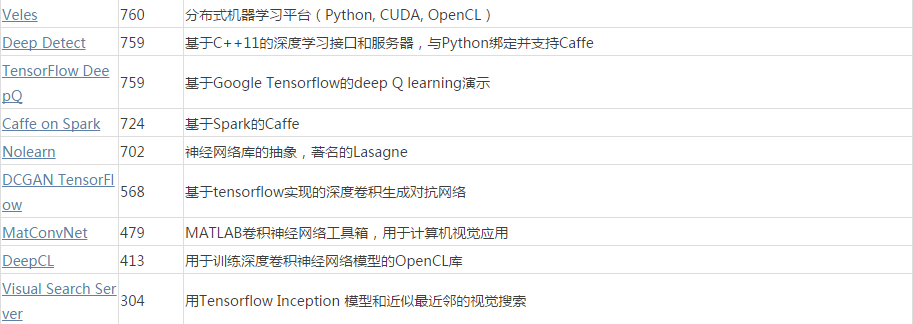



数据库相关的软件
华为云-云数据库 RDS for MySQL
- 4.3
(2)咨询产品免费试用悦数图数据库
- 4.3
(4)咨询产品免费试用滴普科技
- 4.3
(44)咨询产品免费试用



大厂都在用的数据库软件
PostgreSQL
- 4.3
(42)咨询产品免费试用MySQL
- 4.0
(30)咨询产品免费试用Snowflake
- 4.0
(41)咨询产品免费试用



限时免费的数据库软件
Redis
- 4.1
(31)咨询产品免费试用Microsoft Access
- 4.1
(27)咨询产品免费试用Quickbase
- 4.0
(40)咨询产品免费试用



新锐产品推荐
139邮箱
- 4.0
(4)咨询产品免费试用189邮箱
- 4.0
(1)咨询产品免费试用视觉中国
- 4.2
(17)咨询产品免费试用大象慧云-供应链协同管理
- 0.0
(0)咨询产品免费试用搜狐邮箱
- 3.0
(2)咨询产品免费试用TOM邮箱
- 0.0
(0)咨询产品免费试用







