搜索引擎开始「实体搜索」新领域竞争,Google、百度分别发力实体搜索产品
编者注:本文来自
@刚果不说话 的投稿,点击关注他的新浪微博。
以 Google 收购 Freebase 为标志,到今年正式推出
知识图谱(Knowledge Graph)产品,代表Google 建设实体(Entity)属性数据(也称为Ontology或者Semantic Web)基本成熟, 开始进入产品转化期。
初期知识图谱产品只是作为类似「百科」的形式进行展示,并未显示出足够的吸引力。近期知识图谱产品的一系列升级,开始逐步展现出了产品魅力。Google可以在更广泛的领域直接提供精准答案,而不只是作为搜索结果的中转集散地,这一点和百度「框计算」的思路比较类似。比如搜索“zhang yimou movie”,用户得到的不再是一些搜索结果的候选链接,而是直接由实体数据提供的精准结果。令人略感遗憾的是,Google似乎并未对中文研发进行投入,这部分功能中文用户还无法使用到。同时中文搜索方面,百度虽为对外公开,似乎有一系列实体搜索的相关产品也在借助「框计算」的形式逐步推出.
以下是一些实际的例子:
- 实体属性类产品:
zhang yimou's movie:
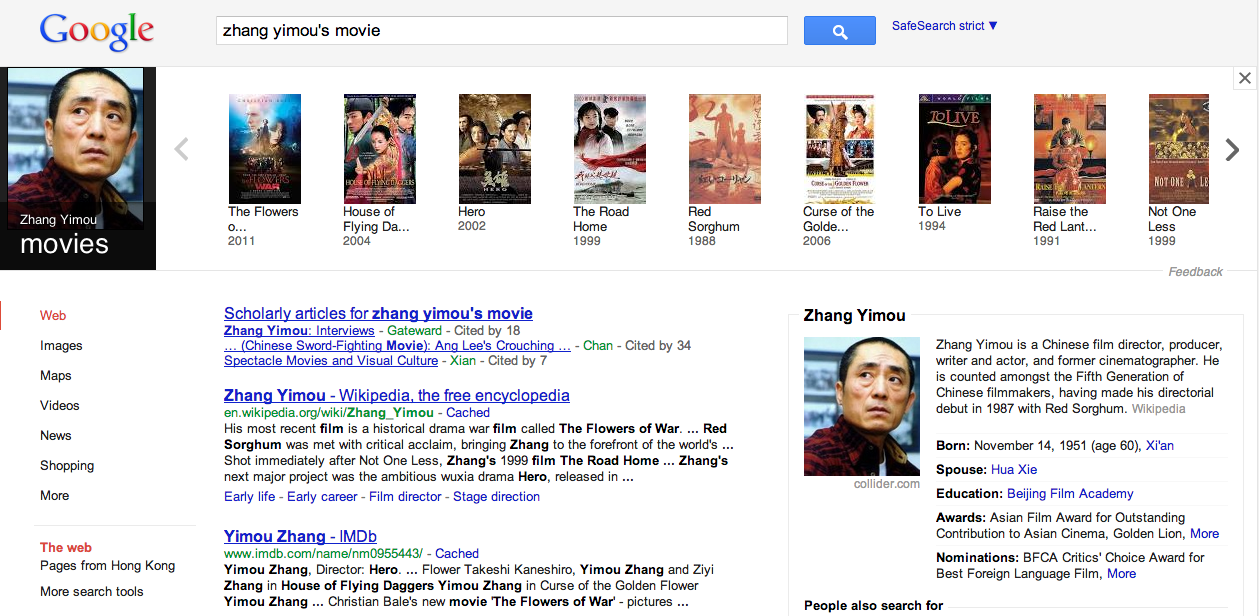
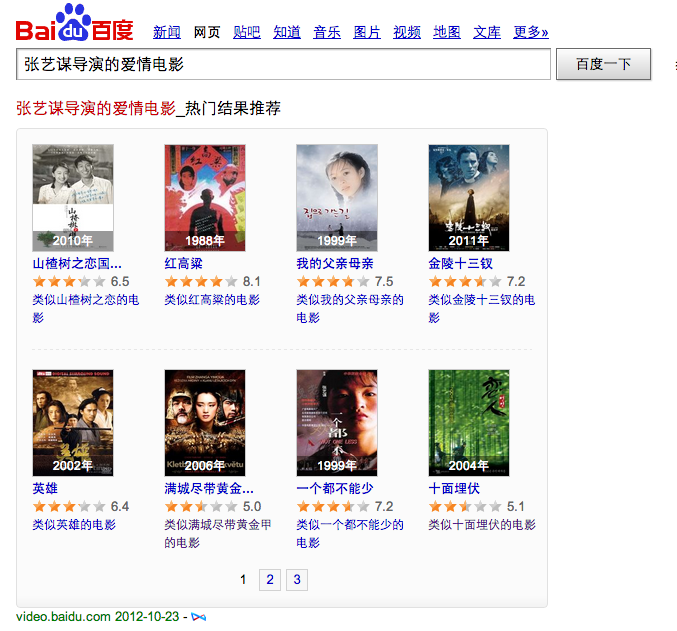
张艺谋导演的爱情电影
- 实体关联关系产品:
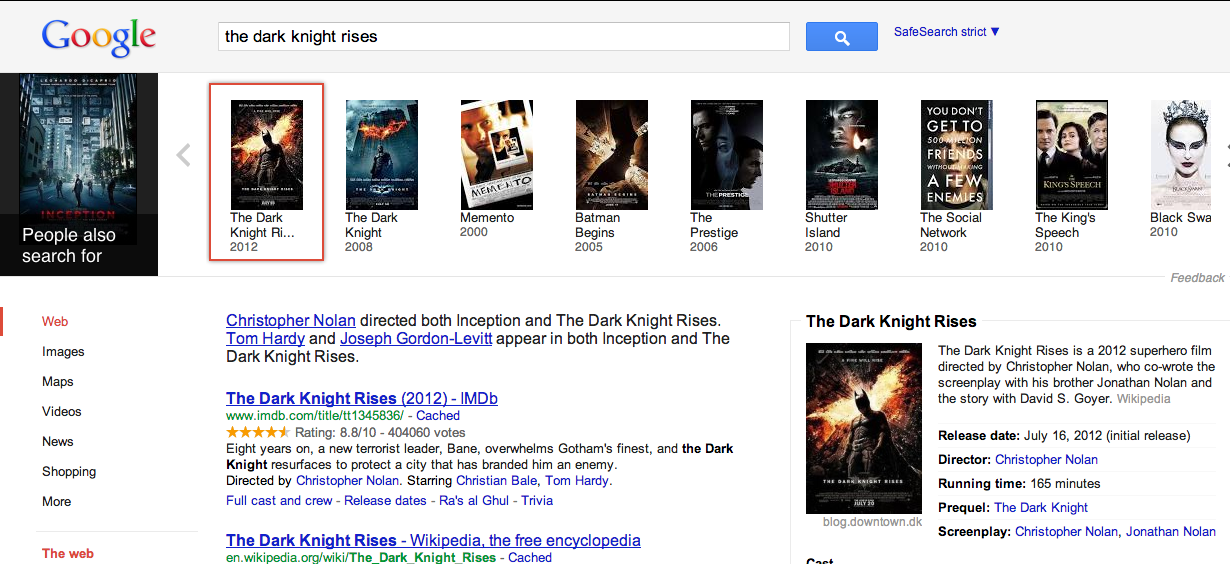
Google的关联关系不能直接通过搜索触发,需要先搜索相应的实体名,比如inception,通过点击右侧的“people also search for”结果进行触发
also search for
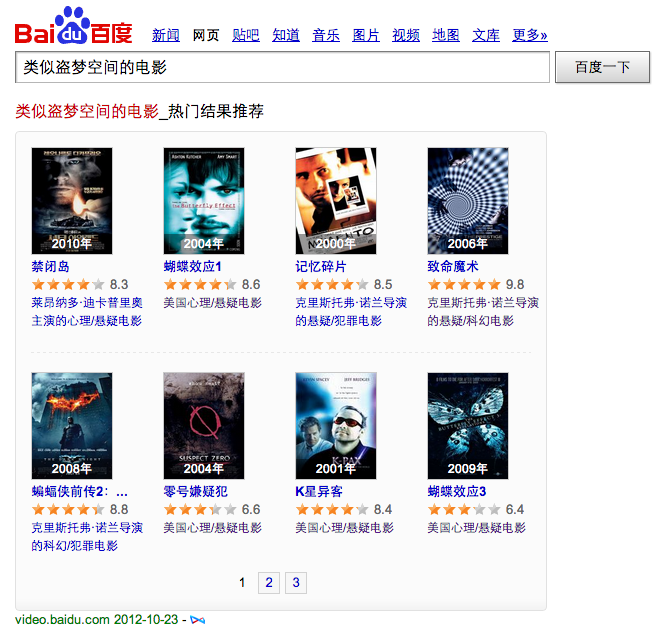
百度的结果是通过query直接触发,用「类似X的电影」这样的Query进行搜索,可得到关联推荐的结果。
类似盗梦空间的电影
实体搜索是相对于关键词(keyword)搜索而言的。传统的关键词搜索目前虽然已经可以达到很高的「智能」水平,搜索结果在很大程度上可以帮助用户找到需要的信息。但这一过程仍依赖于用户最终的人工选择,对于"搜索引擎"这个系统自身而言,其实并不能了解搜索 query 本身有什么意思。实体搜索关注的重点不再是「关键词」级别的信息, 而是"对象", 比如人、电影、软件、小说、公司、组织等等。从关键词向实体转化,可以从更精细的角度来理解和组织搜索结果。在一定程度上理解 query 的意思,可以直接给出答案。
实体搜索(entity search)这个概念并不是很新的东西,在学术界已经有了多年的技术积累。受制于大规模的资金人力投入,学术界主要关注于技术实现和应用,并未大规模投入到实体数据的建设上来。只有少量资金和技术都具备的巨头公司具有这方面的基础建设能力。实体搜索需要前期把大量的时间和精力投在建立实体信息数据(这里有很多不同的叫法, 比如 Ontology、Semantic Web 等等)。传统的 html并不是一个有效的信息载体,至少截至目前,主流的 html Tag 对于信息组织而言是没有实际意义的。结构化数据通过 html 展现出来以后,原有的属性信息都丢失了。 也许在数据库中,一部电影和导演的关系是可以通过关系数据库表体现出来的,但 html 中的标签是无法表示这种关系。
所以,对于搜索引擎而言,要从数据建设做起,基本上的通用做法大概分以下几个方面:
1) Web 实体属性的提取和消歧
2) 实体信息分类
3) 实体关系挖掘
基础数据既要保证信息覆盖的广度,同时还要有足够高的信息精度。
Google 和百度的数据层级对比来看:
*Google的实体资源覆盖面更广,包含了,人物,电影,书籍等多种实体信息,百度似乎只公开了电影类的资源。
*实体属性上百度做的略丰富一些,包含了电影情节等属性,Google这方面缺失。
*百度的实体关联这方面做的更深入,Google只能覆盖热门搜索的关联关系。基本上笔者实验的「类似X的电影」这类的搜索,都可以获得关联结果。
从目前这些「实体搜索」类的产品可以看出,实体基础数据已经达到了基本可用的状态,在产品应用上还有很大的潜力空间。特别是在更智能更个性化的使用场景下,比如:“好看的电影”、“适合公司聚餐的餐厅”等等。Siri等智能助手类的产品也依赖于底层实体数据和搜索技术的建设,未来搜索引擎公司在这个市场内应该会有不小的动作。同时,实体搜索作为一个高投入见效慢高风险的技术方向,如果能获得实质性的产品突破,会进一步强化各个领先搜索引擎的市场地位,这对于追赶者角色的其他搜索引擎公司而言不是一个好消息。


数据库相关的软件
华为云-云数据库 RDS for MySQL
- 4.3
(2)咨询产品免费试用悦数图数据库
- 4.3
(4)咨询产品免费试用滴普科技
- 4.3
(44)咨询产品免费试用



行业专家共同推荐的软件
PostgreSQL
- 4.3
(42)咨询产品免费试用MySQL
- 4.0
(30)咨询产品免费试用Snowflake
- 4.0
(41)咨询产品免费试用



限时免费的数据库软件
Redis
- 4.1
(31)咨询产品免费试用Microsoft Access
- 4.1
(27)咨询产品免费试用Quickbase
- 4.0
(40)咨询产品免费试用



新锐产品推荐
蓝海客服
- 4.2
(3)咨询产品免费试用18云办公
- 3.7
(4)咨询产品免费试用安宁邮件系统
- 0.0
(0)咨询产品免费试用Qualtrics CustomerXM
- 4.0
(1)咨询产品免费试用Freshworks CRM
- 3.9
(7)咨询产品免费试用蓝凌-电子采购平台
- 0.0
(0)咨询产品免费试用







