人工智能是学习的尚方宝剑还是“石中剑”?
编者按:本文来自芥末堆,作者:Jessie Chuang,36氪经授权发布。
过去,人们试图通过分析学生的学习行为数据,给予其个性化的学习指导。但是,由于数据搜集技术的局限性,导致数据的指导意义不够准确,商业化应用产值低。
近年来,随着技术的进步,以及资本市场的关注,教育科技产品呈现井喷式爆发,许多学习过程得以数字化,数据搜集变得更加简单。
大数据(Big Data)爆炸成长成为机器学习的养分。机器学习能获得充分的训练数据(training data) 与计算效能。人工智能产业(Artificial Intelligence,AI)经过一甲子的起落,终于因技术条件到位,开始突飞猛进。但是,单纯掌握某种数据,不能实现功能上的联动和数据共享,这种信息孤岛现象会成为人工智能发挥的最大阻碍。
什么是机器学习?
机器学习(Machine Learning)是人工智能的子领域。而常听到的深度学习(Deep Learning)则是机器学习中的一支。
人工智能的范畴,涵盖了所有尝试以电脑去模仿人脑处理信息的能力。例如:以电路设计或算法来模仿人脑神经元网络的运作;以程序模拟彼此互连的知识概念,如 Google 搜寻引擎的核心——知识图谱(Knowledge Graph);以及,让电脑能理解人类语言的自然语言处理技术(Natural Language Processing)等,都属于人工智能的范畴。模仿人脑思考能力的人工智能到目前为止,不算完全成功;倒是机器学习技术,因为上述原因,达到博闻强记,神速运算的效果,而异军突起。
机器学习大量使用统计的方法与推论,建立预测能力,让电脑或人类可以有效地即时采取行动。机器学习的核心,在于电脑能从收到的资料中学习,持续提升达成预设目标的能力(例如,专门推荐餐厅的应用),而不需依赖开发者不断下发指令。
今天,机器学习技术已经被广泛应用于各产业。以下是各种可能的能力,例如:购物网站根据使用者浏览行为与历史纪录,动态调整推荐商品;零售商店根据气候、季节、日期与地理位置等,计算各商品最佳定价;还有,人脸或图片辨识、手写输入辨识、语音辨识、自动过滤垃圾邮件、自动侦测信用卡盗刷、帮医生判读资料等。机器学习早已被广泛用在我们生活中,甚至你可能曾与人工智能客服交手过而不知道。
最引人关注的代表性事件包括 AlphaGo 战胜世界围棋冠军、自动驾驶汽车上路、IBM Watson 用于开发智能语音助理等。
如果将机器学习用在学习上,又有哪些可能呢?台湾大学林轩田教授团队 2010 年赢得 KDD Cup 冠军,题目是根据 3000 名学生回答数学题的 900 万条记录,预测个别学生是否能答对特定题目。这是一个容易理解的例子,也是一个非常清楚定义的问题。
人工智能成为热门话题,一般人以此用语统称,并不清楚其中各领域本质上的差异。组织主管看到别人挥着这把“尚方宝剑”,媒体文章说着:下一个十年的绝胜点在于掌握如何善用人工智能,内心多少有焦虑,希望就像电影里一样,一朝抢到尚方宝剑,就立于不败之地。教育培训科技产业人士对人工智能的期许,情形类似。
现今人工智能已逐渐像基础建设(例如:电力,水)一样可以接取使用,所以,许多人认为以上的期待并不遥远。没错,许多机器学习的计算能力已经透过程序接口(API)提供出来,例如:IBM 的 Watson、谷歌、微软、阿里云都有提供这类接口服务。
人工智能是尚方宝剑还是石中剑?
可惜现实世界是个复杂的系统,这不是 plug-and-play(即插即用)。
第一,如果你还没有明确定义的问题,人工智能对你是没用的。对这点事实,人类应该感到庆幸(不会被取代),机器人只能解决我们定义好而且适当建模的问题。各种算法就像用在不同场景的各种单一功能工具,依靠人类对关注的系统建立模型后,选择适当工具用在适当的环节,并需要实际数据来训练模型,调校与优化参数。数据越多,人工智能表现越好。有时因为情境或使用者的基础不同,可能需重新训练模型。
第二,如果你没有 (1)正确结构化(2)乾净(3)足够的 -- 数据(Data),幻想接上人工智能就会有神奇的效果,那是不可能的。
不准确的数据只会带来误判,资料科学家都知道整理资料经常花掉 80% 的时间,结构化的资料是为分析而设计过的资料格式,节省清理与汇整资料的时间,也与模型对接。模型要准,需要越多资料越好,所谓“足够”的资料,根据你定义的问题范围大小而定。
自适应技术在美国已逐渐导入各学习系统,有些正式评量也被采用,但为何还会出现成效不彰的反面案例呢?像所有工程系统一样,这些系统设计上有许多因子与参数,因各自设定不同,应用时最好能视需求让使用者调整部分参数。但在实际应用过程中,并非都有这种选项,结果不同系统效能自然相异。国外在学习场景导入这种系统,是经过好几年与教师密切沟通合作,才得以成功。另外,其应用场景需将内容放进该系统,如果学习发生在系统之外,则系统拥有的资料不够,效能当然大打折扣。
何谓足够的资料(数据)?
学习的趋势持续走向分散化、多元化、去中心化,一个系统不可能完全掌握学习者的足够资料,这些发生在多元应用里的学习经验,需要像 Experience API(xAPI) 接取多重资料流,实时汇整,才能解决信息孤岛(Data Silos) 问题。
另一个"足够"的层面是行为数据采集的维度,例如:做练习题,只有记录答对或答错,机器学习可以推测的范围极为有限(巧妇难为无米之炊);但是如果记录了答题花费的时间、尝试次数,那么机器可以知道这题对学习者是偏难或偏易,或他是不是猜对的,再据此推送适合该学生的题目(题目的难度标注或统计是另一个议题);如果题目有按需给出提示,则做题者是否使用提示,揭露了不同意义;还有,如果知道答题前发生的相关学习行为,则给机器提供了更好的建议根据;如果机器模型累积了过去大量成功学习者的路径,与当事者的过去记录进行对比,则可以形成绝佳建议根据;最后,如果有记录答题是在课堂上,与同学合作,在搭公车时,或在家时间发生,这些维度的数据都可以被用到。
xAPI 正是这样的工具,让我们采集丰富维度的行为资料,依据分析需求来设计数据结构。只要是数字系统,都可埋入 xAPI 进行行为数据采集,并不限于学习应用。
xAPI 的创新之处在于建立了独立于应用之外的数据层,用统一语言打通应用之间的信息壁垒。这个标准数据层不但人可读懂,机器也可读懂,所以机器能够自行推理。xAPI基于语义网技术(Semantic Web Technology,也称Web 3.0) – 这是万维网之父 Tim Berners-Lee 为将来万物互联环境智能化的愿景所主张之关键技术,现在工业 4.0 也是基于这种语义技术。 未来,机器可以从群众与内容的互动历程(也是群众智慧),自动萃取语义网连结的内容、学习路径、相关的人推荐给适合的人,xAPI 以 Key-Value 型态携带的情境、结果、环境、时间点等数据都可放进算法中。
xAPI 结合机器学习的应用案例
从下举几个使用 xAPI 进行行为数据采集,结合机器学习的案例。虽然不是直接的学习案例,但原理完全可以用在学习训练上。
改进网页布局与行销体验
网站为提升转化率,研究使用情境受到重视,一般透过运维管理(DevOps)改进网站使用体验。但是,网站浏览者使用情境多元,增添变数,为不同装置而设计的单页式与响应式设计,增加了分析情境的复杂度。原来透过 Google Analytics 分析使用者体验,但无法有效分析。
借助 xAPI 跨装置的特性搜集行为,能够掌握使用者的隐性及显性行为,凭借自适化的语意网页架构,让内容与布局分开储存,后台分析结果进行自动化调整(网页长度、设计、文案),最短时间呈现吸引访客的内容。结果 bounce rate 与 exit rate 明显下降了约40%,新页面推播点击率由 8% 提升至34%,来电成交率由 33% 提升至 53% 。(台湾大学 iCAN Lab 提供)
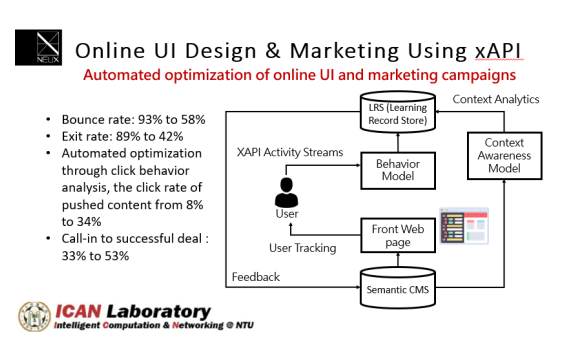
以 xAPI 采集行为结合机器学习技术提升网上行销转化率(来自iCAN Lab)
建立有情境感知能力的健康护理移动应用
脊椎损伤病患使用移动应用辅助复健运动与日常护理,但为减少这些病人操作应用的次数,建立能感知情境的智能引擎,持续收集病人的历程资料以及相关情境资料(时间、地点、装置...),并结合护理师所设计的处方,适时推荐适合病人当下的活动或提醒,更好地协助病患。
根据分析模型对资料进行结构化,xAPI 可以收集任何数字资料,包括生理数据,与传感器数据,越多资料则推荐引擎智能越高。xAPI 的跨装置特性,提升结构化资料汇流的效率。这个推荐介面降低病人需要手动操作应用的次数,实时自动推荐最适的活动给病人。(台湾大学 iCAN Lab 提供)
信息孤岛(Data Silos)是人工智能发挥的最大阻碍
数据(Data)是现代的石油,所谓数据寡头就是那些拥有大量数据而掌握知识经济的力量。在教育或培训领域,信息孤岛(Data Silos)才是人工智能发挥其力量的最大阻碍。你在其它领域看到的人工智能应用,尚未实践在学习上,或使用成效不彰,是因为没有足够的数据。单一功能的人工智能,例如,广泛应用在客服与行销的聊天机器人,载入学科知识,当然可以用在教育上,但仅止于知识问答(例:乔治亚理工学院利用IBM Watson 建立虚拟助教,回答事先建立好的Q&A);单一学科的自适应学习,尤以数学最成熟,但仍需控制学习完全发生在该应用内才有意义。
真正了解学习者的智能助理,那是完全另一个层次!学习场景多元化的今天,个人学习过程分散,机器要掌握足够数据才能建立智慧(较佳模型与推荐),整合打通多维度的行为数据,才可能建立无缝的智能化学习环境。没有数据策略,你还离人工智能很遥远。现在就从可行的范围做起。


AI人工智能相关的软件
来画视频
- 3.7
(41)咨询产品免费试用火眼审阅
- 3.6
(5)咨询产品免费试用火山引擎·机器学习平台
- 5.0
(1)咨询产品免费试用



行业专家共同推荐的软件
美摄科技
- 3.8
(6)咨询产品免费试用Phrase TMS
- 4.0
(40)咨询产品免费试用UbiTrack多维高精度定位系统
- 5.0
(2)咨询产品免费试用



限时免费的AI人工智能软件
Transifex
- 4.5
(40)咨询产品免费试用火龙果写作
- 5.0
(1)咨询产品免费试用Copy.ai
- 4.4
(40)咨询产品免费试用



新锐产品推荐
趣练习
- 4.0
(1)咨询产品免费试用鱼塘微客服系统
- 3.5
(3)咨询产品免费试用茧数SCRM
- 2.5
(1)咨询产品免费试用国鸣AI智校系统
- 0.0
(0)咨询产品免费试用百居易
- 0.0
(0)咨询产品免费试用进群宝
- 0.0
(0)咨询产品免费试用