旷视为何加入“开源之战”?
编者按:本文来自微信公众号“燃财经”(ID:rancaijing),作者:金玙璠,36氪经授权发布。
过去两年里被冷落的人工智能产品和技术,在这场疫情中被证明不是花架子。
市场基于此调整了对2020年人工智能市场规模的预测,据中国信息通信研究院统计预测数据显示,2020年全球人工智能市场将达到6800亿元人民币,复合增长率达26.2%,而中国人工智能市场在2020年也将达到710亿元人民币,复合增长率达44.5%。
突发的疫情,加速了人工智能在医学、疫情管控等方面的落地,但也暴露出“偏科”的问题。整体来看不难发现,AI化虽然迅猛,但是马太效应明显,互联网巨头和人工智能明星企业往往占据资源优势或专业性,而对于想借AI升级的企业而言,框架的产生大大降低了门槛。
不过当前主流的开源深度学习框架只剩下Google的TensorFlow和Facebook的PyTorch,且国内的开发者高度依赖国外的开源框架。
国内不少企业都意识到了这一问题,陆续拿出本土化的解决方案,百度有PaddlePaddle,华为即将开源MindSpore,昨日(3月25日),国内计算机视觉企业旷视宣布,开源基于AI生产力平台Brain++的深度学习框架天元(MegEngine)。
据媒体报道,旷视最近获准在香港进行IPO,对此,旷视方面对燃财经回应,“在(稳步)进行中”。作为开源框架阵营里第一家原本就是做人工智能产业应用的公司,旷视准备怎么讲这个故事?
01 框架让AI去成本中心化
“虽然旷视做过的算法可以数以百计,但是场景的无限性导致市场对算法的需求也是无限的。而仅凭旷视一家公司是做不出来这么多东西的,所以需要有好的AI基础设施帮助旷视这样的公司,也来帮助更多的人创造出更多的算法。”旷视联合创始人兼CTO唐文斌在发布会上说。
事实上,在1956年以前,人工智能就已经开始孕育,但真正让它为大众所熟知,还是2012年前后深度学习的发展,后者的出现带领整个行业进入了“拐点期”。
首先捋顺一下两者之间的关系。
人工智能(Artificial Intelligence)的目的是让计算机这台机器能够像人一样思考。机器学习(Machine Learning)是人工智能的分支,也是发展最快的分支之一,就是通过让计算机模拟或实现人类的学习行为来解决问题。深度学习(Deep Learning)是一种机器学习的方法,它的出现告别了人工提取特征的方式,是通过在设计上借鉴人类大脑视觉信息分层处理的过程,对数据进行高层抽象的算法。
理论上,只要计算机运算能力足够强、样本数据量足够大,就可以不断增加神经网络的层数、改变神经网络的结构,深度学习模型的效果就会有显著提升。
也就是说,大数据的发展促进了深度学习的崛起,深度学习的方法又最大限度地发挥了大数据的价值,两者相辅相成。尤其是在语音识别、图像识别这些人工智能行业首先落地的领域,深度学习因为商业落地过程中的数据反哺,带动了算力、框架的一步步升级。
处理大量数据,需要足够的运算能力,而近十几年里,计算机硬件性能的提升、云计算、分布式计算系统的发展,就为深度学习提供了足够的算力。
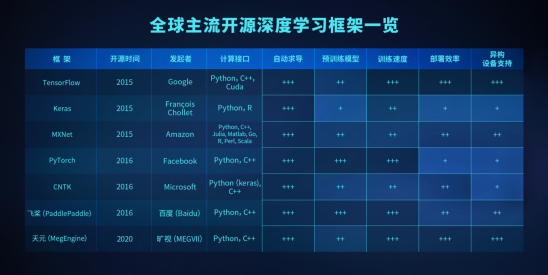
在深度学习领域,有五大巨头,它们有各自的深度学习框架,Google有自家的TensorFlow、Facebook有PyTorch、百度有Paddle Paddle、微软有CNTK、而亚马逊的AWS则有MXNet……
数据、算法、深度学习框架之间的关系,简单来说就是,做算法如同炒菜,数据是各种各样的食材,需要清洗,分类管理,是炒菜(做算法)的原材料,而算法的训练就像是烹制的过程,需要一口好锅(深度学习框架)来承载。强大的算力对于做算法来说是一灶猛火,至于饭菜烧得如何,一定程度上也取决于火候的控制。上等的食材,再加上好锅,配上猛火,就能炒出一盘好菜。

同理,标准化、流程化的数据管理、高效的深度学习框架和强大的算力才能研发出好用的算法。
其中深度学习框架的出现,大大降低了开发者入门的门槛,它是帮其进行深度学习的工具,简单来说,就是编程时需要的库。开发者不需要从零开始去写一套机器学习的算法,可以根据所需,使用框架中已有的模型,直接进行组装,但组装方式取决于开发者;也可以在已有模型的基础上增加层(layer),训练自己的模型。
对于算法生产者而言,框架可以规模化生产算法,同时尽可能降低数据源成本和算力消耗(云服务成本)。好用的开发工具,可以让开发者在算法训练的过程中告别手工时代,就像联合收割机之于农民,原来十个人用镰刀锄头只能收割一块地,而自动化、现代化的收割机可以让一个人就完成十块地的收割。
其实,云服务的成本相对可控,另外作为人工智能算法优化中必要的数据集,当数据量越多,训练出来的算法质量也就越高,当越来越多场景使用高质量算法的时候,产生的商业价值就越大,数据集的获取成本分摊下来也会越低。这意味着,对于想借人工智能升级的企业而言,框架的产生可以让人工智能去“成本中心化”。
回顾过去三四年人工智能的发展历程,它正在加速各行各业的商业创新,逐渐渗透到零售、教育、通讯、金融、公共事业、医疗、智慧城市等领域。但不难发现AI化虽然迅猛,但马太效应明显,互联网巨头和人工智能明星企业往往占据资源优势或专业性。而传统行业在人工智能落地过程中,挑战重重,高研发投入、复杂的算法工程,成为负担。
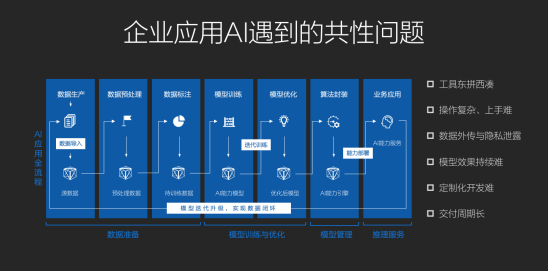
而人工智能领域有顶尖的科学家奋斗在算法模型研究的第一线,也有大批厂商努力推广标准化机器学习的算法,客观上降低了人工智能算法的开发成本,让各行各业的企业能够专注于上层业务逻辑。但对于传统企业来说,建立AI研究院、从0到1地进行算法开发根本不现实。
02 AI能改变什么?开源框架正在提供更多选项
AI会改变哪些行业,答案也许是各行各业。
尽管人工智能从2012年就因深度学习引入而开始新一轮爆发,国内人工智能领域的投资在2014年开始升温,但那时候大多数投资机构和公众还看不懂人工智能。
因为2016年的一场棋局(AlphaGo战胜了李世石),人工智能正式闯入大众视野,成为当时全球讨论最热烈的公共事件之一。投资人开始研究AI,拿着钱找AI团队,国内互联网界的名人都在各种会议上布道AI。算法竞赛开始火热,学校开设的人工智能、数据挖掘相关的课程被学生选爆,大批“算法工程师”涌入行业。
根据乌镇智库发布的报告,2014年至2016年,中国人工智能产业年度投资频次从近100次增长至近300次,融资规模从约2亿美元增加至16亿美元,涨幅分别达到近3倍和8倍。
这些数字开始引发市场对行业“过热”的担忧。与此同时,2018年资本寒冬开始来临,包括人工智能领域在内的投资都变得冷静。温度降下来以后,外界开始把焦点放在人工智能公司的赚钱能力上。
时间来到2019年,人工智能保持了十九年的融资总额飙升,在这一年急转直下。猎豹全球智库统计分析,自2000年以来,人工智能企业的融资数量已持续18年上涨,在2013年至2018年出现大爆发,融资金额和数量直线飙升,且2014年后这一数据还以接近50%的幅度在增长;但2019年成为分水岭,与上一年相比,融资总金额下滑34.8%(从1484.53已下滑至967.27亿),融资数量下滑4成(从737下降至431)。
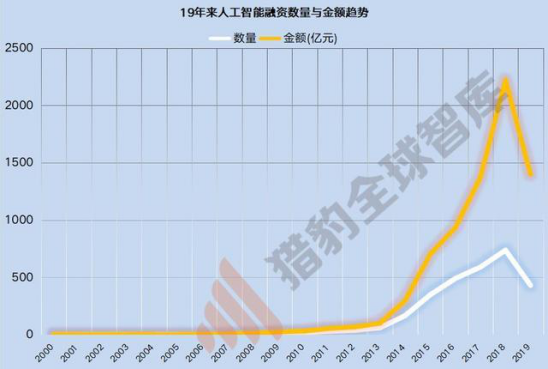
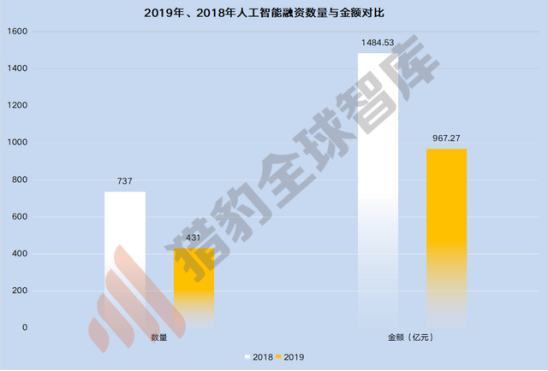
这一年成为公认的人工智能寒冬年,人工智能资本市场开始趋于冷静,人工智能产业也进入”去伪“阶段,没有核心技术却想在风口淘金的冒险者知难而退。但回顾近几年,人工智能被质疑的核心无非是发展不及预期。而回看上一次技术革命,改变我们人类生产生活的,不是蒸汽机本身,而是以蒸汽为动力的纺纱机、火车、轮船等,但是目前来看,深度学习远没有足够多的落地方向,所谓的行业前景也难以证实。
从另一个角度看这个问题,几十年前,各大计算机厂商积极构建各自的生态系统,迎来了蓬勃的信息化革命,如今我们所处的,是以深度学习为主力的这一波人工智能浪潮。那么既然神经网络的应用在人脸识别等领域已经基本落地,剩下的工作应该侧重于目前商用并不理想的领域,需要的人才也不再是深度学习的算法科学家或工程师,而是在业界懂得深度学习的软件工程师、硬件工程师以及机械工程师。
这就需要深度学习像编程一样被普及,而不是束之高阁。事实上,基础的平台和工具,也就是框架,也已由从学术界走出的Caffe、Torch和Theano作为基石,到现在产业界以科技巨头为领导的TensorFlow们为主。
从全球范围看,人工智能的格局还不明朗,不过玩家们主要分成三个派系。
第一类是系统应用派,典型代表是Google和Facebook,开发出了人工智能的系统级框架,比如Google的人工智能框TensorFlow、Facebook的PyTorch,且大规模投入应用。第二类是芯片派,重要玩家就是英特尔和英伟达,主要提供算法支持。第三类是技术应用派,目前大多数所谓的人工智能公司都属于这一派别。
而从框架越来越对应生产、工业应用这个趋势来看,行业正在回答“AI能为我们做什么”的问题。
03 旷视为什么加入开源深度框架之战
深度学习框架的竞争,已经成为人工智能场上竞赛的制高点。这也是为什么总有厂商愿意投入大量资源,去设计新的框架试图解决这些缺点,更重要的是争取深度学习的标准,借此向下对接芯片,向上支撑各种应用,拓展领地。
不过当前主流的开源深度学习框架只剩下Google的TensorFlow和Facebook的PyTorch,两者占据了大部分市场份额。前者在2012年前后诞生,随后凭借性能稳定与安全牢牢占据着工业界,Google希望通过框架开源让更多用户企业、用户绑定自身的基础性产品,芯片以及搭载芯片的云服务,从框架向底层设施发展。后入者PyTorch通过操作简单、灵活在学术界撕开一道裂缝,与前者也逐渐趋同。
长江商学院经济学教授、人工智能与制度研究中心主任许成钢在2019年初的一次分享中总结,中国在最近三年里,关注人工智能开源软件包的总数迅速上升,并在2017年秋超过了美国;但是,几乎93%的中国研究者使用的人工智能开源软件包,是美国的机构开发提供的;中美两国人工智能研究者使用最多的软件包是Google开发的TensorFlow。
开源软件包,是衡量人工智能研发程度的指标。在人工智能领域,芯片代表了算力,智能框架代表了算法,算法和算力是两大基石,如果国内的开发者高度依赖国外的开源框架,相当于被“卡住了脖子”。
类似情况在芯片领域发生过。2015年,国防科技大学主导的超级计算机“天河二号”,因为英特尔断供超级计算机芯片,不得不打断原定的升级计划,直到在2018年借助中国自研的Matrix-2000 加速卡才完成升级。
国内不少企业都意识到了这一问题,陆续拿出本土化的解决方案。百度在2016年下半年开源了PaddlePaddle,华为在去年8月表示计划在2020年Q1将MindSpore开源。3月25日,旷视宣布开源其AI生产力平台Brain++的核心深度学习框架天元MegEngine,同时将Brain++这个产品向企业用户开放。
既然框架都是开源的,那国内科技还需要重复自研吗?
答案是肯定的。因为人工智能不是象牙塔里的理论,是必须面向真实场景,作用于实际业务的应用,将深度学习框架开源的科技企业,都有各自独特的业务场景与问题。(百度)PaddlePaddle在自然语言处理方面有长足的积累,(华为)MindSpore更强调软硬件协调及移动端部署的能力,而(旷视)天元MegEngine则强调训练推理一体化和动静合一,且兼容PyTorch。
开源的目的,是在商业化过程中,以一个结构化的、开放的底层系统,去同时兼容存量市场和新增需求,降低客户和合作伙伴的使用门槛,加强企业在业务横向拓展中的产品化能力,也是决定企业今后毛利率的关键。
唐文斌当天表示,人工智能行业是分层的,旷视从早期计算机视觉的算法层向上,进入到了应用层,提供了如机器人操作系统河图、城市管理操作系统等数字化中台或硬件中台,但是发现有限的算法在场景中有局限性,场景中层出不穷的新的问题需要新的算法来解决,因此团队计划先解决底层基础设施建设的问题。
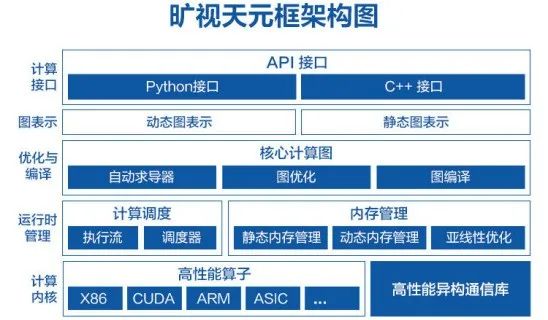
在去年的世界互联网大会上,旷视发布了围绕算法、算力和数据三位一体的AI生产力平台Brain++,主要包括三部分:作为主体的深度学习算法开发框架 MegEngine ,提供算力支持的 MegCompute,提供数据支持的 MegData。
据燃财经了解,MegEngine这个框架始于旷视成立早期(2014年),是搭建Brain++的核心引擎,当时因为人工智能开发工具匮乏自己形成了一套打法,近些年伴随计算机视觉方面业务场景的累积,不断进化,比如引进 AutoML(Automated Machine Learning,自动机器学习)技术,让算法训练算法,以减少人力。
“旷视现在几乎所有AI产品都是基于它构建。” 旷视研究院高级技术总监田忠博表示。

“我们这次开源的代码大概有35万行。大家可以放心的使用,包括在一些商业的场景下使用它都没有问题。”在唐文斌的介绍里,天元MegEngine是一个训练推理一体化、动静态合一的工业级深度学习框架。
“训练推理一体化”是指,整个框架既可用于训练又同时支持推理,实现模型一次训练,多设备部署,避免复杂的转换过程造成的性能下降和精度损失。
深度学习框架大致分为两类,一类是以TensorFlow为代表的静态深度学习框架,它更容易部署,能够快速产出产品,是现在工业界非常喜欢的部署方式,它的性能高,占用的资源少,但是难以调试;而学界更喜欢以PyTorch为代表的动态计算框架,因为在研究阶段调试更加方便,使用起来更加灵活。田忠博展示了MegEngine框架代码中从动态对静态切换的情况。
到目前为止,旷视是开源框架阵营里,唯一一个原本就是做人工智能产业应用的公司,和通用的深度框架相比,天元MegEngine更垂直于计算机视觉应用。
旷视方面表示,这是一个完全由国人自主研发,经过旷视6年真实工业场景验证的框架。当然,天元能不能成为下一个TensorFlow和PyTorch,还需要时间给我们答案。
*题图来源于视觉中国。


AI人工智能相关的软件
来画视频
- 3.7
(41)咨询产品免费试用火眼审阅
- 3.6
(5)咨询产品免费试用火山引擎·机器学习平台
- 5.0
(1)咨询产品免费试用



行业专家共同推荐的软件
美摄科技
- 3.8
(6)咨询产品免费试用Phrase TMS
- 4.0
(40)咨询产品免费试用UbiTrack多维高精度定位系统
- 5.0
(2)咨询产品免费试用



限时免费的AI人工智能软件
Transifex
- 4.5
(40)咨询产品免费试用火龙果写作
- 5.0
(1)咨询产品免费试用Copy.ai
- 4.4
(40)咨询产品免费试用



新锐产品推荐
豌豆荚
- 3.9
(5)咨询产品免费试用CAN广告投放平台
- 0.0
(0)咨询产品免费试用穿山甲-广告投放
- 0.5
(1)咨询产品免费试用缩我短链接
- 4.6
(3)咨询产品免费试用云拓
- 4.7
(2)咨询产品免费试用目睹
- 3.5
(26)咨询产品免费试用







