人工智能革命:为什么深度学习会突然改变你的生活?(上)
编者按:过去4年,大家无疑已经注意到大范围的日常技术在质量方面已经取得了巨大突破。这背后基本上都有深度学习的影子。到底什么是深度学习?深度学习是如何发展到今天的?这一路上它都经历了哪些关键时刻?Roger Parloff的这篇深度学习简史可以让我们全面了解。鉴于篇幅较长,我们分上下两篇刊出,这是上篇。
过去4年,读者无疑已经注意到大范围的日常技术在质量方面已经取得了巨大突破。
其中最明显就是我们智能手机上的语音识别,它的功能已经比过去好得多了。当我们用语音命令打电话给配偶时已经能联系上对方了。因为接线的不是美国铁路局或者愤怒的前女友。
实际上,我们现在越来越只需跟计算机讲话就能实现互动,对方也许是Amazon的Alexa,苹果的Siri,微软的Cortana或者Google的众多语音响应功能。百度称,过去18个月其客户语音接口的使用量已经增至原来的3倍。
机器翻译等其他形式的语言处理也变得更加令人信服,Google、微软、Facebook和百度每月都会get√新的技能。Google翻译现在为32个语言对提供语音翻译,为103种语言提供文本翻译,其中不乏宿务语、伊博语、祖鲁语等略微生僻的语言。Google的收件箱现在已经为所有来信准备了3种回复。
然后还有图像识别方面的进展。上述4家公司都有无需识别标签即可让你搜索或者自动组织相片集的功能。你可以要求把有狗、有雪的照片都显示出来,甚至连拥抱这样相当抽象的概念也难不倒它。这些公司还都在做类似的产品原型,可以在数秒钟之内生成句子长度的照片描述。
想想吧。要想收集有狗的照片,app必须识别很多种狗,从吉娃娃到德国牧羊犬,而且无论照片是倒置还是部分模糊,无论是在左边还是右边,不管是大雾还是下雪,是阳光普照还是在林荫底下,app都不应该识别不出小狗。与此同时还得排除掉狼和猫等。光靠像素的话这怎么可能做到呢?
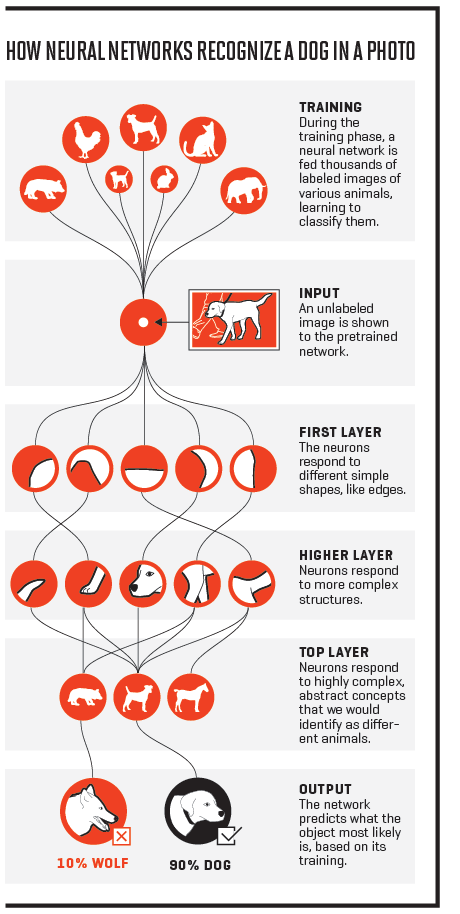
人工神经网络如何识别照片中的小狗。1)训练阶段会提供大量带标签的各种动物图像给神经网络,让后者学会进行分类;2)输入:提供一张不带标签的图片给经过训练的神经网络;3)第一层:神经元对不同的简单形状如边缘进行响应;4)更高层:神经元对更复杂的结构进行响应;5)顶层:神经元对我们会识别为不同动物的高度复杂、抽象的概念进行响应。
图像识别的进展远不仅限于那些看起来很酷的社交app上。医疗初创企业宣布它们很快就可以用计算机来读X光片、MRI(核磁共振图像)以及CT扫描,而且跟放射科医生相比,它们不仅速度更快结果还更加精确,可以更早创伤更少地诊断癌症,并且加速拯救生命的药物的寻找工作。更好的图像识别对于机器人学、无人机以及无人车(福特、Tesla、Uber、百度、Google等都在路测自己的无人车原型)等方面的技术改进至关重要。
但大多数没有意识到的是,所有这些突破在本质上其实都是同一个突破。它们都是靠一组热门人工智能技术取得的,这种技术的名字叫做深度学习,但大多数科学家更愿意用它最初的学术名称:深度神经网络。
神经网络最引人瞩目的点是计算机并没有经过任何的人工编程即可实现上述功能。当然,实际上也没有人能够通过编程来实现那些功能。程序员只是给计算机提供了一种学习算法,让它观察上TB的数据——也就是训练计算机,让它自行找出如何识别所需对象、单词或者句子的办法。
简而言之,现在这些计算机可以自学了。Nvidia CEO 黄仁勋说:“基本上这相当于写软件的软件。” Nvidia是图形处理器的市场领导,在5年前开始大规模押注于深度学习。
神经网络并不是什么新事物。这一概念最早可以追溯到1950年代,而许多的关键算法突破试着1980年代和1990年代才取得的。变的是现在的计算机科学家终于有了海量的计算能力,以及庞大的数据仓库——互联网上充斥着各种图像、视频、音频以及文本文件——结果表明,这些东西对于跑好神经网络必不可少。VC机构A16Z的合伙人Frank Chen说:“这就是深度学习的寒武纪大爆发。”他用大部分较为高等的动物突然出现的地质时代来类比深度学习取得的进展。
这一飞速发展激发了一系列活动爆发。据CB Insughts的数据,上季度对AI初创企业的股权融资达到了10亿美元的历史新高。2016年Q2共进行了121轮相关初创企业融资,相比之下2011年同期只有21起。在此期间,AI方面的投资超过了75亿美元——其中超过601亿美元是2014年以来进行的。(9月末,AI的5大巨头——Amazon、Faebook、Google、IBM以及微软成立了非盈利的AI组织,旨在推动公众对该话题的理解,并就相关的道德和最佳实践开展研究)
2012年时Google开展的深度学习项目只有2个。据一位发言人表示,现在它正在推进的相关项目已超过1000个,涵括了包括搜索、Android、Gmail、翻译、地图、YouTube以及无人车在内的所有主流产品范畴。IBM的Watson也应用AI,但它2011年击败两位Jeopardy智力竞赛人类冠军时用的不是深度学习。不过据Watson CTO Rob High说,现在Watson几乎所有30项服务都已经增加了深度学习能力。
5年前几乎还不知道深度学习是什么的VC,现在个个对没有这项技能的初创企业都非常谨慎。Chen观察到:“我们已经处在这样一个时代,即开发复杂软件应用已经成为必须。”他说大家很快就会需要软件这样:“‘你的自然语言处理版(软件)在哪里?’‘我怎么才能跟你的app对话?因为我不想通过菜单点击。’”
一些公司已经在把深度学习集成进自己的日常流程当中。微软研究院负责人Peter Lee说:“我们的销售团队正在利用神经网络推荐该联络哪一位潜在客户,或者作出什么样的产品推荐。”
硬件界已经感受到这种震动。让所有这一切成为可能的计算能力发展不仅仅是得益于摩尔定律的延续,而且还有2000年代末Nvidia做出图形处理器的帮忙——这种强大的芯片原本是为了给玩家提供丰富的3D视觉体验——但大家意外发现,在深度学习计算方面,其效率要比传统CPU高出20到50倍。今年8月,Nvidia宣布其数据中心业务的季度收入与去年同比已经翻了一番多,达1.51亿美元。其CFO告诉投资者“目前为止绝大部分增长来自于深度学习。”在时长83分钟的电话会当中,“深度学习”这个词就出现了81次。
芯片巨头英特尔也没有闲着。过去2个月它一口气(以超过4亿美元)收购了Nervana Systems和Movidius(价格未披露),这两家公司的技术都是针对不同阶段的深度学习计算量身定制的。
至于Google,今年5月,它披露了自己已经秘密采用自行设计的定制芯片TPU(Tensor Processing Unit)一年多了,这种芯片正是给经深度学习训练的应用使用的。(Tensor是类似矩阵一样的数组,在深度计算中往往要进行相乘运算)
的确,企业可能已经到达了另一个拐点。百度首席科学家吴恩达说:“在过去,许多标普500强CEO希望自己能早点意识到互联网战略的重要性。我想从现在开始的今后5年也会有一些标普500强CEO后悔没有早点思考自己的AI战略。”
其实在吴恩达看来,互联网这个比喻已经不足以形容AI及深度学习的隐含意义。他说:“AI就是新的电力。仅仅100年前电力变革了一个又一个行业,现在AI也会做同样的事情。”
可以把深度学习视为一个子集的子集。“人工智能”涵括的技术范围很广——比如传统的逻辑学、基于规则的系统——这些能帮助计算机和机器人至少用类似思考的方式解决问题。在这个领域里面还有一个更小一点的类别叫做机器学习,这是一整个神秘但又重要的数学技术工具箱的总称,它可以帮助机器改进需要经验的任务表现。最后,在机器学习这个门类当中还有一个更小的子集叫做深度学习。
吴恩达说,我们可以把深度学习看做是“从A到B的映射。你可以输入一段音频剪辑然后输出脚本。这就是语音识别。”他强调,只要你有可以训练软件的数据,就有无限可能:“你可以输入电子邮件,而输出可以是:这是否垃圾邮件吗?”输入贷款申请,输出可能是目标客户偿还贷款的可能性。输入车队的使用模式,输出可以是发车去到哪里的建议。
人工智能术语表
人工智能
AI是个广义概念,用于任何让计算机模仿人类智能、利用逻辑、假定规则、决策树以及机器学习(含深度学习)的技术
机器学习
含有深奥的统计技术的AI子集。这种统计技术可让机器改进需要经验的任务。深度学习属于机器学习。
深度学习
机器学习子集包括了让软件可以训练自己执行任务(如云和图像识别)的算法,手段是让多层神经网络接受海量数据。
在这样的愿景下,深度学习几乎可以变革任何行业。Google Brain项目负责人Jeff Dean说:“将会发生的根本性改变是现在计算机视觉真正可以工作了。”或者用他的话说:“现在计算机已经睁开了它们的眼睛。”
这是否意味着是时候拥抱“奇点”了呢?(所谓奇点是指这样的一个假设时刻,到那时超智机器将可以在无需人类干预的情况下自我改进,从而引发一个逃逸周期,导致进化缓慢的人类被抛开得越来越远,产生恐怖的后果)
还没有。神经网络擅长模式识别——有时候表现得跟我们人类一样好甚至更佳。但它们不懂推理。
即将发生的革命的第一个火花是在2009年开始闪烁的。那年夏天,微软研究院邀请了神经网络先驱,多伦多大学的Geoffrey Hinton前往参观。由于对他的研究感到印象深刻,Lee的团队开始试验用神经网络进行语音识别。Lee说:“我们被结果惊到了。我们用非常早期的原型就实现了精确度提高30%。”
据Lee说,2011年,微软把深度学习技术引入到自己的商用语音识别产品上。2012年,Google开始跟进。
但是真正的转折点发生了2012年10月。在意大利佛罗伦萨的一场研讨会上,斯坦福AI实验室负责人,著名的计算机视觉竞赛ImageNet创始人李飞飞宣布,Hinton的两位学生已经发明了一种软件,这种软件识别对象的精确率几乎是最接近对手的2倍。Hinton认为“这是一个非常惊人的结果,令此前许多对此表示质疑的人都信服了。”(去年的竞赛上一家深度学习的参赛选手已经超越了人的识别率。)
攻破图像识别打响第一枪,这激起了一场人才争夺战。Google把Hinton和赢得那场竞赛的两名学生都请了过来。Facebook签下了法国的深度学习创新者Yann LeCun,他在1980年代和1990年代是赢得ImageNet竞赛的某种算法的先驱。而百度则抢下了吴恩达。吴曾是前斯坦福AI实验室的负责人,2010年曾帮助推出并领导了以深度学习为核心的Google Brain项目。
此后这场人才争夺战开始变本加厉。微软研究院的Lee说,今天“这个领域正在上演一场抢夺人才的血腥战争。”他说这方面顶级人才的报价“堪比一线的NFL选手。”
现年68岁的Geoffrey Hinton是在1972年的时候第一次听说神经网络的,当时他正在爱丁堡大学做人工智能方向的毕业设计。在剑桥大学学习了实验心理学之后,Hinton开始狂热地恋上了神经网络,这是一种灵感源自大脑神经元工作方式的软件设计。在当时,神经网络还没有得宠。他说:“每个人都认为这种想法疯了。”但Hinton仍然坚持他的努力。
神经网络有望让计算机像小孩一样从经验而不是通过人工定制编程的繁杂指令来学习。他回忆道:“那时候大部分的AI都是逻辑启发的。但逻辑是大家很晚才学会的东西。2、3岁的小孩是不懂逻辑的。所以在我看来,就智能的工作方式而言,相对于逻辑,神经网络是一种要好得多的范式。”
在1950和1960年代,神经网络在计算机科学家当中非常流行。1958年,康奈尔大学心理研究学家Frank Rosenblatt在一个项目中首次搭建了神经网络原型,他把这个得到海军资助的项目叫做Perceptron。项目使用的穿孔卡片计算机体型巨大,占满了整整一个房子。经过50次试验之后,它学会了区分在左右侧做记号的卡片。当时的《纽约时报》是这么报道此事的:“海军披露了一台电子计算机的雏形,将来这台计算机预期可以走路、说话、写字以及复制自己,并且能意识到自己的存在。”
结果证明,软件只有一层神经元式节点的Perceptron能力有限。但是研究人员认为,如果是多层,或者叫做深度神经网络的话就可以实现更多的东西。

1958至1986,深度学习的关键时刻:1)1958年,Frank Rosenblatt披露了单层神经网络Perceptron 2)1969年,AI大牛,MIT的Marvin Minsky合著了一本书,对神经网络的可行性提出质疑,神经网络开始失宠。 3)1986年,神经网络先驱Geoffrey Hinton等人找到了训练多层神经网络纠正错误的办法,重新点燃了业界对此的热情。
人工智能革命:为什么深度学习会突然改变你的生活?(下)



AI人工智能相关的软件
来画视频
- 3.7
(41)咨询产品免费试用火眼审阅
- 3.6
(5)咨询产品免费试用火山引擎·机器学习平台
- 5.0
(1)咨询产品免费试用



大厂都在用的AI人工智能软件
美摄科技
- 3.8
(6)咨询产品免费试用Phrase TMS
- 4.0
(40)咨询产品免费试用UbiTrack多维高精度定位系统
- 5.0
(2)咨询产品免费试用



限时免费的AI人工智能软件
Transifex
- 4.5
(40)咨询产品免费试用火龙果写作
- 5.0
(1)咨询产品免费试用Copy.ai
- 4.4
(40)咨询产品免费试用



新锐产品推荐
智擎人工智能云平台
- 0.0
(0)咨询产品免费试用奇酷方舟
- 0.0
(0)咨询产品免费试用AI绿洲平台
- 3.8
(2)咨询产品免费试用数说聚合
- 4.7
(2)咨询产品免费试用开放智能
- 0.0
(0)咨询产品免费试用神目AI
- 0.0
(0)咨询产品免费试用







