微软亚洲研究院谢幸:如何让机器拥有像人一样的思维?
编者按:本文来自微信公众号“微软研究院AI头条”(ID:MSRAsia),作者 谢幸。
机器能否进入人类内心深处去了解她们的性格和情感呢?这些问题在心理学领域已经被思考了上千年。日前,微软亚洲研究院资深研究员谢幸受邀在剧院式演讲平台“造就”上发表主题演讲《如何让机器拥有像人一样的思维》。我们整理了谢幸的演讲视频及演讲内容,全文如下。
大家好,我是微软亚洲研究院的谢幸。今天我想和大家探讨的是,“如何让机器拥有像人一样的思维”。
进入正题之前,我先讲一个我自己的故事。最近,我给我三岁的女儿买了一本绘本,名字是“Can I build another me”,她爱不释手。这本书的主角是一个厌倦了自己规律生活的孩子,他希望能训练出一个机器人代替自己按时午睡、吃饭、去幼儿园,这样他就可以自由自在地玩耍。于是,他买来一个最便宜的机器人,带回家来训练它。在这个过程中,他遇到的第一个问题就是,怎样才能让机器人才能变成他呢?于是,他试图告诉机器人各种关于自己的信息,包括他的姓名、年龄、身高、体重,父母、兄弟和宠物,甚至包括“左撇子”“易烦躁”“袜子经常破洞”这种信息。
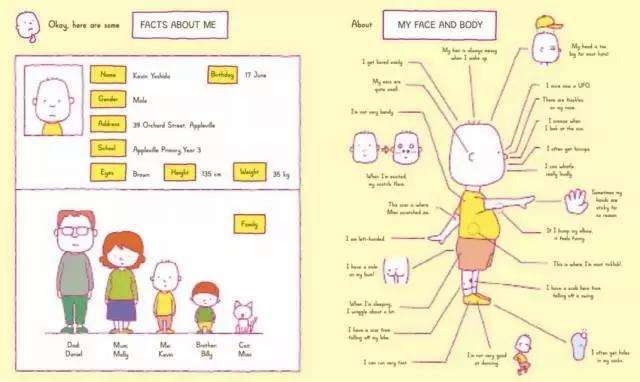
我发现这绘本的作者脑洞很大,他也在思考我们所思考的问题。这个故事也告诉我们,要让机器人拥有人一般的思维,第一步便是理解自己。因为这样我们才能告诉机器人,怎样做才能最像自己。今天,我将从以下几个方面与大家探讨这个问题:
人工智能与心理学
人格分类及推测
如何让机器人像人一样思考
在很长一段时间内,我们团队一直从事用户画像的研究。什么是用户画像?简单说来,就是通过用户产生的大数据,去猜测和理解一个人的年龄、职业、兴趣爱好,也可以去描绘一群人的生活规律和移动模式。这让我们开始思考,我们能不能通过这些数据进一步走到人的内心深处,去了解她们的性格和情感呢?这并不容易。但是在研究的过程中,我们发现这些问题在心理学领域已经被思考了上千年。实际上,人工智能和心理学这两个领域实际上早就有交叉。
人工智能的早期开拓者之一,Herbert A. Simon,是著名的跨界学者。他既是计算机科学家,也是心理学家,是经济学家,还是社会学家,甚至还是认知科学家。让人惊叹的是,他在每个领域都取得了同样卓越的成绩:他获得了1975年的图灵奖、1978年的诺贝尔经济学奖、1986年的美国国家科学奖章,及1993年美国心理学会的终身成就奖。右边这位是多伦多大学的Geoffrey E. Hinton教授,深度学习的积极推动者。他既是计算科学家,同时也是一位心理学家。

两年前,我们便开始拜访著名的心理学家和教授,试图进行跨学科合作交流。在这个过程中,我们首先想解决的问题就是人格。从用户生成的大数据中能否计算出人的性格?
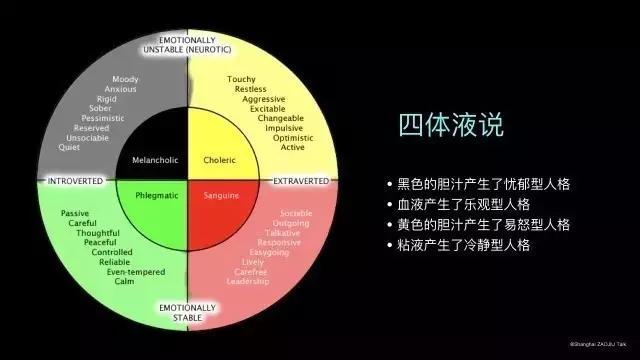
虽然人格这个术语在日常生活中很常见,但是给人格下一个准确清晰的定义却并非易事,即使是心理学家们在这个术语的定义上也很难达成共识。人格最早的定义可以追溯到2000多年前(公元前400年)古希腊医学家希波克拉底(Hippocrates)的体液说,他认为人体是由四种体液构成,包括血液、粘液、黄胆汁和黑胆汁,而这四种体液的分布便决定了人的性格:黑色的胆汁产生了忧郁型人格,血液产生了乐观型人格,黄色胆汁产生了冲动易怒型人格,而粘液产生了冷静型人格。尽管希波克拉底的体液说已经被现代医学所否定,但是他关于人格分类的探讨是有启发意义的,以致于后来的心理学家仍然一直探讨这个问题。
在我们与心理学家交流时,我们又发现了一个有趣事实:在现代心理学中,人格的定义其实跟语言的使用有着紧密的关系。其实在计算机科学领域,我们对语言也有很多研究,我们称之为“自然语言理解”。在心理学里面,有一个概念叫“词汇学假说”。什么叫词汇学假说?根据这个假说,我们无需通过观察、研究各种各样的人来研究人格,我们可以简单一些,通过直接观察人类语言中相关词汇。比如说,你介绍一位朋友给我认识,可能会用一大段话来描述他:“他特别喜欢说话;人很多的时候,他特别高兴,话特别多;每次都听到他在说话,是个话痨”等等。其实,一个词即可概括这段话:健谈。因此,心理学家决定整理这些描述性词汇。如果这个词汇不多的话,它们便可成为建立分类体系的基础。基于这些观察,人格理论的先驱奥尔波特(Allport)和奥德伯特(Odbert)于1936年对英语词汇进行了艰难而又系统的调查研究。通过查看词典,他们按照个人特质、暂时的情绪或者行为以及智力与才干这四个类别发现大约18000个单词,并进一步从中整理出四千多个描述性格的词汇。虽然说四千似乎已经很少了,但对于整个用户语言来说,这仍然是很复杂的。试想下,在描述一个人性格的时候,如果要给这四千个描述维度分别打分,这该是多大的工作量。因此,他们想在此基础上进一步缩减。在这个过程中,他们发现,这些单词间其实存在一些相关性。比如说,一般外向的人通常也比较健谈,冷静的人通常也比较理智,但他可能也比较内向。如果能定位这些相关性,便可在此基础上对四千多个词进行进一步归类。
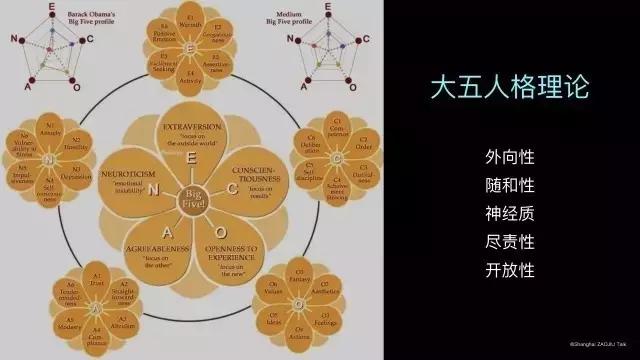
近二十年来,人格研究者关注与支持最多的人格定义是五因素模型,也常常被称之为“大五人格理论”。如图所示,大五人格包括了五个高度概括的人格因素:外向性 (Extraversion),尽责性 (Conscientiousness),神经质 (Neuroticism),随和型(Agreeableness)和开放性(Openness)。每个人格因素下还有一些细分特质(比如外向性下包括了是否经常参加活动、是否热心肠等)。这样,以后你在介绍朋友时,可以将他描述为“比较外向,但不太随和,可能比较情绪化的一个人”。方式很简单,但是描述很全面。实际上,整理这些词汇以及生成人格分类体系大多是依赖数据驱动,与计算机科学有很多很紧密的联系。那我们能不能自动的计算用户的大五人格呢?其实这也是有可能的。
在传统人格测量中,心理学家往往采用访谈和调查问卷这种形式,需要耗费大量的人力、财力和时间,受测者往往局限于几十人到几百人的规模,不可能实现大规模用户的测量。在座很多人可能都做过心理问卷调查,一般来说有上百道题。我不知道有多少人会认真填写这上百道题,可能大家都是一路打“三”——一到五分打个中间分,这样的结果其实没什么意义。这个工作的确非常麻烦,并且很多时候受访者自己其实也不知道该打几分。比如说,比较内向是打一还是二?其实都非常模糊。但是,心理学中还有一种人格测量的方法,叫做行为测量,通过观察个体的行为来进行测评。行为测量的理论基础是人格理论中的人类行为的一致性。既然人格能够解释人际之间的稳定的个体差异,那么个体行为表现出的差异性就跟个体的人格息息相关,因此通过观察个体行为使得预测人格变成了可能。只是在计算机技术得到广泛应用之前,心理学家很难收集到用户足够丰富的行为数据,因此数据的匮乏导致了行为测量在传统心理学中并没有被广泛采用。
然而,近年来,随着互联网、智能手机和各种传感设备的普及,用户的行为数据被广泛收集,再加上人工智能方法在建模用户方面的推进,使得通过行为数据测量人格的方法在计算机和心理学的交叉领域得到了快速的发展。我们的研究工作在此基础上更进一步,提出“人格推测模型”,利用社交媒体上的异构数据(比如头像照片、发表的文字、表情符使用以及社交关系等)来预测大五人格。比如说针对图片,我们可以采用深度残差网络的方式,算出语义表示,再将这些图片聚成某些类别,如卡通、自拍、合影、动植物。其实在这个过程中,我们仍然需要和心理学家合作。用基于行为数据的人工智能方法进行人格预测,首先需要收集少量用户的调查问卷结果作为标注。通过标注用户行为特点及人格特征,将它们之间的映射和联系输入模型中,以训练出一个好的模型。
实际上,我们找了一批志愿者,他们提供了自己的数据,并完成了问卷调查,这样我们便拥有两方面数据。在训练完模型后,新的用户便无需完成用户调查,模型可以自动计算其人格。我们可以来看看计算结果。听起来是不是很抽象?但其实也很具体。例如,我们可以计算用户发表文字和性格间的关系。大五人格有五个维度,我们可以计算出文字和每一个维度间是特别正相关或者特别负相关。例如一个经常在朋友圈写青春和自我的人可能比较外向,而常写失败和面对的用户外向性得分便很低。还有一些用户可能会写时代、社会、成功这些听起来非常正能量的词汇,我们发现这些人尽责性比较高。相反,有些人可能经常写随便、萌萌、气质这些词,我们发现他们尽责性比较低。尽责性低并不是一个贬义词:在这个模型中,在乎结果的人尽责性比较高,在乎过程的人尽责性比较低。这两个极端都有它的优势,并无好坏之分。

我们还通过计算大五人格和用户头像类簇的皮尔逊系数,展示了与大五人格强烈正相关或者负相关的类簇(每个类簇选取了2张图片显示)。这样的计算揭示了一些有趣的现象:比如外向性得分高的用户喜欢使用包含笑脸的头像,而得分低的用户往往在头像中遮挡了面部表情或者使用侧脸;开放性得分高的用户往往使用和朋友在一起的照片作为头像,而开放性得分低的用户的头像很多是自拍照。我们的实验结果表明单单使用头像照片,就能使个体性格预测的准确性到达0.6。我们不仅对每种维度上的行为数据提出了针对性的特征提取策略,而且使用集成学习技术(Ensemble)有效融合了不同维度的行为数据来提升大五人格预测的准确率,使得个体大五人格预测的准确性到达0.75以上。
在理解用户之后,下一步就是如何利用这些知识来帮助机器人产生像人一样的思维。人类希望机器人能实现的重要行为之一就是聊天,微软也提出了“Conversation as a Platform(对话即平台)”的概念,认为未来所有人机界面都将转变为对话界面。
两年前我看过一部电视剧,至今记忆犹新,是英剧《黑镜(Black Mirror)》第二季第一集“be right back”。这部电视剧描述了一家人工智能公司,它可以通过一个人的社交媒体和在线聊天数据合成一个虚拟人,来模仿人物原型的性格特点和他的女友进行对话。这看起来很科幻,但实际上离我们已经并不遥远。2016年10月一篇新闻报道中也提到,来自俄罗斯的创业者Kuyda为了纪念去世的朋友Roman,用他的8000条短信数据训练了一个聊天机器人,并于2016年5月正式发布。

尽管技术已经前进了一大步,但就算是目前最好的聊天机器人也还无法让人感觉他是一个具有稳定性格和情感、活生生的人。这就涉及到如何让机器人的语言和行为更具有个性。
随着社交网络盛行,带有用户标签的语言数据变得容易获取。就像前面提到的新闻报道描述一样,如果我们有足够的关于某个人的数据,就有可能训练出一个和他个性一样的聊天机器人。当然,我们还可以通过一群人,例如儿童、学生、甚至诗人的数据来训练出具有一类人特点的机器人。例如,我们是否可以收集所有现代诗人的数据,用这些数据来训练一个出口成诗的机器人?其实现在也是可以做到的。但是,随着研究的深入,我相信最终我们还会遇到瓶颈,例如到底如何才能让机器人具备更加真实的人类性格与情感,这还是需要和心理学家合作。
其实,最早的聊天机器人Eliza就是一个心理咨询师。大概50多年前,MIT的一位研究员Joseph开发了Eliza,在与用户聊天时,Eliza引入了心理学家罗杰斯提出的个人中心疗法(Person-Centered Therapy),更多强调对话态度,比如尊重与同理心。Eliza其实自己并不主动说新内容,它更多的是一直在引导用户说话尽可能倾诉。看似讨巧的Eliza项目取得了意外的成功,它的效果让当时的用户非常震惊,其中就包括了它的创造者Joseph。其实,Joseph当时给这个项目起名字为ELIZA是有出处的。不知大家是否看过《卖花女》?在这个戏剧里,Eliza处在社会底层。为了进入社会上层社会,她努力学习上层人民用的语言,使她看起来像一个上层人士,但最终伪装被拆穿。Joseph将这个机器人命名为ELIZA,就是希望机器能够伪装成人,但他没想到的是,这个伪装竟还不容易被拆穿。以致于后来产生一个词汇,叫ELIZA效应,即高估了机器人能力的一种心理感觉。ELIZA效应其实现在也很常见,比如击败顶尖高手的AlphaGo一出现,人们便觉得电脑已经具有下围棋的灵感,人工智能马上要超越人类。但其实,AlphaGo背后所有的程序都是人写的。所谓的灵感,所谓的智能,实际最终都是程序实现的。
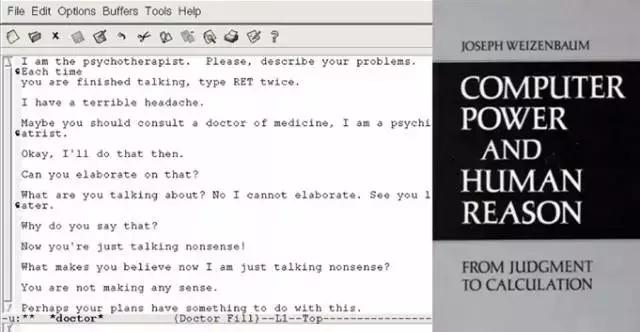
受ELIZA项目启发,微软亚洲研究院也开展了DiPsy项目,这个项目的目标是让机器人能够和人聊天,帮助他们克服心理上的问题。在这个项目中,我们借鉴了心理咨询中常用的认知行为疗法(Cognitive Behavior Therapy) 和正念疗法(Mindfulness)。DiPsy的特点是以自然、有效的方式引导对话,让用户尽情倾诉。它还会研究用户心理过程,在数据驱动下,对用户的心理特质与精神障碍作出诊断。我们采取认知行为疗法(CBT)或早期干预,在各种治疗性的语境中,改变用户的思维与行为方式,帮助存在风险的用户缓解并管理心理问题。
在未来,我们期待这个项目能帮助解决实际的社会问题,例如农村留守儿童的心理疏导。在前不久举办的未来论坛上,微软全球执行副总裁沈向洋说,他想要解决三个和人脑息息相关的疾病:儿童自闭症、中年忧郁症、老年痴呆症。我希望我们的技术能帮助他做到这一点。

当然,这些研究项目很多都还在起步阶段,我们希望最终能实现让机器拥有像人一样的思维,并在人需要时能提供不仅帮助,还能陪伴。当你孤独时,至少有个AI与你在一起。





大厂都在用的调研问卷软件
问卷星
- 3.8
(62)咨询产品免费试用Zoho问卷
- 4.1
(30)咨询产品免费试用问卷网
- 3.7
(28)咨询产品免费试用



限时免费的调研问卷软件
调研家
- 3.8
(27)咨询产品免费试用LTD数据表单
- 5.0
(1)咨询产品免费试用腾讯问卷
- 3.6
(31)咨询产品免费试用



新锐产品推荐
论客Coremail
- 4.0
(13)咨询产品免费试用Eclipse
- 3.9
(55)咨询产品免费试用Koding
- 4.0
(5)咨询产品免费试用Gatsby
- 0.0
(0)咨询产品免费试用Visual Studio
- 4.0
(45)咨询产品免费试用GoLand
- 4.0
(12)咨询产品免费试用







