定量数据用户画像的方法与流程
编者按:本文来源微信公众号“用盐有点咸”(ID:yongyanyoudianxian),36氪经授权发布。
用户画像是一种目标用户的人物原型,它不仅可以快速了解用户的基本信息并快速归类,并且可以进一步精准地分析用户行为习惯和态度偏好。用户画像虽然是用户的虚拟代表,但必须基于的是真实用户和真实数据。
1、明确研究目的
我们尝试去做一个用户画像,往往是基于以下情景:
确定目标用户,将用户根据不同特征划分不同类型,确定目标用户的比例和特征;
统计用户数据,获得用户的操作行为、情感偏好以及人口学等信息;
根据目标用户确定产品发展相关优先级,在设计和运营中将焦点聚焦于目标用户的使用动机与行为操作;
方便设计与运营,据用户画像提供的具体的人物形象进行产品设计和运营活动,也比仅有模糊的、虚构的、或是有个人偏好的用户形象更为方便和可靠;
根据不同类型用户构建智能推荐系统,比如个性化推荐,精准运营等等。
从用户画像的使用情境也可以看出,用户画像适用于各个产品周期:从潜在用户挖掘到新用户引流,再到老用户的培养与流失用户的回流,用户画像都有用武之地。
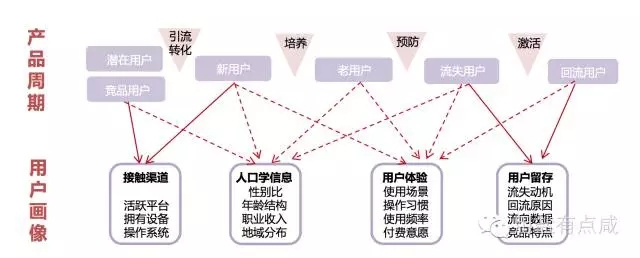
2、明确研究方法
采用定性的方法(如,深度访谈、焦点小组)或定量的方法(如,定量问卷、行为日志数据)都能够完成用户画像的构建,不同的方法各有优缺点:
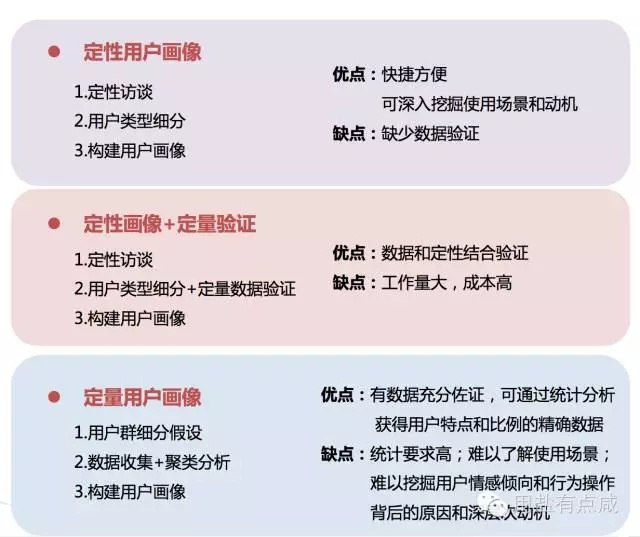
但是,不论是选择定性还是定量的方法,都首先需要对用户类型有一个基本“量”的了解,否则在选用样本时就会产生偏差。那么如何通过定量的方法(聚类)构建用户画像呢?
3、确定目标维度和数据
选择那些指标?
用户指标的选择,可以是封闭性的,也可以是开放性的。在封闭的指标中,用户群的类型是固定的,所有用户类型构成了全部的用户整体,比如轻度用户、重度用户;男性用户,女性用户。但是这种划分方式维度可能过于单一,无法体现用户群的复杂性,并且不利于指标体系的补充改进和迭代,因此在研究中我们更倾向于采用开放性的分类方式,可以根据不同应用场景变更或者拓展指标。
开放式的指标体系包括用户人口属性、行为操作属性、态度偏好属性、用户价值属性等,用户的行为和态度是不断变化的。
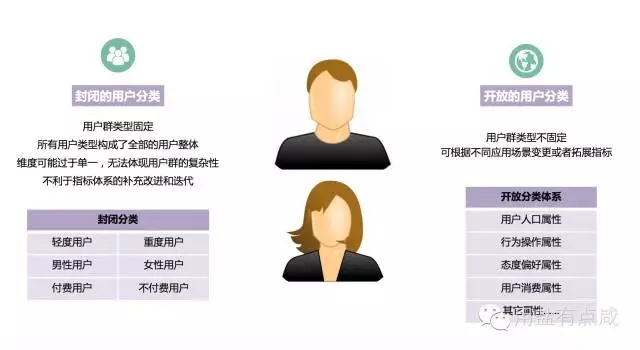
其中,注意一点,封闭式指标中的人口属性指标是相对稳定的静态数据。通常,从我们的经验和掌握到的用户信息,我们对用户的年龄结构、性别比例都已经明确,如果在聚类中人口属性指标对聚类干扰较大(共线性较强),或在模型中作为因子影响过高,可以在聚类时重点关注用户的行为操作和态度偏好等指标,聚类成功之后再比较每一种用户类型的人口学背景信息等。
如何获得和筛选数据?
在确定指标后,我们需要确定指标的来源。有些数据是后台行为日志可以记录到的,有些是需要用问卷调查的。一般而言,行为层面的指标可以用后台日志,更加准确。而态度层面的则要用问卷来获取。两种数据渠道各有优缺点:
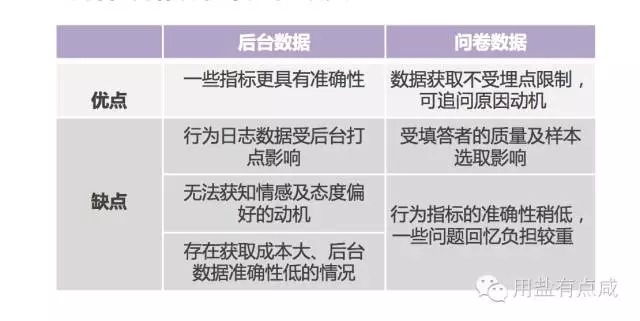
理论上,所有的数据都可以通过问卷获得。但是,为了最优化研究效果,我们采取了问卷+行为日志结合的方式。在发问卷的同时,抓取了用户的设备号和ID,以匹配后台数据。
在保证问卷效度的前提下,问卷设计还需要注意结合用户特征,以提高填答率以及数据准确率。比如,针对二次元用户,在用户群年龄结构偏小的前提下问卷不能太长,不能出现深奥的专业术语;同时问卷的语句表达以及页面风格也要相应调整,使其没有距离感。同时,注意筛除多次填答和注册的马甲账号问卷。此外还要注意新用户的占比,需要评估填答问卷中新注册用户的比例是否与投放期新用户正常增量一致。用户画像是否需要包含新用户取决于项目目的,也可以和产品方讨论后决定。
4、尝试与评估用户聚类
把用户分成几种类型?
聚类分析是探索性的研究,他根据指标或者变量之间的距离判断亲疏关系,将相似性的聚为一类,因此会出现多个可能的解,并不会给出一个最优的解,最终选择哪一种方案是取决于研究者的分析判断。
把用户分的类型越少,颗粒度就越粗,每种类型之间的特征就不会很分明;用户类型越多,颗粒度也就越细,但复杂的类型划分也会给产品定位和运营推广带来负担。因此,细化颗粒度不仅需要定量的聚类来调整,还需要结合产品经验来验证。同时,因为采用的是开放性的指标体系,我们不可能像区分“男性用户、女性用户”那样清楚地知道用户类型的数量,因此,在用数据进行用户画像时,最关键的一步就是确定把用户分成几种类型。
我们将数据导入spss尝试进行聚类分析。如果变量数据形式不统一(选择的指标有定序、有定类),则需要首先对数据进行标准化;其次,两个强相关的变量和其他变量一起进行聚类会加大因子的权重,使聚类效果不理想,所以我们还要使用因子分析对选择的指标提取公共因子,对因子共线性判断,因子分析是选择合适变量进行聚类的前提,如果因子之间共线性强,则提取公因子进行聚类,若共线性不强,则直接聚类。
如何选择合适的聚类方法?
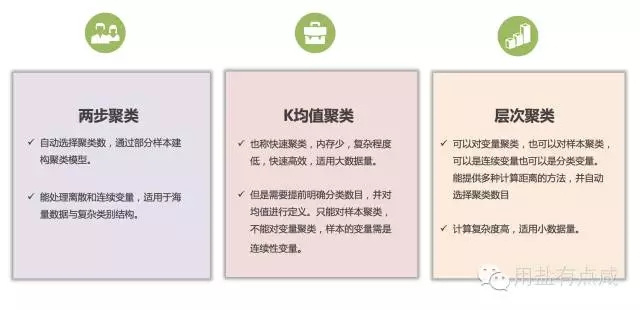
在确定因子之后需要选择合适的聚类方法。不同方法适用的情况不同,常用的是K均值聚类以及层次聚类。
K均值聚类也称快速聚类,内存少,复杂程度低,快速高效,适用大数据量。但是需要提前明确分类数目,并对均值进行定义。只能对样本聚类,不能对变量聚类,样本的变量需是连续性变量。
层次聚类可以对变量聚类,也可以对样本聚类,可以是连续变量也可以是分类变量。能提供多种计算距离的方法,但是计算复杂度高,适用小数据量,我们需要结合项目的具体情况,包括项目周期、数据形式、数据量、聚类特征等等来确定聚类方法。
最后通过尝试不同的聚类数、距离算法和分类方法,我们可以根据以下几点来确定分类的数量:
依据产品经验,不同产品的典型用户不同
根据已有的用户研究以及相关研究结论
根据具体的分类效果确定
根据层次聚类“步数——距离”拐点
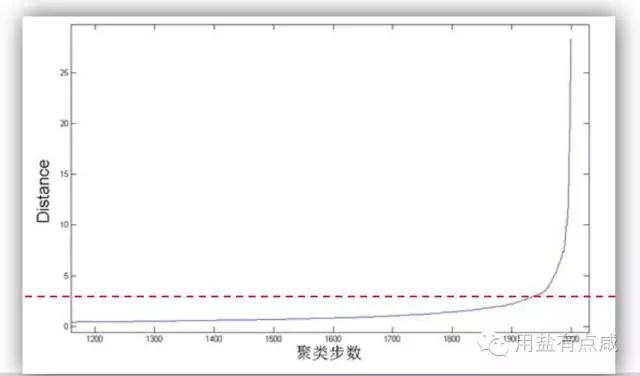
聚类效果好坏的评估可以从聚类中心之间的距离、组件与组内的方差以及群组数量之间的比例是否符合产品特征、比例是否协调以及划分的类型对产品是否有意义等方面去评估。
5、把数据还原成用户
在已经得知了分类结果并且分析得出了每一类用户在各项指标上的特征之后,构建用户画像的工作也就好比在一副骨架上填充血肉。一方面,我们可以直接利用获取的数据,找到具有显著特征的信息,赋予到用户身上。比如第一类用户60%使用iOS系统,而其他三类均不超过20%,我们就可以将第一类用户抽象为一个平时使用iPhone 的人。除了问卷数据之外,想要使人物形象更加鲜明,可以对问卷本文题进行分析,或者根据产品经验、用户反馈或已有研究进行画像,这样可以使用户形象更加有血有肉。
但是,把数据还原成用户本身用户也需要遵循几个原则,画像(Persona)意味着一个令人信服的用户角色要满足七个条件:

注:Persona原则来源于Alan Cooper,https://plus.google.com/101097598357299353681/about
通过定量化的调研可以快速对用户建立一个精准的认识,对不同数量、不同特征的用户进行比较统计分析,在后期产品迭代改进的过程中可以将用户进行优先级排序,着重关注核心的、规模大的用户。但是,依靠数据这种偏定量的方式建立的用户画像依然是粗线条的,难以描述典型用户的生活情景、使用场景,难以挖掘用户情感倾向和行为操作背后的原因和深层次动机。因此,如果有足够精力和时间,后续可以对每类用户进行深入的访谈,将定量和定性的方法结合起来,建立的用户画像会更为精准和生动。
作者介绍:
项宇,目前在网易杭州研究院产品发展部,对接网易云阅读、网易漫画的用户研究工作。从社会学入行用户研究,不断学习与探究用户群体背后的微观动机与宏观行为。






大厂都在用的调研问卷软件
问卷星
- 3.8
(62)咨询产品免费试用Zoho问卷
- 4.1
(30)咨询产品免费试用问卷网
- 3.7
(28)咨询产品免费试用



限时免费的调研问卷软件
调研家
- 3.8
(27)咨询产品免费试用LTD数据表单
- 5.0
(1)咨询产品免费试用腾讯问卷
- 3.6
(31)咨询产品免费试用



新锐产品推荐
九州云-ANIMBUS® EE 8.0
- 0.0
(0)咨询产品免费试用AppHarbor
- 3.9
(10)咨询产品免费试用Genesys Cloud CX
- 3.9
(40)咨询产品免费试用UJET
- 4.2
(40)咨询产品免费试用IBM Turbonomic
- 3.9
(40)咨询产品免费试用Zesty
- 4.5
(40)咨询产品免费试用







