闻声识人:声纹识别技术如何解决身份认证问题?
编者按:在日常生活中,我们时时刻刻都在从外界接受和向外界传达着各种信息,语音信息则是其中重要的一部分。在语音领域中,人的语音通常被定义为人的发音器官所发出的、带有一定实际含义的声音,也常常被研究者认为是语言的发音符号。
音频信号的处理在人工智能和机器学习领域研究中具有很重要的地位。人类语音中含有各类丰富的信息,既有丰富的说话人个性信息和发音的内容信息,也有录制环境的噪声信息、信道信息等等。本文节选汪德嘉博士《身份危机》一书中声纹识别技术章节,带大家了解声纹识别是什么?有哪些应用领域?

声纹其实就是对语音中所蕴含的、能表征和标识说话人的语音特征,以及基于这些特征(参数)所建立的语音模型的总称,而声纹识别是根据待识别语音的声纹特征识别该段语音所对应的说话人的过程。与指纹类似,每个人在说话过程中所蕴含的语音特征和发音习惯几乎是独一无二的,就算被模仿,也改变不了话者最本质的发音特性和声道特征。有相关科学研究表明,声纹具有特定性和稳定性等特点,尤其在成年之后,可以在相对长的时间里保持相对稳定不变。
声纹是一种行为特征,由于每个人在讲话时使用的发声器官如舌头、牙齿、口腔、声带、肺、鼻腔等在尺寸和形态方面有所差异,以及年龄、性格、语言习惯等多种原因,加之发音容量大小和发音频率不同,在发音时千姿百态,因而导致这些器官发出的声音必然有着各自的特点。可以说任何2个人的声纹图谱都不尽相同。
声纹识别技术又称说话人识别技术,就是基于这些信息来探索人类身份的一种生物特征识别技术。这种技术基于语音中所包含的说话人特有的个性信息,利用计算机以及现在的信息识别技术,自动地鉴别当前语音对应的说话人身份。声纹识别与语音识别不同,声纹识别的过程是试图找到区别每个人的个性特征,而语音识别则是侧重于对话者所表述的内容进行区分。在实际应用中往往把语音识别技术和声纹识别技术结合起来应用,以提高声纹身份认证系统的安全性能。
声纹识别因其不涉及用户隐私问题,往往用户接受程度较高。另一方面声纹的获取可以说是最方便的,只需要一个麦克风或者电话和手机就可以采集用户声纹特征信息,完成身份认证。这也使得声纹识别技术可以方便地用来作为远程身份确认技术。
声纹识别技术是基于人的声纹不变性的,然而同一个人的声音易于受到年龄、情绪、身体状况等的影响,导致识别性能降低。另一方面,不同的麦克风和信道对识别性能都有不同程度的影响。环境噪声和混合说话人情形也会对声纹识别带来较大的影响。
声纹识别研究现状
声纹识别是指根据待识别语音的声纹特征识别该段语音所对应的说话人的过程。该研究最早始于20世纪30年代,当时研究者们主要通过观察人类对语音的实际反应,研究人耳听觉机理对说话人的辨识。进人20世纪下半叶,随着生物信息和计算机信息技术的发展,通过计算机进行自动的声纹识别成为可能。1945年,Bell实验室的Kesta等人借助肉眼观察,成功实现了语谱图匹配,首次提出了“声纹”的概念;并于1962年首次提出采用此方法进行声纹识别的可行性。Bell实验室的Pruzanshy提出了基于模板匹配和统计方差分析的说话人识别方法,该方法引起了声纹识别研究的高潮。
现代声纹识别技术通常可以分为前端处理和建模测试阶段。
前端处理包括语音信号的预处理和语音信号的特征提取。在声纹识别系统的前端处理阶段中,将语音信号看作短时平稳的序列,语音特征提取的第1步是语音信号的分帧处理,并利用窗函数来减少由截断处理导致的Gibbs效应;同时用预加重来提升高频信息,压缩语音的动态范围,然后对每帧语音信号进行频谱处理,得到各种不同的特征参数。常用的特征提取参数有线性预测倒谱系数(linear predictive cepstrum coefficient,LPCC)、感知线性预测系数(perceptual linear predictive,PLP)、梅尔倒谱系数(Mel frequency cepstrum coefficient,MFCC)等。
在声纹测试之前,首先对多个声纹信号经过特征提取后进行训练建模,形成一个表征各个人的多复合声纹模型库。而声纹测试的过程是将某段来自某个人的语音经过特征提取后与多复合声纹模型库中的声纹模型进行匹配,进而识别打分,这个阶段可以判断该段语音是来自于集内说话人还是集外说话人。
如果是来自集内说话人则进行下一步的辨认或确认操作。对于声纹辨认来说,是一个“一对多”的比较过程,即所提取的特征参数要与多复合声纹模型库的每一个参考模型进行比较,并把与它分数最接近的参考模型所对应的说话人作为某段语音的发出者;而对于声纹确认来说,则是将某段语音提取的特征参数与特定的说话人的参考模型相比较,如果得出的分数大于预先规定的阈值则予以确认,否则予以拒绝。
在声纹识别中,不同模式的匹配方法的区别就在于说话人模型的表示以及模型匹配的方法。常用的识别方法可以分为模板匹配法、概率模型法、人工神经网络法等.其中概率模型法具有灵活性强、理论意义完整等特点,是目前声纹识别中使用的主流匹配方法。
概率模型法有分段的高斯模型、高斯混合模型和隐马尔可夫模型等,其中高斯混合模型和隐马尔可夫模型是声纹识别中2种最常使用的概率模型。高斯混合模型用多个高斯分布的线性组合近似多维矢量的连续概率分布,能较为有效地刻画说话人特性。采用高斯混合模型的说话人识别系统有很高的识别率。在文本无关的说话人识别领域,高斯混合模型已经成为占统治地位的主流方法。隐马尔可夫模型可以描述语音随时间变化的情况,在文本相关的说话人识别中能充分利用已知的文本信息,达到更高的识别率。
近年来,研究者提出一系列以高斯混合模型和通用背景模型(Gaussian mixture models universal background models,GMM-UBM)为基础的声纹识别建模方法,使得声纹识别技术的性能显著提高。前几年美国国家标准技术局(American National Instituteof Standardsand Technology,NIST)组织的评测中高斯混合模型超矢量支持向量机、联合因子分析等建模方法都以GMM-UBM系统为基础,其中使用i-vector建模的声纹识别技术性能最优,成为当前国内外研究的主流系统。
此外,研究者针对说话人识别中存在的问题也有一些相关研究。基于F-ratio准则的频带区分性特征算法和基于性能驱动的频带弯折算法,可以弱化声纹特征信息随时间变化的因素。另外在基于短语音的声纹识别中,研究者也提出一系列方法和相应对策。
声纹识别的应用
声纹识别技术早已在西方许多国家开始应用,如:1998年欧洲电信联盟应用声纹识别技术在电信与金融结合领域,完成了CAVE计划;2004年美国最大的银行自动出纳机制造商NCR分部,开始试验自动出纳机的声纹核实效果;同年5月美国加利福尼亚州BeepCard公司发明了一种带有特殊安全功能的信用卡,这种信用卡只有在识别出主人的声音后确认身份后才能正常操作;2006年,荷兰的ABNAMRO银行率先使用了美国VoiceVault的声纹识别系统,借助预先录制的个人私密问题进行身份验证。目前在国外,声纹识别技术已经广泛应用到军事、国防、政府、金融等多个领域。
国内对声纹识别技术的研究起步稍晚于国外,但经过国内研究人员的共同努力,声纹识别技术在国内已经得到了较好的发展与应用。2011年中国建设银行构建了基于说话人识别技术的声纹电话银行系统;2013年11月,厦门天聪公司与厦门公安局指挥中心合作,搭建厦门“110”报警声纹采集与辅警系统。根据实际应用范畴,下文将从声纹辨认和确认等方面详细介绍声纹识别技术的应用,并总结相关的行业及国家标准。
声纹确认技术应用领域
随着互联网的快速发展,便捷的网上交易越来越受人们的青睐,因而远程身份认证的安全性亟待加强。声纹确认技术可以满足网上交易、支付、远程身份认证的安全性需要,并已逐渐广泛应用于证券交易、银行交易、个人设备声控锁、汽车声控锁、公安取证、信用卡识别等。
(1)网络支付
2014年中国互联网支付用户调研报告显示,网上支付、手机支付、第三方支付已成为现代人购物付款的主流方式。显然,网络支付的安全性应当重视起来,网络支付的身份认证也愈发重要。近年来,有相关媒体接二连三地报道支付宝被盗刷、网银被转出等案件。为了防止这类案件的再次发生,将声纹确认技术加入到交易支付中,有效地提高了个人资金和交易支付的安全性。
例如,荷兰ABNAMRO银行、澳大利亚国家银行National借助声纹识别系统实现用户身份认证;全球互联网支付系统的领导者VoiceCommerceGroup也于2008年推出了基于声纹识别的VoicePay服务。目前在国内,声纹认证技术正在中国建设银行等领域推广使用。
(2)声纹锁控
据媒体报道,近几年数以万计的腾讯QQ用户出现了账号被盗取的情况。盗号者通过联系用户的亲朋好友进行金钱诈骗,给用户及其亲友带来了严重的损失。为了避免这类事件再次发生,有必要将声纹认证代替明文密码认证。
例如,微信已上线使用基于声纹动态口令的登录方式,极大提高了使用者账号的安全性。随着声纹认证技术的成熟,相信声纹控锁技术将被广泛地应用在各类账户声控密码锁、电脑声控锁、汽车声控锁等领域中。
(3)生存认证
有关资料显示,全国每年都有上万人甚至更多的人冒领社保达数亿元之多。为了防止养老金被冒领,进一步完善对养老保险金的管理和监督,社保局可通过预装声纹身份认证系统,再结合人工辅助手段,对领养老金者进行现场身份认证或当本人无法亲临现场时可通过电话进行远程身份确认,有效地阻止国家社保养老金的流失,提高社保服务机构工作的准确性和安全性。与其他生物认证技术相比,声纹认证技术具有更强的远程操控性,可快捷灵活地应用于远程身份认证中。
声纹辨认技术应用领域
声纹辨认技术通常广泛应用于公安司法、军队国防领域中,如:刑侦破案、罪犯跟踪、国防监听等。
1.监听跟踪
恐怖分子在作案前后通常会与组织、同伙保持联系,通讯中可能会包含关键内容。因此,在通信系统或安全监测系统中预先安装声纹辨认系统,可通过通讯跟踪和声纹辨别技术对罪犯进行预防和侦查追捕。据悉,拉登的落网正是美国情报部门充分利用了声纹鉴别技术。此外,声纹辨认技术还用于对满刑释放的犯罪嫌疑人进行监听和跟踪,可有效阻止犯罪嫌疑人再次犯科,也利于对其进行及时逮捕。
2.国防安全
声纹辨认技术可以察觉电话交谈过程中是否有关键说话人出现,继而对交谈内容进行跟踪(战场环境监听);当通过电话发出军事指令时,可以对发出命令者进行身份辨认(敌我指战员鉴别)。目前该技术在国外军事方面已经有所应用。据报道,2001年4月1日迫降在我国海南机场的美军EP一3侦察机就载有类似的声纹识别侦听模块。
3.公安技侦
犯罪嫌疑人通过非法渠道到获取受害者的个人信息,通过电话勒索、绑架等刑事犯罪案件时有发生。如:2015年9月21日,中国警察网新闻报道了一起电话“勒索消灾费每天恐吓数百名学生家长”的案件;2015年11月19日报道了富豪被绑架勒索的案件等。对于此类的刑事犯罪案件,公安司法人员可利用声纹辨认技术,从通话语音中锁定嫌疑犯人、减小刑侦范围。在车站、飞机、码头等公共安检点装入声纹辨认系统,可以有效对危险人物进行鉴别和提示,降低肉眼识别所带来的错误,提高人们生命财产的安全性。
4、其他应用领域
除了上述相关应用领域,说话人检测和追踪技术也有着广泛的应用。在含有多说话人的语音段中,如何高效准确地把目标说话人检测标识出来有着十分重要的意义。例如,在现有音频/视频会议系统中,通常设有多麦克风阵列用以实时记录会议中每一个说话人的讲话。通过将说话人追踪技术嵌入该会议系统,可实时标识每段语音所对应的说话人,实时追踪“whospokewhen”。该技术广泛应用于远程会议中,方便会议纪要总结,有利于提高公司的工作效率。
声纹识别行业及国家标准
为了使生物特征识别技术得到更好的发展,国际标准化组织(International Organization for Standardization,ISO)对生物特征识别的相关术语及其产业技术制订了标准和规范,其中涵括了声纹识别技术。我国国家标准和相关行业权威部门也针对声纹识别技术制定了一系列的标准及规范,如:
(1)SJ/T11380—2008
由北京得意公司、清华大学智能技术与系统国家重点实验室(语音与语言技术中心)和中国电子技术标准化研究所共同起草的《自动声纹识别(说话人识别)技术规范》(SJ/T11380—2008)于2008年3月11日正式颁布实施,该标准的内容主要包括声纹识别(说话人识别)的术语与定义、数据交换格式和应用编程接口,适用于各种计算机、网络和智能设备的声纹识别系统。该标准是我国第1个关于声纹识别(说话人识别)的标准,其颁布很好地推动和规范了我国的声纹识别产业的发展。
(2)GA/T893—2010
由清华大学、中国科学院自动化研究所、中国科学院计算技术研究所等单位共同起草的《安防生物特征识别应用术语》(GA/T893—2010)标准于2010年12月1日起实施,该标准规范化了生物特征识别技术通用术语,其中包括声纹识别专用术语的定义规范。该标准的颁布实施给生物特征识别技术的研究带来了方便,同时也避免了研究人员因滥用自定义术语而对技术研究造成不良影响。
(3)GA/T1179—2014
2014年9月19日,由全国安防标委会人体生物特征识别应用分技术委员会正式发出公告,《安防声纹确认应用算法技术要求和测试方法》(GA/T1179—2014)标准已通过审核批准予以颁布,并于2014年10月1日开始实施。该标准是由清华大学语音和技术中心和北京得意公司为主要单位共同起草的。该标准首次提出声纹识别安全分级的概念。它的颁布在一定程度上促进了国内声纹技术在安防行业的发展应用。
此外,全国信息标准化委员会生物特征识别分技术委员会(SAClTC281SC37)也设有生物特征识别标准委员会,其生物特征识别标准委员会也对生物特征识别在其应用领域提供了一些标准。这将对生物特征识别技术的发展起到推动性的作用。然而,目前这些标准对于生物特征识别行业的发展还是远远不够的,更多更精细的标准有待制定,以此满足生物特征识别技术和产业的发展。
声纹识别系统技术原理
声纹识别系统主要是由预处理、特征提取、建模、模式匹配及系统判别等构成。声纹识别系统原理图(见图9-3)。
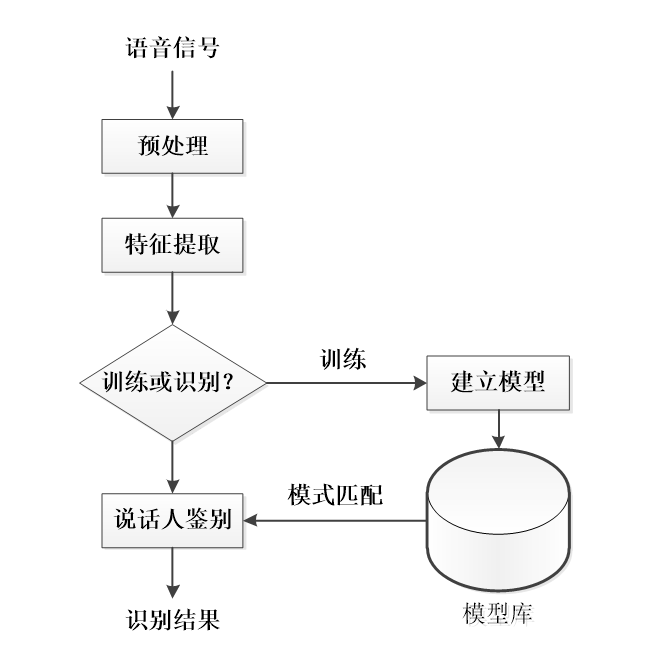
图9-3 声纹识别系统原理图
1. 预处理
对语音信号进行采样之前,必须对语音信号进行预滤泼,以防止输入信号中频率超过f/2的分量引起混叠和50Hz的电源工频干扰。对麦克风输入的语音信号进行量化和采样,经去噪处理后,将得到的干净信号进行预加重处理,从而提升高频部分的幅度,使得信号变的平坦,以便于频谱分析或是声道参数分析。
由于语音信号是时变信号,但可以认为在短时间内是时不变的。所以在语音信号进行处理前必须进行分,就是利用窗函数来截取语音信号中的一段。为了保持帧与帧之间的连贯性。经常采用交叠分段的方法。对于采样频率为8kHz的语音信号,通常采用32ms为帧长,而帧移通常为16ms-20ms之间。为了从背景语音中提取语音信号的有声段,系统对每一帧采用了短时能量和短时过零率”一相结合的方法进行短点检测。
2. 特征提取
目前主流的声纹特征参数有LPC以及基于mel频率的倒谱系数(meI-frequency cepSlral coefficients,简称MFCC)。在实验中证明,MFCC是目前声纹特征中识别率最高的一种,在本系统中,声纹特征采用12维静态MFCC参数和一阶12维动态MFCC参数的组合。
美尔倒谱频谱分析与普通的频谱分析不同,它是一种与人耳听觉特性相关的谱分析。人耳所能听到的声音的高低与声音的频率并不是线性关系,而用meI频率尺度更符合人耳的听觉特性。
根据临界频带的划分,可以将语音频率划分成一系列三角形的滤波器序列,即mel滤波器组。取每个三角形的滤波器频率带宽内所有信号的幅度加权和作为这个滤波器的输出,然后在对输出结果作对数运算,再进一步作离散余弦变换(DCT)即得到MFCC参数。美尔倒谱系数是按帧来计算的。每一帧提取12维静态特征参数和一阶动态特征参数。
3. 基于高斯混合模型的声纹认证
高斯混合模型(Gaussian Mixture Model)作为目前在声纹认证系统设计中的一种模式识别方法,已经被广泛地应用于文本相关和文本无关的声纹识别中。GMM是以统计学中的高斯随机概率分布为基础,用概率密度函数来表征每个人的声纹特征在特征空闻的分布。目前在声纹识别中,GMM模型是识别率非常高的模型之一。
高斯混合模型用M个多位高斯分布加权得到,它描述了语音特征信号在特征空间的分布。训练时利用语音特征来训练成它对应的GMM模型,识别时将最能够产生测试语音特征的说话人模型对应的说话人来作为识别结果。
在高斯声纹识别系统中,每一个语者的说话人个性特征都是用GMM模型来描述的。当给定了某个语者的训练语音,并且提取了语者语音的MFCC特征后,通过这些特征来建立说话人GMM模型,也就是重估GMM模型参数。比较经典的GMM模型训练算法是EM(expectation—maximization)算法,而在模型初始值方面,本文提出了一种基于遗传算法的蚁群聚类新算法。并与k-means算法进行了对比。实验证明,这种算法能够获得更优的识别效果。
4. 说话人鉴别
说话人鉴别是提取说话人语音的MFCC特征,根据后验概率算法把说话人模型与说话人的语音进行模型比对。如果有与说话人语音相匹配的的模型,则接受,并把相匹配模型的语者来作为识别结果输出,反之,则拒绝。
声纹识别身份认证技术
为了保证认证的安全性,一般从以下两个方面考虑:首先,为了保障信息传输安全性方面,采用高强度的3DES算法代替传统的DES算法,密钥长度达168比特;其次,为了保障信息安全性、完整性以及可靠性方面综合使用了数字签名以及声纹认证技术。当用户(交易双方)向银行(这里银行视为第三方)申请在线支付业务,并且向银行索取数字签名密钥对时。为了确保交易的安全性,银行方可以采用声纹的方式对用户进行合法性验证。
(1) 用户启动终端业务软件,由业务软件随机的生成一个3DES密钥,与此同时利用相应的设备、算法等采集并且提取出声纹特征;
(2) 这时用户终端再使用银行方的RSA公钥把3DES密钥及声纹特征进行加密处理,把所得密文经互联网传输给银行,银行收到密文后使用自己的RSA私钥进行解密,从而获得用户的声纹特征和3DES密钥;
(3) 银行把用户的声纹信息与其内部声纹库记录进行匹配,验证用户的合法身份;如果验证是合法用户,取出用户的数字信封/数字签名私钥,并且使用用户传递过来的3DES密钥加密,进而回送给用户端;
(4) 用户收到密文后使用自己的3DES密钥解密,从而得到两把私钥。
采用这种认证技术有两个优点:密钥对是随机产生的每次都是不一样的,所以这样就避免了密钥被窃取的可能;声纹特征及3DES密钥使用的加密密钥银行端也是随机的产生的,这样就防止了黑客的攻击,而非法的获得银行的信任。
结束:声纹识别技术发展较为成熟,识别准确率也相对较高,是目前应用最为广泛、技术水平最为成熟的生物识别技术之一。声纹识别技术因其经济性、可操作性等优势,在将来会在更多的领域中、获得更为广泛的应用。因其自身的特殊性,声纹识别是唯一符合密码认证机制的生物特征识别技术,换成通俗易懂的话语来说,就是让你的声音与你的密码无缝结合。
身份认证是支持许多信息安全和合规性功能的基本服务。它对于授权和审计服务来说至关重要。在智能时代,单因子身份认证方式存在极高的安全风险,因此,显性因子与隐性因子相结合的多因子身份认证的优势得以凸显,攻击者即使破解单一因子(如口令、人脸),用户的身份认证安全依然可以得到保障。在接下来的文章中将为大家介绍多因子身份认证技术及应用场景,敬请期待!






大厂都在用的视频会议软件
小鱼易连
- 3.7
(181)咨询产品免费试用Zoho Meeting
- 4.1
(40)咨询产品免费试用华为云会议
- 4.5
(1)咨询产品免费试用



限时免费的视频会议软件
一启会议
- 4.6
(7)咨询产品免费试用TeamViewer
- 4.0
(40)咨询产品免费试用Zoom
- 3.9
(57)咨询产品免费试用



新锐产品推荐
法大大
- 3.9
(319)咨询产品免费试用石墨文档
- 4.0
(89)咨询产品免费试用Teambition
- 3.7
(90)咨询产品免费试用微盟微商城
- 3.8
(36)咨询产品免费试用有道云笔记
- 4.0
(73)咨询产品免费试用聚水潭erp
- 4.1
(5)咨询产品免费试用







