云从科技研发语音识别技术 97.03%一举打破世界纪录
在语音识别领域,全球科技企业的目标很一致,那就是想“超过人类”。之前科研界设定人类错词率为5.9%的这个界线,受过严格训练的专业速记员错词率在3%左右,错词率(Worderrorrate,WER)是衡量语音识别技术水平的核心指标。
人类的界线已在2017年被微软超过,而受过严格训练的专业速记员则一直坚守着自己的底线。
然而这个纪录也在这个10月被打破,2018年10月 29日,中国人工智能“国家队”云从科技在语音识别技术上取得重大突破,他们融合图像识别与语音识别的优势,推出全新Pyramidal-FSMN语音识别模型。
在技术研究的「最后一公里」,每 0.1 个百分点的进步都异常艰难。全新Pyramidal-FSMN语音识别模型在全球最大的开源语音识别数据集Librispeech上刷新了世界纪录,准确率提升到97.03%,将Librispeech的错词率(Worderrorrate,WER)降低至2.97%,超过阿里、百度、约翰霍普金斯大学等企业及高校,大幅刷新原先记录。
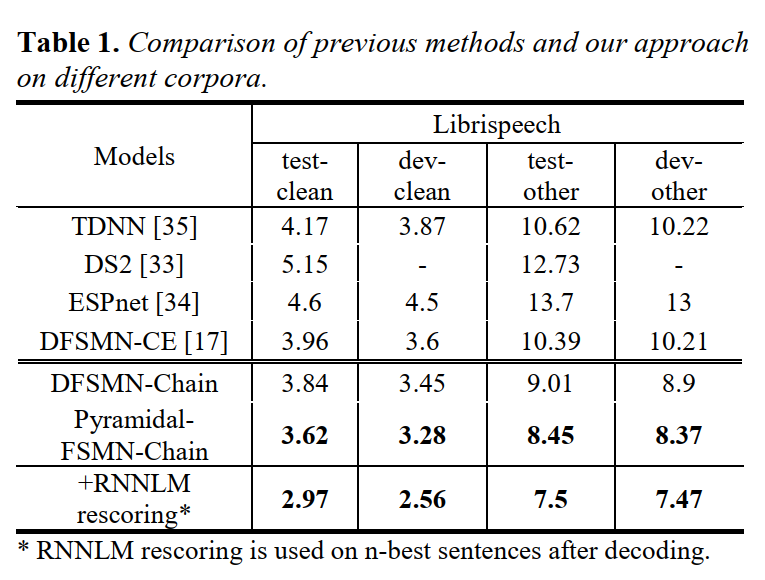
DS2:百度,ESPnet:约翰霍普金斯大学,DFSMN-CE:阿里
云从科技并没有把人脸识别作为唯一的“宝”来押注,这家孵化自中国科学院的企业,并不是第一次取得这样的技术突破。
2018年2月,云从科技正式在国内首发“3D结构光人脸识别技术”。2018年4月,云从科技“跨镜追踪技术”(ReID)技术在Market-1501,DukeMTMC-reID,CUHK03三个数据集刷新了世界纪录,其中最高在Market-1501上的首位命中率(Rank-1 Accuracy)达到96.6%,让跨镜追踪技术(ReID)技术在准确率上首次达到商用水平,人工智能从「刷脸」跨到「识人」的新纪元。
语音识别技术同样是智能感知中一个重要的部分,通过语音识别,机器就可以像人类一样听懂说话,进而能够理解、思考与反馈。近年来,在深度学习技术的帮助下,语音识别取得了极大的进展,从实验室开始走向市场,走向实用化。基于语音识别技术的输入法、搜索和翻译等人机交互场景都有了广泛的应用。

智能感知+大数据,是云从科技打造核心技术闭环,领跑人工智能行业的利器。
据悉,此次技术突破是云从科技打造核心技术闭环路径中的关键一步。此前,云从科技在10月12日发布了国家发改委“人工智能基础资源公共服务平台”项目,该平台可以基于行业数据为各行各业提供人工智能智能感知及大数据服务,中国人民银行、中国联通、中国邮政、民航局、金山云等企业与机构与云从首批签约。这个搭载人脸、人体、手势、红外、语音、车辆、风控、文字、大数据分析等多种方式为一体的人工智能平台,云从倾注了大量的技术力量。
目前,云从科技是中国银行业第一大AI供应商。包括农行、建行、中行、招行总行等全国400多家银行已采用公司产品,为全国银行提供对比服务日均2.16亿次,同时为14.7万家社会网点提供服务。
在安防领域,公司产品已在29个省级行政区上线实战,每天比对超过10亿次,数据汇聚总量超过千亿,协助全国公安抓获超过1万名犯罪嫌疑人;
在民航领域,已有60余家机场选择云从产品,日服务旅客人数达到6千万。
在这些基础上,云从科技正在致力整合算力、智力、数据等资源及其成果,打造人工智能平台,进一步促进人工智能在金融、安防、交通、零售、教育等重要行业的落地。
语音识别六十年,技术突破总是艰难而缓慢。
语音识别的研究起源可以追溯到上世纪50年代,AT&T贝尔实验室的Audry系统率先实现了十个英文数字识别。
从上世纪60年代开始,CMU的Reddy开始进行连续语音识别的开创性工作。但是这期间进展缓慢,以至于贝尔实验室的约翰·皮尔斯(John Pierce)认为语音识别是几乎不可能实现的事情。
上世纪70年代,计算机性能的提升,以及模式识别基础研究的发展,促进了语音识别的发展。IBM、贝尔实验室相继推出了实时的PC端孤立词识别系统。
上世纪80年代是语音识别快速发展的时期,引入了隐马尔科夫模型(HMM)。此时语音识别开始从孤立词识别系统向大词汇量连续语音识别系统发展。
上世纪90年代是语音识别基本成熟的时期,但是识别效果离实用化还相差甚远,语音识别的研究陷入了瓶颈。
关键突破起始于2006年。这一年辛顿(Hinton)提出深度置信网络(DBN),促使了深度神经网络(Deep Neural Network,DNN)研究的复苏,掀起了深度学习的热潮。
2009年,辛顿以及他的学生默罕默德(D. Mohamed)将深度神经网络应用于语音的声学建模,在小词汇量连续语音识别数据库TIMIT上获得成功。
2011年,微软研究院俞栋、邓力等发表深度神经网络在语音识别上的应用文章,在大词汇量连续语音识别任务上获得突破。国内外巨头大力开展语音识别研究。
2017年3月,IBM结合了 LSTM 模型和带有 3 个强声学模型的 WaveNet 语言模型。“集中扩展深度学习应用技术终于取得了 5.5% 错词率的突破”。相对应的是去年5月的6.9%。
2017年8月,微软发布新的里程碑,通过改进微软语音识别系统中基于神经网络的听觉和语言模型,在去年基础上降低了大约12%的出错率,错词率为5.1%。相对应的是去年10月的5.9%,声称超过人类。
2017年12月,谷歌发布全新端到端语音识别系统(State-of-the-art Speech Recognition With Sequence-to-Sequence Models),错词率降低至5.6%。相对于强大的传统系统有 16% 的性能提升。
2018年6月,阿里巴巴达摩院推出了新一代语音识别模型DFSMN,将全球语音识别准确率纪录提高至96.04%,错词率降低至3.96%。
2018年10月,云从科技发布全新Pyramidal-FSMN语音识别模型,错词率(Worderrorrate,WER)降低至2.97%,较之前提升了25%,将全球语音识别准确率纪录提高至97.03%,超过受过严格训练的专业人类速记员。






大厂都在用的商业智能(BI)软件
Wyn Enterprise
- 4.2
(49)咨询产品免费试用DigiPrime
- 4.7
(36)咨询产品免费试用微软 Power BI
- 3.8
(53)咨询产品免费试用



限时免费的商业智能(BI)软件
亿信ABI
- 3.9
(23)咨询产品免费试用派可数据
- 4.4
(31)咨询产品免费试用思迈特Smartbi
- 3.9
(28)咨询产品免费试用



新锐产品推荐
墨推互动
- 0.0
(0)咨询产品免费试用众麦通信-智能网络客服
- 0.0
(0)咨询产品免费试用云讯科技-智能语音质检
- 0.0
(0)咨询产品免费试用百应-多模态情感化AI
- 4.2
(5)咨询产品免费试用百应-全场景用户互动触达
- 4.5
(3)咨询产品免费试用阿牧网云-牧场端
- 0.0
(0)咨询产品免费试用







