初学机器学习?推荐从这十大算法入手
作者 | Reena Shaw,译者 | 严子怡,编辑 | vincent,AI前线出品| ID:ai-front
一、介绍
机器学习算法的研究已经得到了广泛的关注。发表在《哈佛商业评论》上的文章称“数据科学家”是“二十一世纪最性感的职业“。所以,对于那些刚刚踏入机器学习领域的人们,我们决定重写我们非常受欢迎的“金牌”博文《每个工程师都需要知道的十个机器学习算法》。简而言之,这篇文章是面向初学者的。
机器学习算法,是一种可以从数据中学习、从经验中提升自己而不需要人类干预的算法。学习的内容可能是一个从输入映射到输出的函数、无标记数据中的隐含结构或者是“基于实例的学习(instance-based learning)”,这种学习通过把新的实例与存储在内存中的训练数据进行比较,给新的实例赋予一个类别标记。“基于实例的学习”不会在这些具体的实例上创造一层抽象。
二、机器学习算法的种类
机器学习算法分为三种类型:
监督学习
监督学习问题可以分为两类:
a. 分类问题:预测的输出变量属于一系列类别。例如,男性和女性、生病和健康。
b. 回归问题:预测的输出变量是实数。例如,以实数记的瀑布流量大小、人的身高。
这篇文章介绍的前五个算法:线性回归、逻辑回归、CART、朴素贝叶斯、K 近邻算法均属于监督学习。
无监督学习
无监督学习问题只有输入变量而没有输出变量。这种学习问题使用无标记的训练数据来对数据中隐含的结构进行建模。
无监督学习问题可以分为三类:
a. 关联:为了发现各种现象同时出现的概率。这种方法广泛地运用在购物篮分析(market-basket analysis)中。例如,如果一个顾客买了一个面包,他有 80% 的可能性也会买鸡蛋。
b. 聚类:把样本分堆,使同一堆中的样本之间很相似,而不同堆之间的样本就有些差别。
c. 降维:正如它的名字所示,降维意味着减少数据集中变量的个数,但是仍然保留重要的信息。降维能够通过特征提取和特征选择的方法来实现。特征提取把数据从高维空间转化到低维空间。例如,主成分分析算法就是一种特征提取的方法。
强化学习
强化学习是一种让行动主体通过学习那些能够最大化奖励的行为是什么,然后根据当前状态来决定最优的下一步行动的机器学习算法。
强化学习通常通过试错的方式来学习最佳的行动。这些算法通常用在机器人学中。机器人可以通过在撞到障碍物后接收到的负反馈来学习如何避免碰撞。在视频游戏中,试错能帮助算法发现那些给予玩家奖励的特定动作。行动主体就能用这些正向奖励来理解什么是游戏中的最佳情形,并选择下一步行动。
三、统计各个机器学习算法的受欢迎程度
有一些调查论文(例如这个)统计了十大受欢迎数据挖掘算法。然而,这样的列表非常主观,并且,正如刚刚提到过的论文,其参与投票的样本大小非常小并且只局限于数据挖掘的高级从业人员。这些投票的人分别是 ACM KDD 创新奖、IEEE ICDM 研究贡献奖的获得者,KDD-06、ICDM‘06 和 SDM’06 的项目组委会成员和 145 位 ICDM‘06 的与会人员。
这篇博文中的十大机器学习算法是专门写给初学者的。这些算法大多数都是我在孟买大学攻读计算机工程学士学位的时候,在“数据存储和挖掘“课程中学到的。“数据存储和挖掘“课程是一个非常棒的机器学习算法领域的入门课程。由于最后两个算法(集成方法)广泛运用于 Kaggle 比赛中,我专门把它们也写到了文章中。希望你喜欢这篇文章!
四、监督学习算法
线性回归
在机器学习中,我们有一系列输入变量,它们决定了输出的变量。在输入和输出变量之间存在着一定的关系。机器学习的目标就是把这个关系量化。

在线性回归中,输入变量与输出变量之间的关系表示为 y=ax+b 等式形式的直线。因此,线性回归的目标就是寻找系数 a 和 b。在这个例子中,b 是直线的截距,a 是直线的斜率。
图 1 是绘制出的数据集中的 x 和 y 值。该算法的目标是拟合这条直线使它与大多数点最接近。这将会减少数据点的 y 值和直线之间的距离(也就是“误差”)。
逻辑回归
线性回归的预测结果是连续的值(以厘米为单位的降雨量)。然而,通过应用一个转换函数,逻辑回归预测的是一系列离散的值(一个学生是否通过测验)。
逻辑回归最适合解决二分类问题(数据集中 y 要么等于 0,要么等于 1,其中 1 表示默认类别。例如,在预测一个事件是否会出现时,事件发生被分类为 1。在预测一个人是否生病时,生病的样本会被记为 1。它以其模型中使用的转换函数来命名 --- 逻辑函数(Logistic function)h(x)=1/(1+e^x),该函数是一个 S 形的曲线。
在逻辑回归中,它的输出是默认类别的概率(不像线性回归中输出是直接产生的)。由于输出是概率,它的范围落在 0 和 1 之间。它的输出变量(y 值)通过使用逻辑函数 h(x)=1/(1+e^x),把 x 值进行 log 转换而产生。后续在使用一个阈值来让概率值转变成二分类的结果。
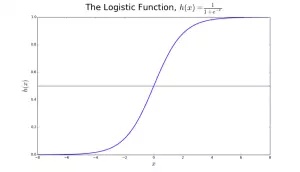
在图 2 中,确定肿瘤是否是恶性肿瘤,默认值是 y=1(肿瘤是恶性的);x 变量可以是肿瘤的一个度量值,例如肿瘤的大小。正如图片中所示,逻辑函数把数据集中的 x 值转换到 0 至 1 的范围里。如果概率值超过了 0.5 的阈值(如图中的水平线所示),肿瘤就会被分类为恶性的。
逻辑回归等式 P(x) = e ^ (b0 +b1 * x) / (1 + e^(b0 + b1 * x)) 可以被转换为 ln(p(x) / 1-p(x)) = b0 + b1*x。
逻辑回归的目标是使用训练数据去找出能够最小化预测结果与实际结果之间误差的系数 b0 和 b1。这些系数可以通过最大似然估计的方法得出。
CART
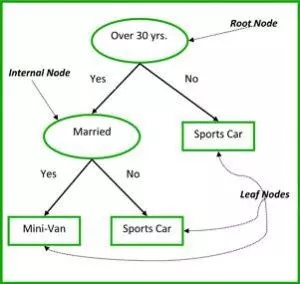
分类和回归树(Classification and Regression Trees,CART)是一种决策树的实现,除此之外还有其他的实现,例如,ID3,C4.5。
非终结节点是根结点和内部节点。终结节点是叶子节点。每一个非终结节点代表一个输入变量(x)并把数据点在该变量上分开;叶子节点代表输出值(y)。该模型是以这样的方式来进行预测的:遍历树中的每一个分支,达到叶子结点并以叶子结点代表的值为输出。
图 3 中的决策树可以通过一个人的年龄和婚姻状况来分类一个人是会买跑车还是买面包车。如果一个人超过 30 岁并且没有结婚,我们将会这样遍历这个树:“是否超过 30 岁?" -> 是 -> "是否已婚?" -> 否。因此,该模型的输出就是跑车。
朴素贝叶斯
给定一个已经发生的事件,要计算另一个事件发生的概率,我们会使用贝叶斯定理(Bayes’ Theorem)。给定某些变量的值,计算某一种结果出现的概率,换句话说就是,根据给定的先验知识(d),要计算假说(h)为真的概率,我们这样来使用贝叶斯定理:
P(h|d)= (P(d|h) * P(h)) / P(d)
其中
P(h|d) = 后验概率。在给定数据 d 符合 P(h|d)= P(d1| h)* P(d2| h)*....*P(dn| h)* P(d) 的条件下,假说 h 为真的概率。
P(d|h) = 可能性。在给定假说 h 为真的条件下,数据 d 符合条件的概率。
P(h) = 类别先验概率。假说 h 为真的概率(与数据无关)。
P(d) = 预测者先验概率。数据符合条件的概率(与假说无关)。
该算法叫做“朴素(naive)”贝叶斯是因为它假设所有的变量是相互独立的,这是一个对于真实世界而言非常幼稚的假设。
以图 4 为例,如果“天气”为“晴天(sunny)”,那么输出结果是什么?
根据“天气”变量的值为“晴天”,要想预测“玩耍“的输出是”是(Yes)“还是”否(No)“,我们需要计算 P(yes|sunny) 和 P(no|sunny) 的值并选择最高概率的结果为输出。
->(yes|sunny)= (P(sunny|yes) * P(yes)) / P(sunny) = (3/9 * 9/14 ) / (5/14) = 0.60
-> P(no|sunny)= (P(sunny|no) * P(no)) / P(sunny) = (2/5 * 5/14 ) / (5/14) = 0.40
因此,如果“天气”是“晴天”,输出的“玩耍“就为”是“。
K 近邻(KNN)
k 近邻算法使用所有的数据作为训练数据集,而不是把数据集分为训练集和测试集。
当我们需要预测一个新样本的输出时,KNN 算法将会遍历整个数据集来寻找 k 个最接近的样本,或者说是 k 个和新样本最相似的样本。然后,如果是一个回归问题,算法将输出这些样本结果的均值;如果是一个分类问题,算法将会输出出现次数最多的类别。k 的值是用户自己选定的。
样本之间的相似度通过计算例如欧几里得距离(Euclidean distance)或者汉明距离(Hamming distance)得到。
五、无监督学习算法
Apriori
Apriori 算法用在事务性数据库中发掘频繁项集,然后生产关联规则。该算法广泛应用与购物篮分析,用户把一些商品组合放入购物车,导致这些条目在数据库中频繁地同时出现。一般来说,我们把这样的关联规则,“如果一个人买了商品 X,然后他又买了商品 Y,写作:X -> Y。
例如:如果一个人买了牛奶和糖,那么很可能也会去买咖啡粉。这可以被写成这样一个关联规则:{牛奶,糖} -> 咖啡。当支持度(support)和置信度(confidence)超过阈值之后,关联规则就会被建立。
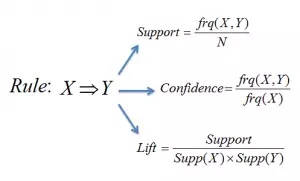
在考虑生成高频项集时候,支持度能够帮助削减候选项集的数量。这个支持度以 Apriori 原则为指导。Apriori 原则指出,如果一个项集是频繁的,那么它的所有子集也必须是频繁的。
K-means
K-means 是一个把相似的数据分组的迭代算法。它计算 k 个聚类的重心然后向这个聚类中添加一个数据点,使其与重心的距离最小。

步骤一:k-means 初始化
a) 选择一个 k 的值。在这里,我们令 k 等于 3。
b) 随机地把数据点放到 3 个聚类中。
c) 分别计算每个聚类的质心。图中红色、蓝色和绿色星星表示每个聚类的质心。
步骤二:把每个观察结果放入一个聚类中
重新把每个最靠近质心的点放入聚类中。在这里,上面的 5 个点被放入了蓝色的质心对应的聚类中。按照相同的步骤将点分配给包含红色和绿色质心的聚类。
步骤三:重新计算质心
计算每一个新聚类的质心。旧的质心以灰色显示,新的质心以红色、绿色和蓝色星星显示。
步骤四:迭代直到没有新的变化
重复步骤二和步骤三,直到数据点不在聚类与聚类之间交换。一旦两次连续的步骤之间没有点的交换,就退出 k-means 算法。
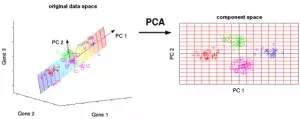
主成分分析
主成分分析(Principal Component Analysis,PCA)通过减少变量的数量,使数据易于探索与可视化。该算法通过捕获数据中最大的方差,把数据转换到新的坐标系统中,其中的坐标轴即为“主成分”。每个成分是原始变量的线性组合并且与其他主成分正交。正交性意味着各个成分之间的相关性为零。
第一个主成分捕获了数据中方差最大的一个方向。第二个主成分捕获的是剩余数据中的方差,但是其中的变量与第一个主成分没有任何的相关性。相似地,所有后续的主成分(PC3,PC4 等)就捕获了剩余的方差并且与之前的主成分没有任何相关性。
六、集成学习技法
集成学习意味着把多个学习算法(分类器)的结果,通过投票或者平均的方法结合起来,以获得更好的效果。投票用于分类问题,平均用于回归问题。这个主意好在他能够集成多个学习算法来获得比单个学习算法更好的结果。
现在有三种集成学习算法:套袋(Bagging),提升(Boosting)和堆叠(Stacking)。我们这篇文章不会介绍堆叠,但是如果你想知道关于它的详细介绍,请在下方评论区评论,那么我会写另一个博文来介绍它。
以随机森林来套袋
随机森林(多个学习算法)是一个在套袋决策树(单个学习算法)算法上所进行的改进。
套袋法(bagging)的第一步是通过 Bootstrap Sampling 方法在数据集上创建多个模型。在 Bootstrap Sampling 中,每一个生成的训练集由一些原始数据集中的随机子样本组成。每一个这样的训练集都和原有数据集的数据量相同,但是一些数据记录可能重复多次而有些有可能不会出现。然后,完整的原始数据集将会作为测试集使用。所以,如果原始数据集的大小为 N,那么每一个生成的训练集大小也是 N,其中独一无二的数据大概有(2N/3)个;测试数据集的大小也为 N。
套袋法的第二步是在不同的训练集上用相同的算法创造出多个模型。在这种情况下,让我们讨论一下随机森林。一般的决策树的每个节点都会选取能够最小化误差的特征作为分界线。而不同于一般的决策树,随机森林会随机地选择一个特征并构造一个在该特征上最好的分界线。使用随机性的理由是:即使通过套袋,如果决策树在分裂时都选择最好的特征,这些模型最后都会有相似的结构和相关性很强的预测结果。但是,如果在随机的子集上创建决策树的分裂结构,然后再应用套袋,这就意味着我们能在子树上获得相关性更低的预测结果。
随机森林算法的参数指定了每次分裂时要搜索的特征数量。因此,在套袋随机森林算法中,每一个树都在一个随机采样的样本上训练并且每一个分裂都通过随机采样预测参数的方式来创建。
以 AdaBoost 来提升
a) 套袋是一种并行的集成,因为其每一个模型都是独立构建的。另一方面,提升(boosting)是一个顺序式的集成方法,它的每一个模型的建立都基于前一个模型的错误的修正。
b) 套袋方法主要涉及到的是“简单的投票机制”,每一个分类器通过投票得出最后的结果。这样的结果由多数并行模型来决定;提升方法涉及到“加权的投票“,每一个分类器仍然是通过投票得出最后的结果,但是后构建的模型训练时所使用的数据集会有所不同。这些数据集中被之前的模型分类错误的数据点会被赋予更高的权值。这是为了让后面的模型能修正前面模型的错误。
AdaBoost 代表适应性提升(Adaptive Boosting)。
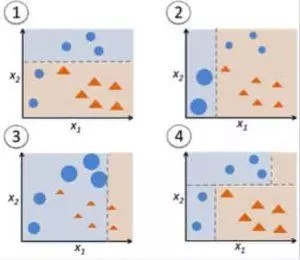
在图 9 中,步骤一、二和三涉及一个称为“决策树桩”的弱学习算法(一个单层的决策树,它指通过一个输入特征来进行预测,该决策树的叶子节点直接与根结点相连)。创建弱学习算法直到创建出足够多数量的弱学习算法模型,或者直到训练没有进一步改善。
步骤四结合了三个决策树桩模型(因此图中的决策树中有三个分裂规则)。
步骤一:以一个决策树桩开始,只通过一个输入特征进行预测
数据点的大小说明我们是通过应用相同的权值来分类他们是三角形还是圆形。这个决策树桩在图上展示为一条水平的直线,分类出了上半部分的一些数据点。我们可以看到,这里有两个圆形数据点被错误的分类为三角形。因此,我们会给这两个圆形数据点赋予更高的权值然后进行下一次决策树桩的训练。
步骤二:接着在另一个输入变量上训练下一个决策树桩
我们观察到 2 个被错误分类的圆形数据点比其他的点要大一点。现在,第二个决策树桩将会努力尝试把这两个圆形判断正确。由于我们给这两个点赋予了更高的权重,左边垂直的直线正确地分类了这两个圆形的点。但是,这个这导致它把上面的 3 个圆形数据点分错了。因此,我们将会给这三个圆形数据点赋予更高的权值,然后训练另一个决策树桩模型。
步骤三:继续在另一个输入变量上训练下一个决策树桩
上一个步骤中分错了的 3 个圆形数据点现在比其他的数据点都要大。现在,新生成的用来分类的决策树桩就是右边的那条垂直的直线。
步骤四:把决策树桩结合在一起进行预测
我们把这些从之前几个模型中产生的分隔线结合在一起,然后我们就能看到,与之前的每个弱学习算法相比,这个模型中的复杂规则能够把这些数据点全部分类正确。
七、结论
回顾一下,我们学了:
五个监督学习算法:线性回归、逻辑回归、CART、朴素贝叶斯和 KNN
三个无监督学习算法:Apriori、K-means 和主成分分析
两个集成学习技法:以随机森林来套袋和以 AdaBoost 来作提升
原文链接
https://www.kdnuggets.com/2017/10/top-10-machine-learning-algorithms-beginners.html






大厂都在用的商业智能(BI)软件
Wyn Enterprise
- 4.2
(49)咨询产品免费试用DigiPrime
- 4.7
(36)咨询产品免费试用微软 Power BI
- 3.8
(53)咨询产品免费试用



限时免费的商业智能(BI)软件
亿信ABI
- 3.9
(23)咨询产品免费试用派可数据
- 4.4
(31)咨询产品免费试用思迈特Smartbi
- 3.9
(28)咨询产品免费试用



新锐产品推荐
中标麒麟安全云操作系统
- 0.0
(0)咨询产品免费试用中标麒麟安全邮件服务器
- 0.0
(0)咨询产品免费试用FlexOffice自主安全协同办公平台
- 0.0
(0)咨询产品免费试用Flex档案管理系统
- 0.0
(0)咨询产品免费试用Flex资产管理系统
- 0.0
(0)咨询产品免费试用Flex合同管理系统
- 3.9
(8)咨询产品免费试用







