数据缺失的坑,无监督学习这样帮你补了
大数据文摘作品,编译:Chole、糖竹子、saint
经常被数据里的NaN值困扰,又不想昧着良心用均值填充?本文介绍了几种常见的数据缺失值处理方法,其中一些用到了聚类算法。
无监督学习(UL)有很多没开发的潜力。它是一门从“未标记”数据中推导一个函数来描述其隐藏结构的艺术。但首先,从数据中找到其结构是什么意思呢? 让我们来看以下两个例子:
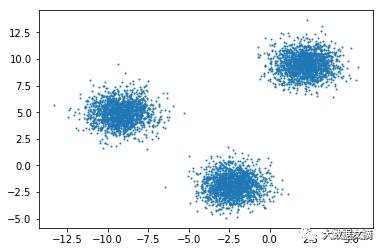
Blobs
气泡状分布:这个简单。任何人看到这张图都会认为它是由三个不同的簇组成的。如果你对统计学非常熟悉,你可能还会猜想它由三个隐藏的高斯分布构成。对一个新的数据样本,查看它的位置,人们就能推断出它属于哪一簇。

Wavy hi
波浪分布:这个就有难度了。它有明确的结构,但我怎么教计算机提取出这一结构呢?为了让你更好地理解这个问题,想象一下我找来1000人,问他们在这张图中看到了几个簇。结果很可能是这样,回答2的人最多,也有人回答3、4,甚至1!
所以说对数据的结构,连人都无法达成共识,那怎么可能教计算机学会呢?这里的症结在于,对于什么是簇,或者广义地说什么是“结构”,没有统一的定义。人们可以研究一下日常生活的某个方面,看它有没有结构,但这也会根据环境或其中涉及的人的变化而变化。
很多著名的无监督学习算法,比如层次聚类,K-Means,混合高斯模型或隐马尔可夫模型,对同一问题可能得到不同的答案,依我拙见,对于找结构问题,没有所谓更好的或更正确的普适方法(真的吗?又是没有免费的午餐定理?)
那么让我们动手探索吧——
聚类方法
K-Means(scikit learn)
模糊K-Means(scikit fuzzy)
混合高斯模型(scikit learn)
用K-Means算法产生簇通常被称为“硬划分”,因为对一个样本和一个簇,只有属于和不属于两种关系。K-Means的改进版模糊K-Means算法是“软划分”或“模糊”,因为一个样本对每个簇都有隶属度。基于这些隶属度来更新簇的质心。
混合高斯模型https://github.com/abriosi/gmm-mml
这个包是论文Unsupervised learning of finite mixture models(有限混合模型的无监督学习)中提出的方法,用一个算法实现估计和模型选择。
数据集
1、占有率检测:这是一个没有缺失值的时间序列数据集,因此要人为刻意地进行空缺数据补全。这一数据集相对较小,有20560个样本和7个特征,其中一个模型预测变量为是否占有。(二元分类问题)。
2、Sberbank俄罗斯房价市场数据集:
这也是一个时序数据集,来自数月前结束的Kaggle竞赛。
将训练数据与俄罗斯宏观经济和金融部门的数据合并后,得到30471个样本,389个特征,其中一个是要预测的价格(回归问题)。
它有93列有缺失数据,有些NaNs(非指定类型数据)占比很大(> 90%)。
3、子宫颈癌(危险因素)数据集:
这一数据集有858个样本和32个特征,4个目标变量(不同医学测试指标的二元输出)取众数转化成1个目标变量。
它有26个特征有空缺值,有些NaNs(非指定类型数据)占比很大(> 90%)。
数据缺失值补全过程
先删去训练集和测试集中所有含有缺失数据的特征。利用留下的特征,对训练集应用聚类算法,并预测两组中每个样本的簇。加上删去的列,计算按照簇分组后每个特征的平均值(或均值,如果是定性的话)。所以现在我们有了每个簇未补全时的特征的平均值。

这里“普通补全”指的是每个样本都用以计算其所属簇的平均值/众数。
加权方法则用样本对每个簇的“归属度”。比如,在混合高斯模型(GMM)中,归属度是样本属于各个簇的可能性,在K-Means方法中,归属度基于样本与各个簇的质心的距离。
评分方法
除标准化之外,几乎没对数据集做任何处理。
对于时间序列数据集,从第一个样本算起对时间标记排序,在占有率检测数据集中转化成按秒计数,同理在俄罗斯房价市场数据集中按天计数。
完成插补后,用XGBoost在测试集进行评分。用负对数损失和均方误差作为评分度量。
得到簇的数目
最初考虑了“肘”或者说“膝”方法。当簇的数量取值在一定范围内时,画出不同聚簇方法的得分并从图中寻找肘部。
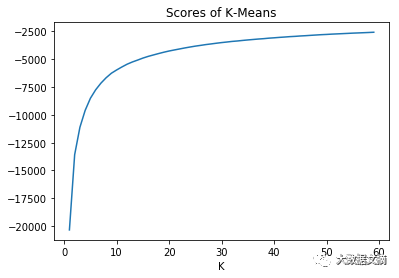
通过交叉验证,得到了一种比较有效但计算成本昂贵的方法。它是怎么工作的呢?首先选择一个分类器,然后对于一系列质心数目,进行无监督插补,并用该分类器进行K-fold交叉验证。最后选择在交叉验证中表现更好的质心数目。
结果
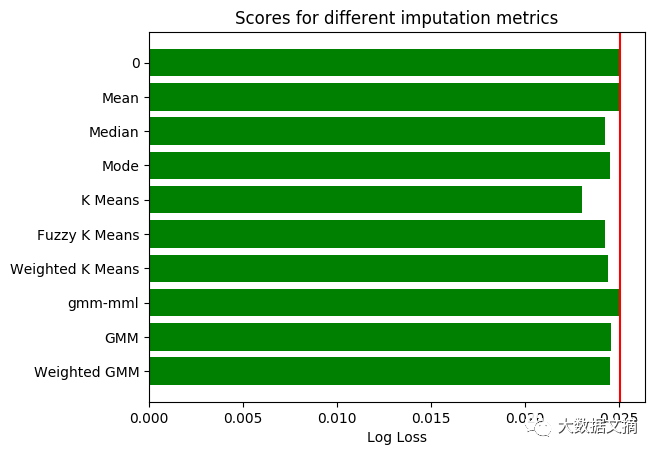
在条形图中,用红线标记平均值插补的分数,以便进行比较。
占有率检测数据集:
诚如之前提到的,这个数据集并没有缺失数据,所以只能模拟补缺行为。
对将要补缺的数据特征和样本应当谨慎挑选。不仅特别选择了数据特征,而且对是否选择样本设定了概率。如果概率为0.5,有50%的机会该样本将被丢弃。由于每次填补缺失值的样本选择都不同,我们将每三轮不同样本补缺的评分结果取均值,最后再对所有结果取均值。
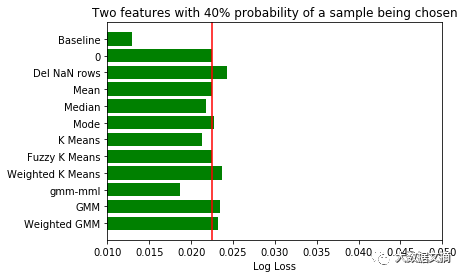
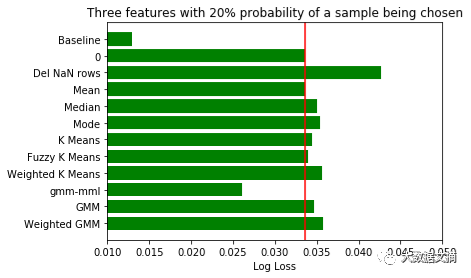
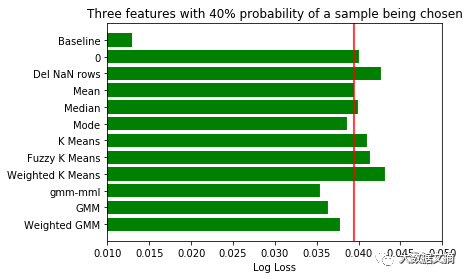
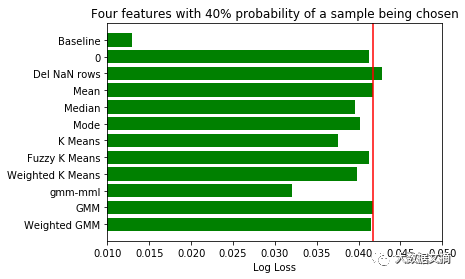
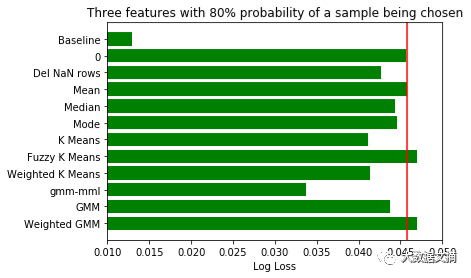
由于该数据集的数据量过大,怎样在有限的内存中完成聚类分析值得研究一番。我们放弃了使用全量数据做归类计算的打算,随机抽取了适合电脑内存的样本数据量(本次测试我选用了5000条记录)。
在原始数据集中使用随机抽样的方法抽取样本,也尽量保持了数据的时间结构。样本的数据量越大,反映的时间结构越准确。
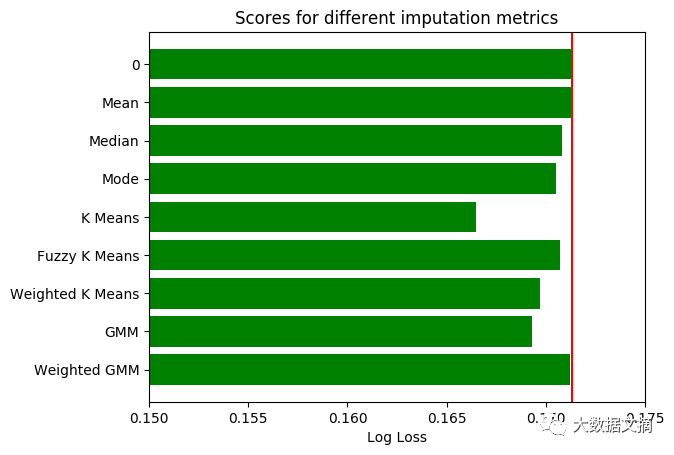
结果分析
根据结果,在数据分群的基础上选择补缺方式的表现比一般方法要好。
对于占有率检测数据集,表现最优的是GMM_MML分类算法,而对于房产市场数据和宫颈癌数据集,K_Means聚类算法更好。我们并没有对房产市场数据使用GMM_MML算法,因为它包含太多特征,而协方差的计算对于多特征数据比多样本量数据更加困难。
在增加占有率检测数据集的缺失数据后,整体上可以观测到,无监督的补缺方法比均值补缺表现要好。因此,当数据集有缺失值占比较高时,先探索数据结构再补缺方法反而形成一种优势。
大家会注意到,当使用检测数据集的缺失数据特征从2个增加到4个,且用于聚类的特征数量减少时,无监督补缺方法比均值补缺表现稍好。这种反常的现象可能是由于特定的数据集和选择的特征造成的。
同时,自然的,当缺失数据占比增加时,评分与基线分数的差距越来越大。
在三种K_Means算法中,普通型表现优于其他两种。这种算法每次迭代的计算量也最小,是最佳选择。
基于GMM方法的表现优于K-Means算法,这一现象十分合理,因为K-Means算法是GMM算法在欧式距离计算上的启发式算法。欧式距离能有效测量低维数据,但在高维空间上,其含义开始失真。如想了解更多信息,请看这里(https://stats.stackexchange.com/questions/99171/why-is-euclidean-distance-not-a-good-metric-in-high-dimensions/)。GMM算法是基于样本所属概率密度函数的可能性,能更好的衡量高维空间距离。
结论
尽管基于聚类的缺失值补充算法没有明显高过其他算法的优胜者,我们还是建议选择基于GMM的算法。
想找到模型混合的最佳数量,使用交叉验证法会更好。尽管AIC准则和BIC准则需要大量计算,他们可以用于检测模型混合数量的范围。最佳数量会令准则值达到最小。
计算协方差矩阵有很多方法。这里介绍两种最常使用的:
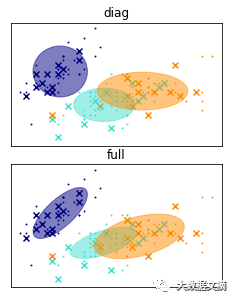
全协方差:这种协方差用于统计检测。每个部分有自己的广义协方差矩阵。
数据集中如果特征维度太多,使用GMM算法计算协方差矩阵,可能因为样本量不足计算错误,也可能因为使用全量数据耗时太久。因此建议使用对角协方差,更加平衡模型大小和计算质量。
如果数据量大大超过内存容量,应当从训练集中生成随机样本做聚类分析。
均值补缺的表现没有比基于聚类补缺方法差很多,因此也可以考虑使用。
后续工作
数据整理也可以尝试新方法:不再丢弃有缺失数据的特征,可以用均值或中位数填补缺失值,对修改后的数据集使用聚类分析。补缺可以在每个样本被标记后完成。
Finite Mixture Models (McLachlan和Peel著)这本书中提到NEC和ICL都是很好的方法。
也有更多无监督方法值得研究检测,例如,不同距离度量方法下的分级聚类。当然,普适的方法可能并不存在,毕竟没有免费的午餐。






大厂都在用的商业智能(BI)软件
Wyn Enterprise
- 4.2
(49)咨询产品免费试用DigiPrime
- 4.7
(36)咨询产品免费试用微软 Power BI
- 3.8
(53)咨询产品免费试用



限时免费的商业智能(BI)软件
亿信ABI
- 3.9
(23)咨询产品免费试用派可数据
- 4.4
(31)咨询产品免费试用思迈特Smartbi
- 3.9
(28)咨询产品免费试用



新锐产品推荐
汇高ERP系统
- 0.0
(0)咨询产品免费试用速脉ERP
- 0.0
(0)咨询产品免费试用小圈ERP
- 0.0
(0)咨询产品免费试用杜特门窗通ERP
- 0.0
(0)咨询产品免费试用秘奥服装工厂ERP系统
- 0.0
(0)咨询产品免费试用紫日数字化ERP
- 0.0
(0)咨询产品免费试用







