能给电影自动配音的“卷积神经网络”,是如何实现图像识别的?
“图像识别”是一个非常有趣,但十分富有挑战性的研究领域。本文将使用卷积神经网络来介绍“图像识别”的概念、应用和技术方法。
什么是“图像识别”?它的作用是什么?
从“机器视觉”的角度来说,“图像识别”就是软件识别图像中出现的人物、地理位置、物体、动作和文字的能力。计算机可以使用“机器视觉技术”,并结合人工智能软件和一个摄像头,完成图像识别。
对人类大脑和其他动物大脑来说,识别物体是非常简单的;但是对于计算机,这样的识别却是相当困难的。当人类看到一棵树、一辆车,或者是一个朋友,能立刻说出看到的是什么,根本不需要有意识地研究和思考。然而对于一台计算机来说,识别一个物体(可能是一个时钟、一张椅子、一个人或者是一只动物)是一个非常困难的问题,而且寻找这个问题的解决办法具有相当高的风险。
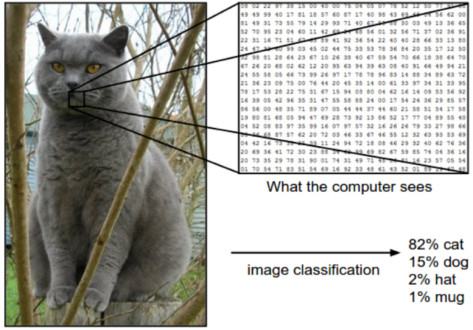
图片: CS231.github
图像识别是一个机器学习方法,它是专门模仿人类大脑运行方式的。通过图像识别,计算机将学会识别图像中的视觉对象和视觉元素。使用庞大的数据集和各种新兴的模式,计算机能够理解图像,并且用公式表达出相关的标签和类别。
图像识别的普遍应用
图像识别有着非常广泛的应用,其中的“个人照片管理”是最常见,同时也是最受欢迎的应用。面对成千上万张繁杂的照片,几乎每个人都想根据照片主题把它们一一分类,整理成有序的照片集。
现在,那些用于照片管理的应用程序正在使用“图像识别”技术。除了为用户提供照片的存储空间,这些应用程序还希望通过“图像自动管理”,进一步为人们提供更好的照片搜索功能。应用程序中的图像识别编程接口能够根据不同的识别模式将图像进行分类,并且将它们按照主题一一分组。
图像识别的其他应用还包括——照片和视频网站、互动营销、创意活动、社交网络上的面部及图像识别,以及庞大数据集下的网络图像分类等。
图像识别是一项相当困难的任务
图像识别并不是一件容易的事,实现它的一种好办法是将元数据应用于非结构化的数据。雇佣人类专家来手动地标记音乐曲库和视频库看似是一项十分艰巨的任务,但是一项更不可能完成的任务是——教会一个无人驾驶汽车的导航系统区分道路上的行人和其他车辆,或者让导航系统对出现在社交媒体上的成千上万的视频和照片进行过滤、分类和标记。解决这一问题的方法之一是利用神经网络。理论上,我们可以利用卷积神经网络来分析图像;但实际上从计算的角度来看,这样做的成本非常高。举例来说,即使是一个处理一张很小的图像(假设是30*30像素)的卷积神经网络,仍需要五十万的参数和900个输入。一个功能相对较强大的机器还能够处理这样的图像,但是一旦图像变得更大了(比如处理一个500*500像素的图像),那么相应地,参数和输入的数量也会增加到非常高的水平,同一机器就不一定能完成。
将神经网络应用于图像识别出现的另一个问题是:过度拟合。简单来说,当一个模型将自己调整到与训练数据非常相近时,就会出现“过度拟合”。“过度拟合”会造成更多的参数,进一步增加计算成本,而且模型在新数据上的训练会导致总体性能的损失。
卷积神经网络
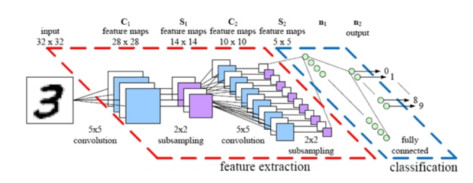
卷积神经网络架构模型(图片: Parse)
对于神经网络结构,一个相对简单的改变就能够让更大的图像更易于管理。其结果就是我们所说的“卷积神经网络”(CNNs或ConvNets)。
神经网络的普适性是其优势之一,但是这个优势在处理图像时却变成了一种负担。这个卷积神经网络有意识地做了一个权衡:如果一个神经网络是专门用于图像处理的,那么为了达到更加可行的解决方案,就必须牺牲其部分普遍适用的特性。
任何一张图像,其邻近性和相似性有着密切的关系,而卷积神经网络正是利用了这一关系。这就意味着,在一张给定的图像中,两个相邻的像素比两个分开的像素更具有相关性。然而,在一个普通的神经网络中,所有的像素都与所有神经元相连。在这种情况下,额外的计算负担会降低网络的准确度。
卷积神经网络通过删除这些不必要的连接来解决这个问题。从技术层面来看,卷积神经网络通过邻近程度对连接进行筛选和过滤,进而让图像处理在计算上更加可行。在一个给定的层中,卷积神经网络并不是简单地将所有输入与所有神经元相连,而是有意识地限制这些连接,这样,任意一个神经元都只会接收来自该层的一小部分输入。也就是说,网络的每个神经元都只负责处理图像的某一部分。(这与我们大脑皮层神经元的运行方式高度相似——大脑的每个神经元只会对你视觉感受的一小部分作出反应。)
“卷积神经网络”的处理流程
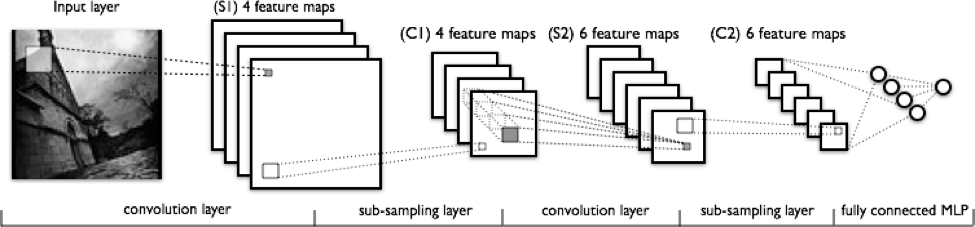
图片: deeplearning4j
从左到右观察上图,你会发现:
输入的图像将会经过特征扫描处理,图中浅色的矩形就是进行特征扫描的滤波器。
“激活映射”是一层一层相互叠加的,一个“激活映射”对应一个滤波器。较大的矩形将会在下一批被进行“下采样”。
“激活映射”通过下采样,被不断地压缩。
将滤波器在“激活映射”堆叠的层上传递,会产生一组新的“激活映射”,这些新的“激活映射”将首先被下采样。
第二次下采样会压缩新的“激活映射”。
一个全连接的层指定了每个节点的输出为一个标签。
一个卷积神经网络如何通过邻近程度来过滤连接呢?其中的秘密就在于两个新的层:池化层和卷积层。接下来,我们将利用一个网络的例子,分解其过滤的流程。
第一步是卷积层,而卷积层本身也包含了几个步骤。
首先,我们把一张照片分解成一系列重叠着的3*3像素块。
之后,我们在保持权重不变的情况下,将各个像素块运行于一个简单的单层神经网络。这么做将会使这一系列像素块变成一个数组。因为我们已经把图片分解成很小的像素块了(在本案例中是3*3的像素块),所以其神经网络的操作就变得简单多了。
接着,输出值将会被排列在一个数组中,其中的数字分别代表照片各个区域的内容,坐标轴分别代表颜色、宽度和高度。因此,在这个案例中会有一个3*3*3的数字表示。(如果是视频,那么数字表示就将变成四维的。)
下一步是池化层。它会池化这些三维或四维的数组,并且把下采样函数与空间维度结合应用。通过这样的操作,我们会得到一个仅包含重要的图像部分的池化数组,因为这个数组删减了不必要的图像部分,只保留了比较重要的部分,所以网络的计算负担被降到了最低,同时避免了过度拟合的问题。
这个经过了下采样处理的数组将会成为一个常规的全连接神经网络的输入。因为我们已经用池化和卷积大大地缩减了输入尺寸,所以我们现在需要一些普通网络能够处理的、可以保留最重要的数据的东西。而最后一步的输出将会用于系统对其图像判断有多少把握。
在现实生活中,CNN的流程纷繁复杂,涉及到许多隐藏层、池化层和卷积层。除此之外,真正的CNN通常包含了成千上万的标签。
如何建立一个卷积神经网络?
建立一个CNN是非常昂贵且耗时的。科技公司开发的API,目的是让组织在不需要内部机器学习专家或计算机视觉专家的情况下,也能达到目的。
Google Cloud Vision
“Google Cloud Vision”是谷歌的视觉识别API。它的建立以开源TensorFlow框架为基础,使用的是一个REST API。它包含了全面的标签数据集,能检测出人脸和物体。
IBM Watson视觉识别
“IBM Watson视觉识别”是“Watson开发云”的一部分,它有着一个庞大的内置类别集,能够根据你提供的图像对自定义的类进行训练。它还支持许多比较高端的功能,比如NSFW检测,OCR检测。
Clarif.ai
Clarif.ai是一个新兴的图像识别服务器,它使用的也是REST API。它带有能够调整算法的模块,这些模块能够将其算法调整至一个特定的主题,比如美食、旅行或婚礼主题。
虽然上面的API适用于一般的情况,但是最好针对单个任务定制一个专门的解决方案。幸运的是,现在的许多数据集可以让开发人员和数据科学家们专注于训练模型,处理好网络优化和计算方面的问题,他们的工作也将会变得相对轻松一些。
卷积神经网络的一个有趣应用
给无声电影自动配音
为了匹配一个无声视频,系统必须在视频中合成声音。这个系统利用上千个视频进行训练,这些视频中包含了鼓棒敲击不同表面发出的不同声音。一个深度学习模型将视频的各个帧与预先记录的声音库联系起来,选出一个与视频场景最匹配的声音。然后,这个系统将会由一个测试装置进行评估,这个测试装置与人类用来判断真声或假声(合成声音)的装置非常类似。不得不说,这是一个非常特别、有趣的卷积神经网络和LSTM递归神经网络应用。请看下面的视频:
注:本文由「图普科技」编译,您可以关注微信公众号tuputech,体验基于深度学习的「图像识别」应用。

思维导图/流程图相关的软件
MindMaster
- 3.7
(64)咨询产品免费试用亿图图示
- 3.4
(43)咨询产品免费试用ProcessOn
- 3.9
(431)咨询产品免费试用



大厂都在用的思维导图/流程图软件
Xmind
- 4.0
(626)咨询产品免费试用幕布
- 3.8
(65)咨询产品免费试用万彩脑图大师
- 3.8
(21)咨询产品免费试用



限时免费的思维导图/流程图软件
坚果云思维导图
- 3.8
(23)咨询产品免费试用知犀
- 3.6
(52)咨询产品免费试用迅捷画图
- 3.6
(57)咨询产品免费试用



新锐产品推荐
139邮箱
- 4.0
(4)咨询产品免费试用189邮箱
- 4.0
(1)咨询产品免费试用视觉中国
- 4.2
(17)咨询产品免费试用大象慧云-供应链协同管理
- 0.0
(0)咨询产品免费试用搜狐邮箱
- 3.0
(2)咨询产品免费试用TOM邮箱
- 0.0
(0)咨询产品免费试用







