Google 推出分布式深度学习系统TensorFlow,能像 Android 一样带来 AI 复兴?
编者按:在激烈的商业竞争中,更快的训练速度是人工智能企业的核心竞争力。2015年,Google 开源了其人工智能深度学习系统 TensorFlow,但该版本只能在一台机器上单独运行。昨天,Google 发布分布式 TensorFlow,这意味着它能够真正大规模进入到人工智能产业中,产生实质的影响。本文转载自微信订阅号“新智元”,36氪稍做调整,您可关注 “新智元”(Al_era)了解更多人工智能最前沿资讯。
去年,谷歌向全世界开放了人工智能深度学习系统 TensorFlow。此前,TensorFlow一直为像图像识别和邮件自动回复等谷歌各大产品提供相应的支持,而开源则意味着从此以后,所有的个 人、企业和组织都可以用站在谷歌的肩膀上,借用它的技术来开发自己的AI应用。
Google 创始人 Eric Schmidt 坚信 TensorFlow 是 Google 的未来。深度学习引擎+云服务平台,将会带来编程范式的改变:不仅给电脑编程,而且让电脑拥有一定的自主能力。
根据 Github 的数据统计,TensorFlow 成为了 2015 年最受关注的六大开源项目之一。2015年12月,TensorFlow 发布,仅一个月的时间就成为世界关注的焦点。
不过那时候的 TensorFlow 还仅仅是只能在一个机器上运行的单机版本。这意味着它虽然设计精巧,但很难被公司、组织大规模的使用,也很难对产业造成实质的影响。
昨天发布的分布式 TensorFlow,最突出的特征是能够在不同的机器上同时运行。虽然说并不是所有人都需要在几千台服务器上运行 TensorFlow,但研究者和创业公司的确能在多台机器运行的 TensorFlow 中获益。
TensorFlow 技术负责人 Rajat Monga 解释了分布式 TensorFlow 的延期发布:“我们内部使用的软件栈(Software Stack),和外部人们使用的非常不同......所以要让它变得开源,对于我们来说是极其困难的事情。”
经过 5 个月的等待,分布式 TensorFlow 终于到来了。
昨天,Google 发布了 TensorFlow 0.8,它有一些很好的改进。它为分布式的版本做了一些改变,而且使之更容易使用。以下内容还介绍了用分布式系统训练卷积图像识别模型的一些可扩展的数字。
TensorFlow:
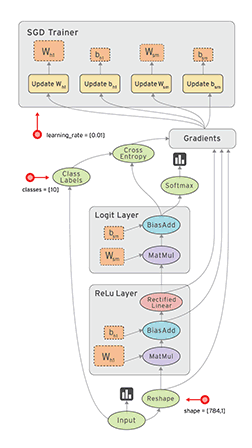
TensorFlow 是为使用数据流程图的数值计算开发的开源软件库。图中的节点表示数学运算,而图的边代表着彼此沟通的多维数据阵列(Tensors)。在只使用单个 API 的情况下,灵活的架构可以让你在桌面、服务器或者移动设备的单个或多个 CPUs 和 GPUs 部署计算。TensorFlow 最早由 Google Brain 团队的研究人员和工程师研发,目的是管理机器学习和深度神经网络的研究工作,但是这个系统也足够通用,适用于其他的应用领域。
TensorFlow 0.8:支持分布式计算
Google 在很多的产品中都使用了机器学习技术。为了不断改进我们的模型,最为重要的是训练速度要尽可能的快。要做到这一点,其中一个办法是在几百台机器中运行 TensorFlow,这能够把部分模型的训练过程从数周缩短到几个小时,并且能够让我们在面对不断增加的规模和复杂性的模型时,也能够进行实验。自从我们开源了 TensorFlow,分布式的版本就成为最需要的功能之一了。现在,你不需要再等待了。
今天,我们很兴奋的推出了 TensorFlow 0.8,它拥有分布式计算的支持,包括在你的基础设施上训练分布式模型的一切支持。分布式的 TensorFlow 由高性能的 gRPC 库支持,也能够支持在几百台机器上并行训练。它补充了我们最近的公布的 Google 云机器学习,也能够使用 Google 云平台训练和服务你的 TensorFlow 模型。
为了和 TensorFlow 0.8 版本的推出保持一致,我们已经发表了一个“分布式训练”给 TensorFlow 模型库的生成图像分类的神经网络。使用分布式训练,我们训练了生成网络(Inception Network),在 100 个 GPUs 和不到 65 小时的训练时间下,达到了 78% 的正确率。即便是更小的集群,或者只是你桌子下面的几台机器,都可以受益于分布式的 TensorFlow,因为增加了更多的 GPUs 提升了整体的吞吐量,并且更快生成准确的结构。
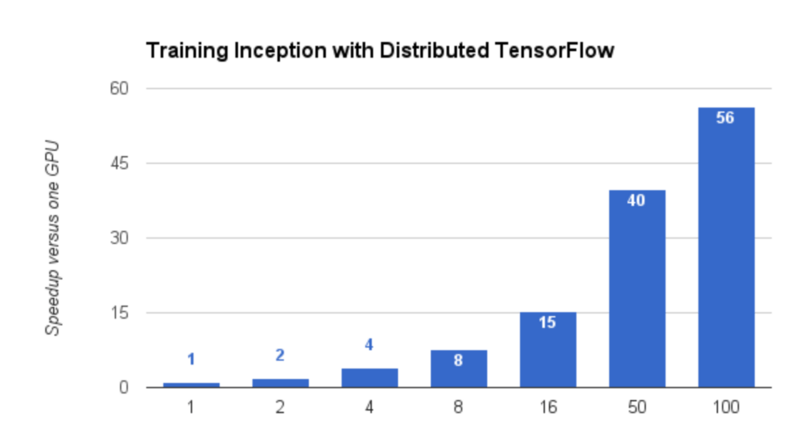
分布式训练也支持你使用像 Kubernetes 这样的集群管理系统,以进行扩大规模的训练。更进一步说,一旦你已经训练了模型,就可以部署到产品并且加快在 Kubernetes 使用 TensorFlow 服务的推理速度。
除了分布式生成器,TensorFlow 0.8 还发布了定义你自己分布式模型的新库。TensorFlow 分布式架构允许很灵活的定义模型,因为集群中的每个进程都可以进行通用的计算。我们之前的系统 DistBelief(像很多追随它的系统)使用特殊的“参数服务器”来管理共享的模型参数,其中的参数服务器有简单的读/写接口,以更新共享的参数。在 TensorFlow 中,所有的计算,包括参数的管理,都会在数据流的图中呈现,并且系统会把数据流映射到不同设备的可用处理器中(例如多核 CPUs,一般用途的 GPUs,手机处理器等)。为了让 TensorFlow 更好使用,我们也推出了 Python 的库,使之更容易写模型,在一个处理器中运行,并且扩展到使用多个副本以进行训练。
这种架构使得它可以更容易的扩大单进程的工作到集群中,同时还可以进行新颖的分布式训练架构的实验。举个例子,我的同事最近展示了“重新访问分布式同步 SGD”(Revisiting Distributed Synchronous SGD),在 TensorFlow 图部署,实现了在图像模型训练中更好的“时间-精度”。
目前支持分布式计算的 TensorFlow 版本还仅仅是个开始。我们将继续研究提高分布式训练表现的方法,既有通过工程的,也有通过算法的改进,我们也会在 GitHub 社区分享这些改进。
抢先尝试
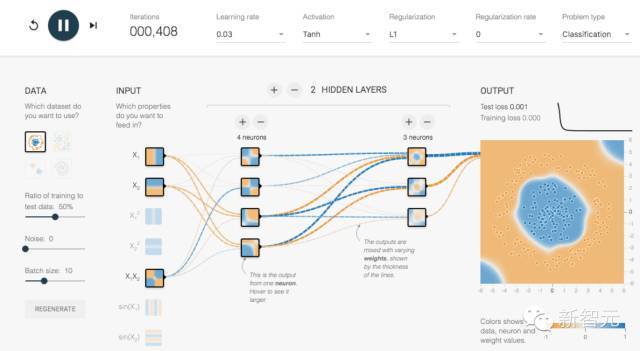
如果你想跳过复杂的按照过程,感受 TensorFlow,Google 提供了一个基于浏览器的模拟器,能让你感受基本的 TensorFlow 和深度学习。
首先在左边选择你要分析的数据,然后在中间选择和组合道具,最后看输出的结果是如何和最早的数据相匹配。最开始看起来会显得很可笑,但是这很好理解,而且能在抽象层面理解神经网络是如何运作的。



新锐产品推荐
玄讯
- 4.0
(12)咨询产品免费试用宠店宝
- 5.0
(1)咨询产品免费试用宠老板
- 0.0
(0)咨询产品免费试用蜗牛小店
- 4.5
(1)咨询产品免费试用快收银智能点菜宝
- 0.0
(0)咨询产品免费试用幻熊云仓
- 0.0
(0)咨询产品免费试用







