你以为社交媒体帖子=大数据集?其实它可能不如新闻媒体的文本可靠
编者按:本文来自微信公众号“全媒派”(ID:quanmeipai),作者 腾讯传媒,36氪经授权发布。
由于为全球范围内的对话提供了广泛的可能性,社交媒体如今成为“大数据”的代言人。平台巨大的规模、超快的更新速度和多样的内容被视为大数据时代教科书级的范例。
但是,当人们对社交媒体的数据价值格外重视,或许也该反向思考——社交媒体上的数据真的比新闻媒体这样的传统数据更多,更有价值吗?
在互联网数据领域深耕超过20年的互联网企业家及学者Kalev Leetaru以Twitter为例撰文指出,社交媒体的数据价值可能被人们高估了,而新闻媒体则被低估。本期全媒派跟随KalevLeetaru的视角,以严格的数据计算为支撑,破解大数据时代的数据价值迷思。

Kalev Leetaru:乔治华盛顿大学(George WashingtonUniversity)网络与国土安全中心高级研究员,曾任谷歌云平台开发专家
01.社交媒体“大”数据,没有想象中那么大
在今天,人们把社交平台看作大数据的缩影。但是值得注意的是,这些平台对外部的透明度不高,意味着它们的印象构建实际上都是基于这些公司自己向公众披露的数据和创造的美好概念,比如“活跃用户”。
这些数字一直在变化,概念也在不断演变,但唯一的目的都是反映整个社交媒体生态最美好的一面。
人们对社交平台的崇拜之情主要基于一个信念——它们的服务器拥有一个难以想象的大型全球人类行为档案。但是,与过去作为数据来源的传统媒体相比,社交媒体拥有的这个档案真的大得多吗?
就最近的事件来看,Facebook在去年开放了一个大型数据集,为学者研究提供材料,其中包括“1PB(千万亿字节)的数据,储存着全球Facebook用户点击过的几乎所有公开链接、点击发生在何时、以及点击的用户是什么类型的”。
但在专业人士的分析中指出,该数据集尽管是PB级别,但其在公布时预计仅包含300亿行,大概是每周从3亿帖子中生成200万个数据的增长速度。

Facebook与Social Science One建立合作伙伴关系,向其开放PB级别的用户数据,搭建业界与学界的桥梁
对于许多研究人员来说,300亿行听起来像是他们一生都分析不完的海量数据。然而,按照现代标准,300亿条记录是一个相当小的数据集,而PB级数据在大数据时代早已见怪不怪。
作为对比,Kalev Leetaru提出,自己的开放数据项目GDELT已经编制了一个数据库,该数据库自2018年3月以来已经从全球新闻媒体主页中收集超过850亿个外链。换句话说,它只用了一半的时间,却是Facebook数据集的2.8倍。

由Kalev Leetaru创建的GDELT是有史以来最大,最全面,最清晰的关于人类社会的开放数据库,每日监控世界各地的新闻媒体更新。
社交媒体与新闻媒体相比,其数据方面的差距并不一定像人们想象得那么大。之所以产生错误的想象,仅仅是因为历来缺乏将新闻媒体视为大数据工具的习惯。
而相比之下,社交媒体从一开始就积极地将自己与大数据挂钩,并在建设上最大限度地与数据分析靠拢。
02.Twitter的“大”数据库,研究价值有限
既然社交媒体在数据量上并没有人们想象得那样无敌,那么在数据的研究价值层面表现又如何呢?
社交媒体巨头Twitter虽然只成立了短短13年,但数千亿条推文赋予它厚度,每天成千上万人发推赋予它速度,而文字、图像和视频的混合则丰富了它的维度。
在全球范围内,Twitter都绝对称得上这场大数据革命重要的注脚。大量学者使用Twitter的数据进行研究,而KalevLeetaru指出,在Twitter的海量数据中,有研究价值的部分其实有限。
Twitter本身不定期公布推文数量的相关数据。然而,根据先前的研究推断,可以合理地估计,自13年前该平台成立以来,推文数量已累计超过一万亿条。
乍一看,一万亿是个非常庞大的数字。但从内容的角度考虑,推文实际上很小,因为毕竟它只是一个最多包含140个字符的文本。这意味着即使推文总量大,但每条推文传递的信息其实很少。
进一步来看,甚至很少有推文是接近140个字符的,每条英语推文平均包含34个字符,而日语推文平均仅包含15个字符。
此外,虽然Twitter的原始数据非常大,但其中只有4%是推文文本数据。由于大多数针对Twitter的分析是关注推文的文本,所以对社会分析有用的数据量其实非常小。
一万亿条140个字符的推文,也只产生140TB(太字节)的数据。而实际情况是,在2012年,Twitter上的推文平均长度为74B(字节),这意味着那万亿个推文的文本转化为数据,只有74TB。
而根据2012到2014年的状况推断,可以估计在这万亿推文中有35%是转推,那么有价值的数据可能要缩减到48TB。此外,这些文本中还包含着超链接、提到其他用户(@XXX)等内容,这些文字是也缺乏分析价值的。
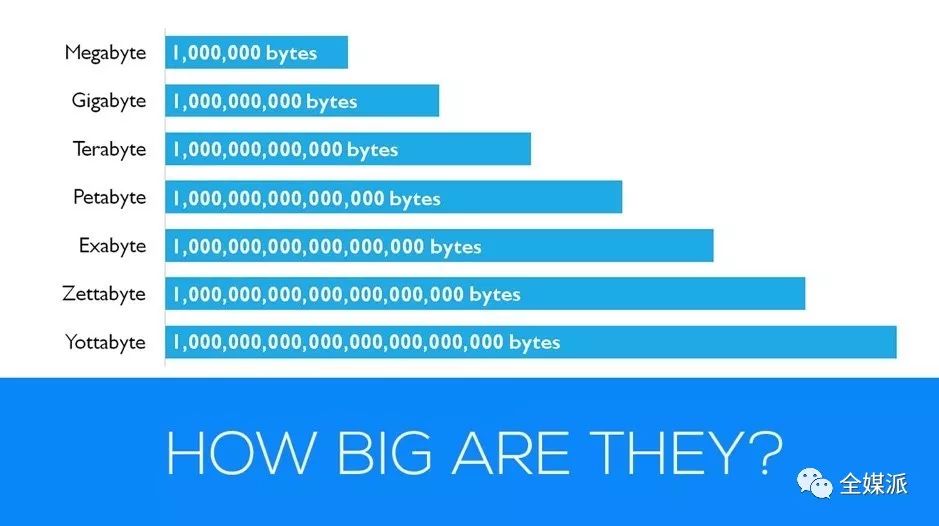
1TB约等于15个64GB的手机存储数据量
03.社交媒体VS传统媒体,谁掌握着大数据?
Twitter VS数字化书籍:
十三年的文本超越两个世纪的书籍?
2010年的Google Books NGrams中囊括了所有已出版书籍的4%,总计5000亿字,估计大小约为3TB,比Twitter的数据量小24倍。Internet Archive(互联网档案馆)的英语公共领域书籍文本总计约450GB,比Twitter小约85倍。
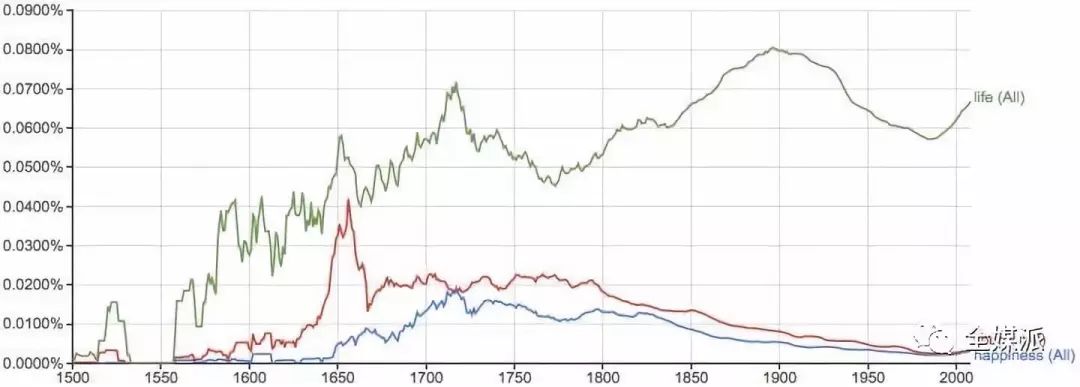
Google Books Ngrams Viewer:开放数据库,可以查询任何一个或几个词在过去500年内在书籍中的出现频率变化趋势。图中为“life,liberty,happiness”三词的结果

Internet Archive是一个非营利性的数字图书馆组织,提供数字数据如网站、音乐、动态图像、和数百万书籍的永久性免费存储及获取。
但是,Google和InternetArchive的数字化图书馆藏书只包含每本书的一个副本,因此将它们与转推无数的Twitter相比是不公平的。通过过滤转发可以发现,Twitter的数据量只是Google Books NGrams的16倍,是Internet Archive的公共领域书籍的54倍。
按照数据量来看,仅仅发展了13年的Twitter的数据量已经比今天研究人员可用的两个世纪的数字化书籍更大。但不可忽视的两个因素是:首先,数字化时代改变了出版的逻辑,以前出版一本书的成本太高,而在Twitter时代,个人“出版”的数量仅受限于敲键盘的速度。
其次,数字化的书籍只是人类历史上极小的一部分,从本质上讲,这是将Twitter在13年内的文本总数与两个世纪的书籍的4%进行比较。
Twitter VS在线新闻:
差距只有8倍
考虑到社交媒体与传统出版业的较大差别,更有代表性的比较需要找到具有类似特性的媒体。上文中提到,GDELT的新闻数据集在一半的时间内成为Facebook数据集的三倍,那么Twitter与新闻间的数据差异又是怎样?
从2014年11月至今,GDELT项目监控了大约3TB的新闻文章文本,该数据仅计算文章文本本身。在同一时期,可以根据Twitter的先前趋势估算,其推文总量应该在6000亿左右,假设转发量随时间逐渐增加,那么估计其中3300亿条不是转推。
如果按照每条140个字符计算,那么将达到大约84TB;按照平均每条74个字符计算,就是44TB,但如果不包括转推,这将降至仅24TB。
由GDELT检测发现,假设2006年至今发送的数万亿条推文都是140个字符,Twitter的数据量也仅是2014年至今全球在线新闻量的47倍。使用更为现实的平均推文长度来计算,Twitter的数据量是新闻的25倍,移除转发后则只是16倍。
值得注意的是,这是跨度13年和4年的比较。如果将两者都放在4年的时间内比较,那么Twitter的数据量只是新闻的15倍,移除转发后就只有8倍了。
因此,如果有人可以访问2014年至今完整的Twitter消息,那么在同一时间段内,其文本总量可能只是在线新闻内容总量的8倍左右。
从这个角度来看,Twitter是一个很大的平台,但它和全球新闻相比也不是天差地别,这也提醒了人们,每天在世界各地发布了多少新闻。
04.对学术研究而言,新闻比社交媒体更有价值
在现实中,只有极少数研究人员可以获得Twitter上所有的推文,最大的学术研究通常是使用Twitter Decahose进行的,其中仅包含每日推文的大约10%。2014年至今,Decahose上的数据仅为新闻的1.5倍。如果排除转发,新闻则会反超成为Decahose的1.2倍。
很少有大学有足够的财力支持去订阅Twitter Decahose,因此绝大多数基于Twitter的学术研究都是通过Twitter的搜索API(应用程式界面)进行的,该API仅提供每日推文的大约1%。在此情况下,新闻实际上是其数据量的6.7倍。如果排除转发,新闻将成为其的12.2倍。
Twitter Developer为学者研究提供开放数据
因此,就大多数学者所使用的这1%数据而言,Twitter在过去四年中实际上比同一时期的全球在线新闻输出的数据小几倍。而那些有幸与Decahose合作的学者获取的数据实际上也少于他们能从新闻中得到的内容。
更极端地假设,一个人可以获取Twitter上所有的信息,数据量也只是新闻的8倍。过滤掉所有超链接和提到别的用户(@XXX)的内容,该数字将进一步缩小。
简而言之,Twitter是一个庞大的数据集,这一点毋庸置疑。但就大多数分析所关注的实际文本内容而言,由于单条推文的字符有限,一万亿条推文实际上并没没有人们想象的那样有价值。

在许多方面,与传统的内容平台相比,Twitter更偏向于行为数据。最重要的是,即使在平台信息完全可接触的前提下,Twitter实际上也并不比新闻媒体这样的传统数据集大得多。
就大多数研究人员使用的Decahose和API而言,新闻媒体实际上提供了更大量的可分析内容,并且信息出处更明确,稳定性更高,历史背景更清晰。
大数据时代,社交媒体巨头在数据领域占优势已经成为共识,甚至塑造了对大数据工作的定义。然而,一万亿条推文可以迅速转化成几十TB的数据,这样快速而巨大的信息流通量中,有研究价值的部分其实很少。
而相比社交媒体,传统媒体却是巨大的未开发数据源。Twitter肯定符合大数据的所有定义,但通过仔细观察,结论是传统新闻业并不落后。唯一的不同只是,社交媒体积极突显自己与大数据的关系,而新闻业却未能在数字时代重塑自己。
通过社交媒体与书籍、新闻的对比,最重要的启示是,当我们不遗余力地将社交媒体神话化为大数据的集大成者,实际上更重要的是创造性思考如何利用围绕着我们的未开发数据,并将其带入大数据时代。



舆情监测软件相关的软件
识微商情监测系统
- 4.9
(2)咨询产品免费试用百分点-舆情洞察系统
- 5.0
(1)咨询产品免费试用Meltwater
- 4.1
(40)咨询产品免费试用



行业专家共同推荐的软件
五节数据-舆情监控系统
- 4.5
(1)咨询产品免费试用新浪舆情通
- 4.0
(1)咨询产品免费试用清博舆情
- 4.0
(1)咨询产品免费试用



限时免费的舆情监测软件软件
红麦舆情监测系统
- 0.0
(0)咨询产品免费试用中科微步科技
- 0.0
(0)咨询产品免费试用WJMonitor五节舆情
- 0.0
(0)咨询产品免费试用



新锐产品推荐
百草生意宝
- 3.9
(7)咨询产品免费试用百草仓管宝
- 5.0
(1)咨询产品免费试用百草商贸通
- 0.0
(0)咨询产品免费试用百草连锁王
- 4.1
(2)咨询产品免费试用百草智慧ERP
- 0.0
(0)咨询产品免费试用秘塔写作猫
- 0.0
(0)咨询产品免费试用







