为了挖掘大数据中的商业价值,“玻森数据”开放了一个中文语义分析 API | NEXT Big
每天由 36 氪 NEXT 为你解读一款最新产品,分析行业趋势,带来有价值的报道,更多新产品欢迎访问 NEXT 查看。
谈到大数据,我们可能会联想到自然语义分析。
我们曾经报道过“出门问问”,在“附近有什么好吃的?”这个问题上,它可以通过语音识别、语义分析加上搜索,快速告诉你答案,而这其中的核心技术,就是自然语义分析。
据“玻森数据”团队介绍,他们在语义分析技术与数据这个方向上已经有超过 7 年的积累,将实现算法优化到一个商业可用的效果。最近他们上线了新版的语义开放平台 BosonNLP,并全面免费开放给开发者。
所以到底什么是自然语义分析?现在的创业公司都面对着各种形式的大数据冲击,例如微博微信、客户反馈、邮件等等,如何充分利用解读和利用这些数据对于公司增强自身的灵活性和竞争力很重要,面对大数据意味着需要更大的数据处理能力。
相比于市场上其他同类产品,BosonNLP 提供了更为全面的服务,包括分词词性、情感分析、实体识别、依存文法、关键词提取、新闻分类、语义联想、文本聚类以及典型意见。
而分词词性的准确率一般会成为用户对于自然语言处理的首要考虑标准,例如这样一句话:
3 座石像分别是苏富比拍卖行归还的难敌石像。
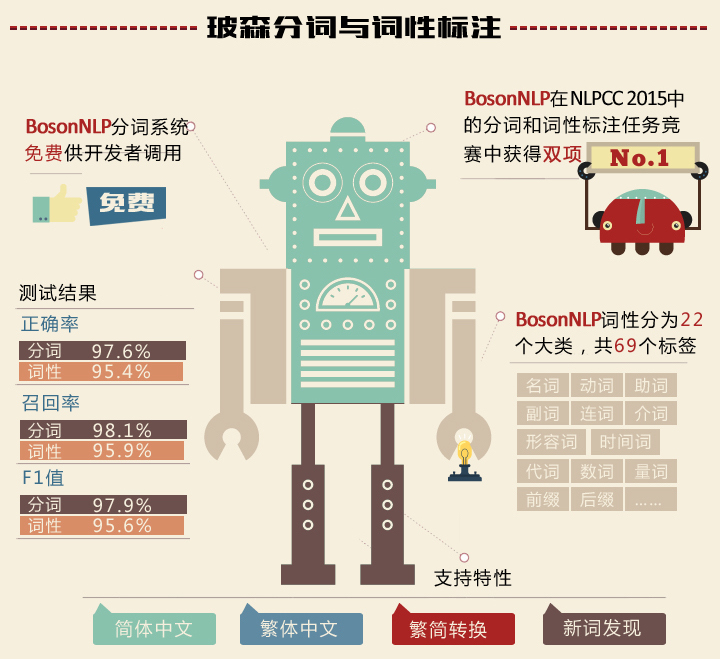
负责分词词性的标注引擎需要准确识别出“苏富比”是一个组织机构名称,以及“难敌”这个多重意思的特殊名词,才能将其准确标注。在今年 5 月份的 NLPCC 公开赛上,“玻森数据”在中文分词与词性标注两项比赛中以 96.65% 与 91.55% 的准确率获得第一。
除了分词词性的准确性,机器更难辨识的是人类自然语言中的情感部分,例如下面这一句话:
C 罗暴力头球破门。
机器需要将文本的情感分为正面和负面两类,而“暴力”一词很容易干扰机器判断,很多语义分析系统会将其判别为负面情感。BosonNLP 在情感分析的准确度可以达到 80% - 85%,并提供篇章级的分析能力。情感分析可用于汽车、餐饮以及电商消费中快速地找到正面或负面的评价。
相比于市面上其他的自然语义分析平台,“腾讯文智”还处于测试阶段,准确性和应用范围还比较小,“海量”则偏向于互联网营销与舆情监测服务,提供的 API 也很有限。
BosonNLP 所提供的是一个从基础的分词与词性标注,到文章的实体识别、情感判断,以及对多篇文本进行综合分析的完整系统。目前在咨询公司、媒体监测领域以及不少开发者的产品都有应用,其网站上提供了 10 类分析引擎 demo ,感兴趣的朋友可以去试试。

面对现在互联网上的海量信息,空谈大数据没有用,只有提供真正能处理数据的技术和方案才能挖掘其价值。
你的产品想登上 NEXT Big 的文章?欢迎把你创造的新产品分享到 36 氪 NEXT 上。



舆情监测软件相关的软件
识微商情监测系统
- 4.9
(2)咨询产品免费试用百分点-舆情洞察系统
- 5.0
(1)咨询产品免费试用Meltwater
- 4.1
(40)咨询产品免费试用



行业专家共同推荐的软件
五节数据-舆情监控系统
- 4.5
(1)咨询产品免费试用新浪舆情通
- 4.0
(1)咨询产品免费试用清博舆情
- 4.0
(1)咨询产品免费试用



限时免费的舆情监测软件软件
红麦舆情监测系统
- 0.0
(0)咨询产品免费试用中科微步科技
- 0.0
(0)咨询产品免费试用WJMonitor五节舆情
- 0.0
(0)咨询产品免费试用



新锐产品推荐
法大大
- 3.9
(319)咨询产品免费试用石墨文档
- 4.0
(89)咨询产品免费试用Teambition
- 3.7
(90)咨询产品免费试用微盟微商城
- 3.8
(36)咨询产品免费试用有道云笔记
- 4.0
(73)咨询产品免费试用聚水潭erp
- 4.1
(5)咨询产品免费试用







