从单色图像中重构高质量的3D对象几何图
从图像中重构数字化的3D几何图是“计算机视觉”中的一个核心问题。3D对象重构的应用非常广泛,比如电影制作、视频游戏内容生成、虚拟现实和增强现实、3D打印等等。本文将要讨论的任务是由一张单色图像重新构造出高质量的3D对象几何图。
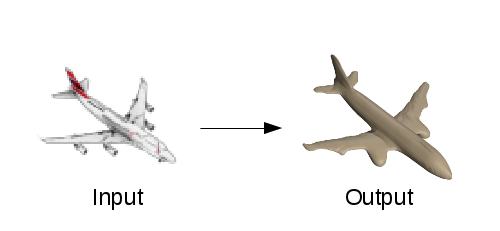
即使只看到一张图片,人类也能够毫不费力地推理出图片中的物体或是场景的形状。值得注意的是,我们可以通过眼睛轻松地感知深度,但是无法理解立体的3D几何。我们即使只看到了一张照片,也能较好地理解其中的对象的形状。另外,我们还能够推理出对象隐藏的部分,比如对象的背面。这对于掌握对象整体的形状非常重要。那么,我们首先面临的问题是——人类如何仅通过一张图像推理出途中对象完整的几何图形?从人工智能的角度来说就是,我们如何向机器传授这种“几何推理”的技能呢?
形状空间
我们可以根据比较模糊的图像输入,重构图中对象的几何图形。其中的基本原理是:对象形状都不是任意的,有些形状是可能的,但有些形状是不可能的。一般来说,对象的表面都是光滑的。在人为环境下,它们通常可能是呈片状的平面。而对象整体则适用于更高级的准则,例如:飞机通常都有一个机身,两侧各有两个主机翼,背面则是垂直尾翼。人类通过观察以及与周围环境的互动,能够比较轻易地掌握这一信息。而在计算机视觉中,由于所有的形状都不是任意的,所以我们能够将所有一个或多个对象类描述为一个低维度的形状空间,这些形状空间是从大量的示例图形中获得的。
用CNN进行立体像素预测
最新的3D重构工作之一利用了卷积神经网络(CNN)来对对象的形状进行3D空间的预测( Choy et al。ECCV 2016,Girdhar et al。ECCV 2016)。输出的3D空间会进一步被细分为空间元素,即立体像素;每个立体像素的赋值分为两种,分别是“已占用空间”或者是“非占用空间”,比如某一对象空间的内部和外部。输入的图片一般都是某一物体的单色图像,而卷积神经网络会利用up-convolutional解码器架构来预测该物体的占用空间。这个神经网络将会经过全程端对端的训练,并且受到来自综合CAD模型数据集的已知占用空间的监督。使用这个3D形式再现和卷积神经网络,复制一个能够适应各类对象的模型是完全有可能的。
分层表面预测
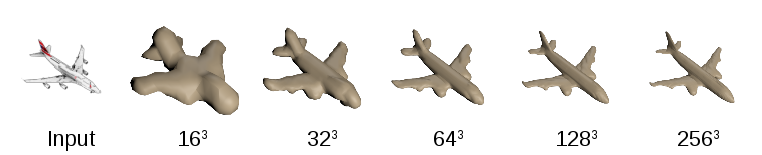
使用卷积神经网络进行占用空间预测的主要缺陷在于:模型输出的空间是三维的,因此随着分辨率的提高,输出空间相应地也会出现扩大。这一问题的出现导致我们模型无法预测出高质量的几何图形,因此它仅限于像素分辨率较低的图像。但我们认为,这其实是一个不必要的限制,因为对象的表面实际上都是二维的。
我们利用层次结构的二维性质,通过分层预测,仅在进行低分辨率预测的情况下对表面进行预测。其中的基本原理与“八元树表示法”有着密切的联系,这一表示法常用于多目立体视觉和深度映射融合,表示高分辨率的几何图形。
方法
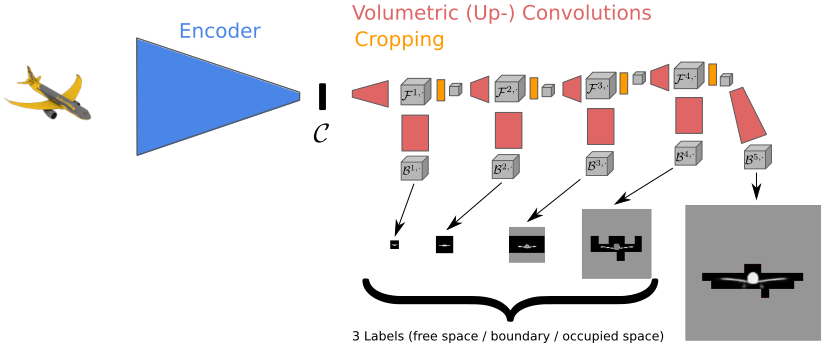
基本的3D预测流程首先会采用一张彩色图像作为模型的输入,这张图像将首先由卷积编码器编码成为一个低维度的对象再现。之后,这个低维度的对象再现将会被解码成为一个3D占用空间。我们这个方法叫做“分层表面预测”(HSP),主要原理是通过对低分辨率立体像素的预测来对图像对象进行解码。标准的做法是将每一个立体像素分类为“非占用空间”或“已占用空间”,而我们是将其分为三类,分别为“非占用空间”、“已占用空间”以及“分界线”。这样的做法使我们能够对低分辨率的输出进行分析,并且只对高分辨率的部分进行预测。通过不断地完善,我们逐层地预测了高分辨率的立体像素(如下图所示)。关于该方法的更多内容,你可以查看我们的技术报告。[Häne et al. arXiv 2017
实验
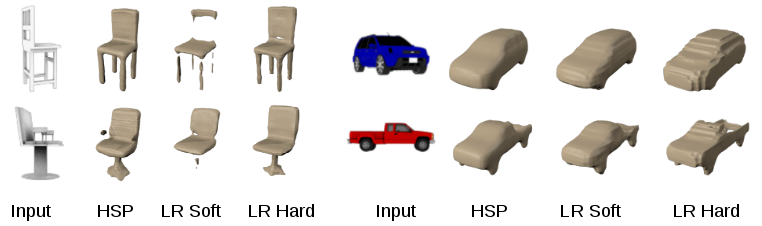
我们的实验主要是基于合成的ShapeNet数据集,我们研究的主要内容是根据一张单色图像,预测出其中对象的高分辨率的几何图形。我们将我们的方法与两个基准线——“硬低分辨率”(LR hard)和“软低分辨率”(LR soft)——做了对比,这些基准线都是323的分辨率进行预测的,但是它们在训练数据生成的方式有所区别。LR hard基准线为立体像素使用的是二进制赋值,如果至少有一个相应的高分辨率立体像素被占用了,那么所有的立体像素都会被标记为已占用。而LR soft使用的是分数赋值,在相应的高分辨率的立体像素中显示已占用的立体像素的百分比值。我们HSP的预测方法是在2563的分辨率进行预测的,下图中的数据反映了高分辨率预测与低分辨率基准线相比,在图形表面质量以及完整性方面的优势。你可以在我们的技术报告中找到更多的数据结果和相关的实验。

本文内容基于以下技术报告:
Hierarchical Surface Prediction for 3D Object Reconstruction, C. Häne, S.Tulsiani, J.Malik, ArXiv 2017
注:本文由「图普科技」编译,您可以关注微信公众号tuputech,体验基于深度学习的「图像识别」应用。



新锐产品推荐
有专自媒体助手
- 3.9
(7)咨询产品免费试用捷云智慧科技
- 0.0
(0)咨询产品免费试用果果科技
- 0.0
(0)咨询产品免费试用壹伴群发大师
- 0.0
(0)咨询产品免费试用优蓝招聘
- 3.4
(7)咨询产品免费试用活力职
- 3.9
(12)咨询产品免费试用







