4 bit时代或将来临: 手机也能跑大型神经网络了?
编者按:本文来自微信公众号“将门创投”(ID:thejiangmen),作者:让创新获得认可,36氪经授权发布。
From: Technology Review;编译: Shelly
在不久的将来,大规模的神经网络就能以更快的速度和更少的耗能在智能手机上进行训练了——“8位比特是一个字节,因此4位称为半字节(nibble)”,这是来自计算机工程师们独有的幽默。现在,IBM研究人员提出了一种可能,他们希望将表示数据所需的位数(即1和0)从目前的行业标准16位减少到只有4位。
深度学习是一种低效的耗能无底洞。它需要大量的数据和海量的计算资源支持,这导致电力消耗的爆炸式增长。在过去的几年里,整体的研究趋势使这个问题更加严重。深度学习会用几天的时间在数十亿数据点上训练,这种训练方式正在“文艺复兴”,并且短时间内不会改变。
一些研究者急于找到新的方向解决这一问题,比如,开发出能在更少数据上训练的算法,或是运行速度更快的硬件。不过,现在IBM的研究人员提出了另一种全新的想法!
他们的思路是,减少表示数据所需的比特数量,使其从目前行业标准的16位减少到4位。
这项工作已经在人工智能领域最大的年度研究会议NeurIPS上得到了展示,它可以提高深度学习训练的速度,并将所需的能源成本降低70%。在智能手机和其他小型设备上训练强大的人工智能也因此成为可能。同时,这项工作的实现也有助于个人将数据保存在本地设备上,改善隐私泄露问题,也将改变大型科技公司垄断数据这一行为。
字节是怎么工作的?
你以前可能听说过计算机用1和0来存储东西,这些基本单位被称为比特。当一个比特是“on”时,它对应的是1;当它是“off”时,它就对应0。换句话说,每个比特只能存储两条信息。
但一旦把它们串在一起,你可以编码的信息量就会呈指数增长。两个比特可以表示4条信息,因为有2^2的组合:00、01、10和11。4个比特可以代表2的4次方,也就是16条信息。8位可以表示2的8次方,也就是256等等。
正确的字节组合可以表示数据类型,如数字、字母和颜色;也可以表示操作类型,如加减和相似对比。现在的大多数笔记本电脑都是32位或64位,这不是说计算机只能编码2^32或2^64条信息(那将是一台非常弱的计算机!),而是指它可以使用这么高的复杂度来编码每一段数据或单个操作。
如果说频率的提升,是把一条4车道高速公路的限速从120公里提升到360公里的话,那么从32位到64位的提升,就是将这条提升了3倍时速限制的高速公路从4车道拓宽到了8车道。
4字节的深度学习
那么4字节的训练是什么意思呢?假设我们的计算机是4 bit的,那么它的复杂度就是4 bit。可以这样想:在训练过程中使用的每一个数字都必须是-8到7之间的16个整数中的一个(这是计算机唯一可以表示的数字)。这也适用于输入到神经网络中的数据点、用来代表神经网络的数字以及在训练过程中需要存储的中间数字。
当准备开始训练的时候,可以把训练数据想象成一堆黑白图像。第一步:把这些图像转换成数字,以便计算机理解它们。我们通过表示每个像素的灰度值来实现这一点,黑为0,白为1,之间的小数用灰阶表示。我们的图像现在是一个从0到1的数字列表。但在4 bit的环境中,我们需要它的范围是-8到7。这里的技巧是线性缩放数字列表,所以0变成-8,1变成7,小数映射到中间的整数。所以你可以将数字列表从0到1缩放到-8到7之间,然后将任何小数四舍五入为整数。
这个过程并不完美。如果你从0.3开始,缩放后的数为-3.5,但是因为4字节只能表示整数,所以又必须四舍五入到-4。你最终会在图像上失去一些灰色的阴影,或所谓的精度,即如图。
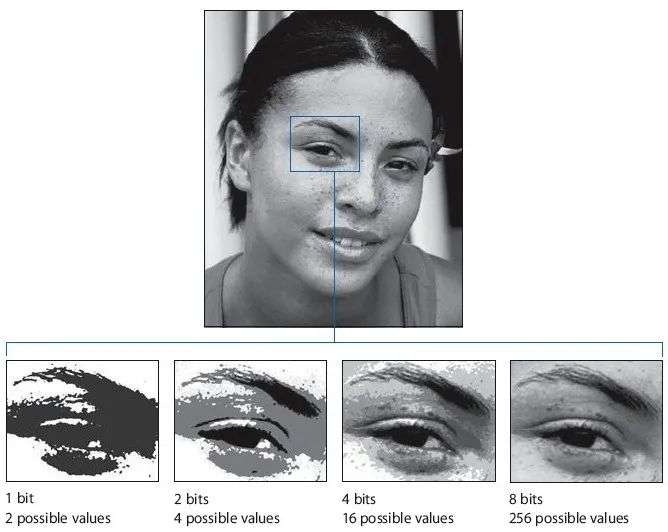
比特数越低,照片的细节就越少,即所谓的精度损失。
对于训练数据来说,这个技巧并不太差。但是当我们把它应用到神经网络本身时,事情就变得有些复杂了。
神经网络 A Neural Network
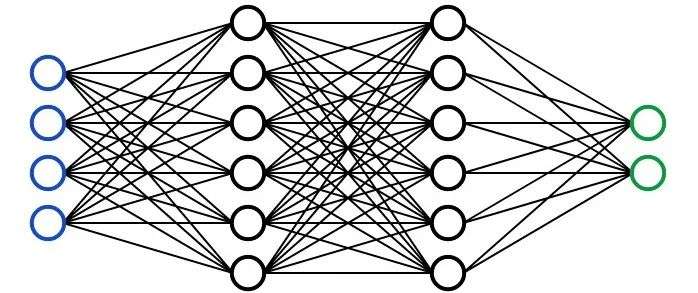
A neural network
我们经常看到神经网络被绘制成有节点和连接的东西,就像上面的图像。但是对电脑来说,这些最后会变成一系列数字。每个节点都有一个所谓的激活值,通常取值范围是0 ~ 1;每个连接都有一个权值,通常取值范围是-1 ~ 1。
我们可以用与像素相同的方式来缩放它们,但是激活和权重也会随着每一轮训练而改变,例如,有时激活范围是0.2到0.9,另一个回合的激活范围是0.1到0.7。因此,2018年IBM团队想出了一个新方法:重新定义范围缩放,每轮在-8到7之间(如下图所示),这有效地降低了精度损失。
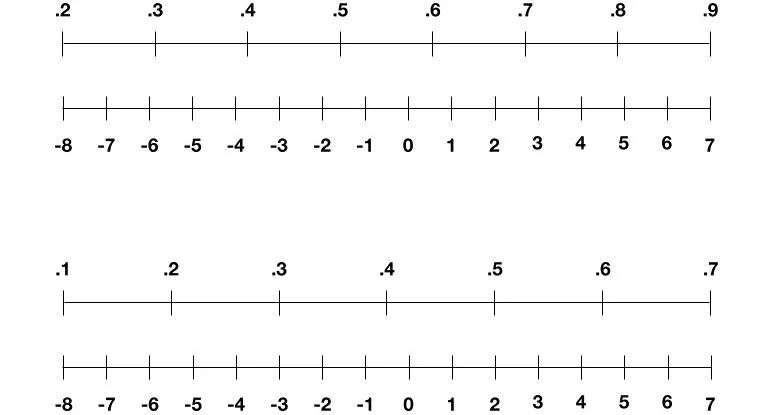
IBM的研究人员在每一轮训练中都重新衡量神经网络的激活和权重,以避免失去太多的精度。
但是仍然还剩下一个问题:如何用4 bit表示训练过程中突然出现的中间值?
与我们曾经处理过的图像、权重和激活函数不同,真正的挑战在于其数值横跨多个数量级,可能是微小的0.001,也可能是巨大1000。
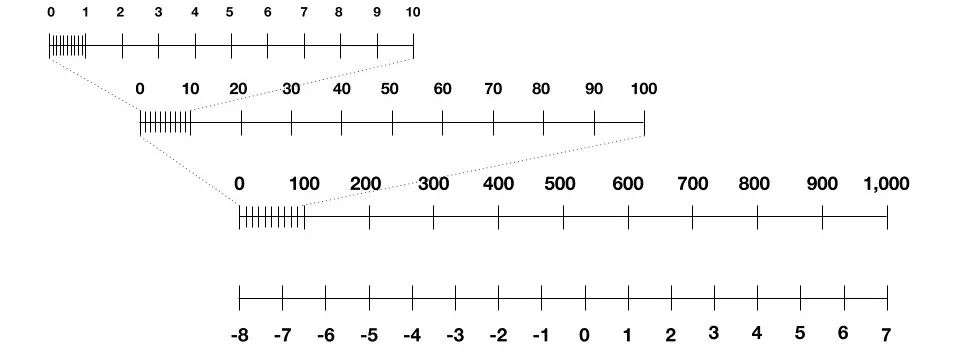
如果要在-8和7之间建立线性尺度,将会损失微小尺度末端的所有梯度。正如你在这里看到的,任何小于100的数都会被缩放到-8或-7。精度损失直接影响AI模型的最终呈现。
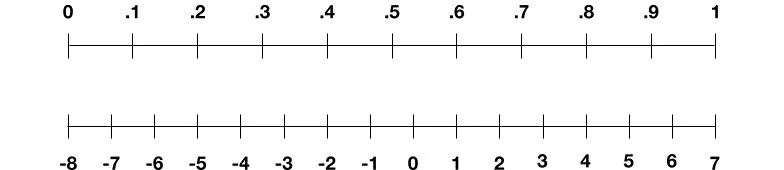
经过两年的研究,研究人员终于解开了这个谜题。在借鉴前人想法的基础上,他们将这些中间数字按对数进行了缩放。为了理解这个概念,下面是一个对数刻度,所谓的“基数”为10,复杂度是4字节 (研究人员后来转而使用4为基数,因为反复试验表明,这种方法效果最好),你可以看到它是如何在字节限制内编码大/小数字的。

10为基数的对数刻度
以上各种问题的解决方案就位后,IBM的研究人员进行了几项实验,在计算机视觉、语音和自然语言处理方面模拟各种深度学习模型的4 bit训练。结果表明,与16 bit深度学习相比,模型的整体性能有一定的精度损失,但损失已经很小了。并且,这个训练过程比以前快七倍、节能高出七倍。
4 bit的前景
上文只是模拟了这种训练的结果,在4 bit深度学习真正落地实践前,还有几个步骤,比如,需要新的4 bit硬件设施。2019年,IBM研发中心启动了一个人工智能硬件中心,以加快开发和生产这类设备。负责监督这项工作的IBM研究员、高级经理Kailash Gopalakrishnan表示,他预计在三到四年内就会有适合训练深度学习的4 bit硬件诞生。
ref:
https://www.technologyreview.com/2020/12/11/1014102/ai-trains-on-4-bit-computers/


新锐产品推荐
Caicloud Cabernet
- 0.0
(0)咨询产品免费试用CaicloudCompass
- 0.0
(0)咨询产品免费试用MeterSphere
- 0.0
(0)咨询产品免费试用KubeOperator
- 0.0
(0)咨询产品免费试用JumpServer
- 0.0
(0)咨询产品免费试用CloudExplorer
- 0.0
(0)咨询产品免费试用







