《翻译小史|如何假装能和全世界讨论世界杯》
2018年6月16俄罗斯足球世界杯,冰岛用“很吓人”的防守技术逼平阿根廷!
2018年6月17杭州语言服务世界杯,出现一种“很吓人”的技术,能够瞬间切换世界杯各个国家的语言,那速度那精准度,堪比场上的“C罗”!
近日在杭州举办的语言服务行业国际研讨会上,新译科技田亮博士分享了一种新的机器翻译技术——限定性神经网络技术,正好能满足世界杯那么多术语翻译需求。
如果能用这个神器,一边看球一边精准的用各国专业足球术语,在社交媒体上发言、吐槽、晒见识,你会不会瞬间成为朋友圈里的“C罗”?
要实现这样的拉风时刻,你需要这样一款智能翻译工具——新译科技的在线智能翻译。
你一定看过有些机械翻译的稿子,简直就不在“说人话”。莫名的译文、头痛的数字、关键术语的翻译错误,我们还能愉快地玩耍嘛?
翻译工具,要选对。
翻译是艺术和技术的完美结合。机器翻译从上世纪四十年代开始至今,经历了基于规则的、实例的、统计的和神经网络算法的几个过程。
今日,神经网络算法正处于不断完善过程中。它比起传统的统计机器翻译,译文质量有极大提高,不过,一旦涉及到术语等关键信息,译文往往是这样的:
今天我们吃了宫保鸡丁。它会翻译成:
Today we ate the palace chicken.
palace chicken是什么鬼?难道不应该是KungPao Chicken吗?
事实上,语言服务从业人员希望用更少的工程脑力,来实现最终的准确译文——
Today we had KungPao Chicken.
在翻译的过程中,包括口译和笔译,如果把一句话中的关键信息(主从关系、数字、日期、人名、地名、机构名、货币等)表达出来,就能基本达到沟通的目的。如果把原文中的关键词(算法工程师称其为:命名实体)替换成想要的准确译文,不就能实现准确翻译的目的吗
小编也从事翻译十几年,曾几何时也是这么想的,因为以前就这样做的。但是不知何时起,这种“聪明的”技巧,已经在主流机器翻译中不起作用了。
曾经,想翻译一句话,比如:
澳门皇冠假日酒店委托我来翻译这篇文章。
只需要把“澳门皇冠假日酒店”替换成我准备的术语“Crowne Plaza Macau”,就大功告成,稍作修改就得到我想要的译文:
Crowne Plaza Macau委托我来翻译这篇文章。
Crowne Plaza Macau commissioned me to translate this article.
但是现在的结果是:
Crowne Plaza Macao commissioned me to translate this article.
系统“悄悄地”修改了译文,没有实现我指定的译文!!!!!
文科生小编把脑袋想爆炸了之后,终于明白,在传统基于短语的统计机器翻译等系统中,可以简单地把数字或者专有名词,原封不动复制到翻译句子中,但在神经网络机器翻译中,这样的操作无法有效进行。
要理解这些,小编带大伙先看看机器翻译的进程和简单的原理。
翻译进化小史,首先了解一下:
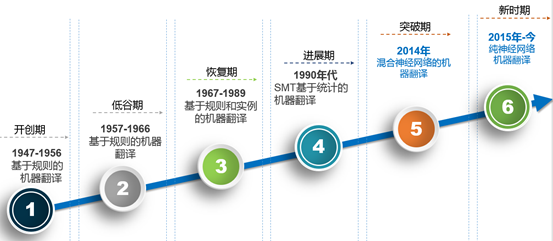
1.基于规则的机器翻译
真正的规则系统始于上世纪70年代。规则的原理很简单,最初就直观地认为,找很多语言学家,集中写一些语法规则,并辅助一些双语词典和转写规则就能实现精准翻译。
在一些特定的场景,如天气预报、时间预测等,规则系统在形态的准确性、结果的可复现性、针对特定领域进行调整的能力还是非常强的,但是要创造一个理想的基于规则的系统,就算让语言学家尽力穷尽一切拼写规则来增强它,也总会遇到例外。英语有不规则动词、德语有可分离前缀、俄语有不规则的后缀,在人们说话的时候又会有各自的特点,别忘了有些词根据上下文还会产生不同的意思。
2.基于实例的机器翻译
后来,基于语料库的方法走上舞台。1981年,日本的长尾真教授首先提出了这种思路:直接用已经准备好的短语,不用重复翻译。
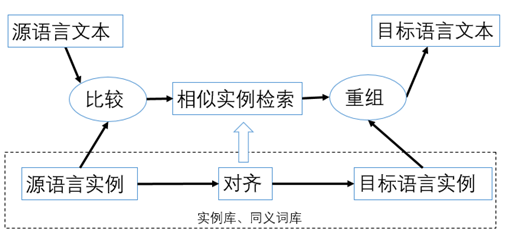
这种方法,在现有的平行语料库中找出与待翻译部分最相似的翻译实例,再对实例的译文通过替换、删除或者增加等系列操作,实现翻译。相似的例句越多,翻译的效果越好。

它的缺点是,系统性能依赖于语料库,数据稀疏问题严重,语料库中不容易活动大颗粒度的高概括性知识。
3.基于统计的机器翻译
上世纪90年代早期,IBM研究中心首次展示了对规则和语言学一无所知的机器翻译系统。
这种方法,将两种语言中同义的句子切分成词进行匹配,然后去计算某些片段会翻译成多少种可能,最后统计出来频率高的,就认为正确译文的可能性较大。
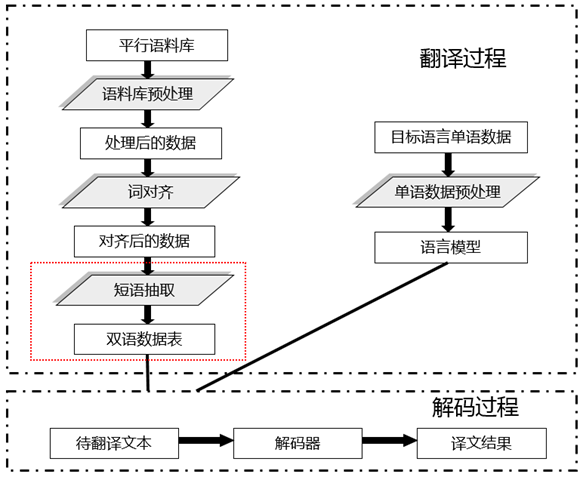
2006年,基于统计的机器翻译方法开始普及。Google翻译、Yandex、微软必应等在线翻译工具都用上了基于短语的机器翻译。直到2016年,它都被视为最先进的机器翻译方法。
我们给机器更多的文本,它就给我们更好的翻译。但是!!设定的各种特征值,以及需要N多种自然语言处理的技术(分词、词性标注、句法分析等),每一步的错误率,像滚雪球一样,将导致最终的结果有很大偏差。而且最大的问题是调序模型的不完善,覆盖不到全局特征,导致统计机器翻译一直阅读的流畅性不是很好。
4.基于神经网络的机器翻译
终于,当当当当!在2016年9月,Google宣布了一个颠覆性的进展。这就是神经机器翻译。
神经网络机器翻译(Neural Machine Translation, NMT)相比于传统的统计机器翻译(SMT)而言,能够训练一张可以从一个序列映射到另一个序列的神经网络,输出的可以是一个变长的序列,这在翻译、对话和文字概括方面能够获得非常好的表现。
这里就需要专业的人员设计并找出一些特征值,能够描述并转换成目标语言。
这个大神,简直有点像媒婆!想象媒婆在给A介绍对象B的场景,A(原文)虽然没有见过B(译文),但是只要媒婆能够大致的描述B的特征(包括身高、长相、身材、年龄等),A就能根据这些描述大致勾勒出这个目标恋人B(译文)的样子。
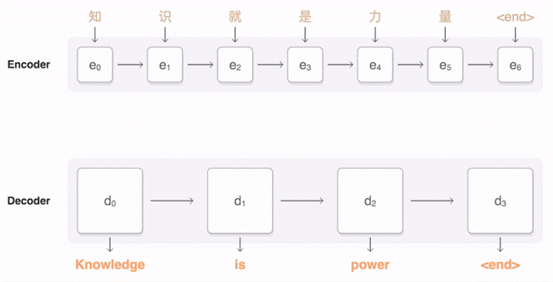
“神经网络”一出,谁与争锋。
两年来,神经网络超过了翻译界过去几十年的一切。神经翻译的单词错误减少了50%,词汇错误减少17%,语法错误减少19%。
但是!神经网络翻译机器,有时候会“发神经”!它有时候会出现漏译、过译、缺少语义信息等问题。
举几个?给大家感受一下——
句子:隋景懿今天来到了新译科技。
译文:Sui Jingyi came to New Translation Technology today. 问题:专有名词翻译不正确
句子:我不太喜欢吃宫保鸡丁,你可以帮我点一道鱼香茄子。
译文:I'm not too fond of eating Kung Pao chicken. You can help me with a fish eggplant.
问题:术语翻译错误
句子:2018年6月17日,中国翻译协会举办了翻译标准研讨会。
译文:June 18, 2018, the Chinese Translation Association held a seminar on translation standards.
问题:数字日期莫名出现错误数字
所以,想要它不“发神经”,必须给它一个限制,把它稳定住。“限定性神经网络”应运而生。
我们了解到,神经网络训练像个“黑盒子”,丢一个东西进去, 它会给你丢出来另一个东西,丢出和丢进的东西有某些联系。但黑盒里究竟发生了什么?由于不清楚这个黑盒子的运作原理,传统的干预手段,在神经网络机器翻译中效果不那么明显。
限定性神经网络的初衷就是通过干预输入的句子,然后让底层神经网络的模型参数进行调整,并准确无误的还原干预部分的译文表达。
不少国内外机构使用认识心理学解释深度神经网络这个黑盒子,而限定性神经网络,就是借助这类原理干预了底层。
限定性神经网络的初衷就是通过干预输入的句子,调整底层神经网络的模型参数,并准确无误的还原干预部分的译文表达。
就是确保这边窗户我丢一个?进去,那边窗户会乖乖地把这个?丢出来。
我限定了这个?不能轻易变动,比如你不能把它切碎了,或者直接搅拌一杯果汁出来,这些我都不收货!
这是神经网络机器翻译的一个重大突破!
再举个例子——
原文输入:
6月18日,也是端午节,众多翻译界的大咖们,乘坐着HA-9888的奔驰商务汽车来到了绿地中心新译科技,进行交流学习。如有任何问题,请发送至liangliang@newtranx.com进行询问或者登陆www.newtranx.com进行详细了解。
从机器翻译算法技术的角度,它们会根据限定性神经网络的逻辑,先分成需要翻译的部分和不需要翻译的部分。而这个过程是通过命名实体识别来实现的。加入自动识别后,输入的句子就进行了识别,模拟我们人工翻译的过程。
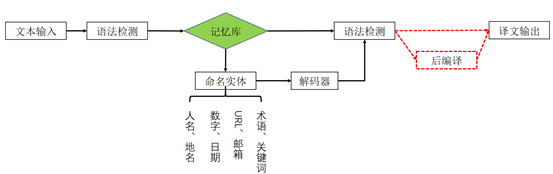

当前命名实体识别的准确率能够保证在90%以上的正确率,同时为了增加准确性,允许专业的人员导入其自定义术语库,提高个人的命名实体识别能力。
当把输入句子中的命名实体识别后,就需要调用各种模块把原文替换成准确的译文:
June 18th,也是Dragon Boat Festival ,众多Translation Community的大咖们:SMT,乘坐着HA-9888:UNK的Mercedes-Benz Business Car来到了Greenland Center NewTranx,进行交流学习。如有任何问题,请发送至liangliang@newtranx.com:UNK进行询问或者登陆www.newtranx.com:UNK进行详细了解。
当得到上一步的替换后,就可以进行相关的解码器翻译,最终准确无误地翻译出来!
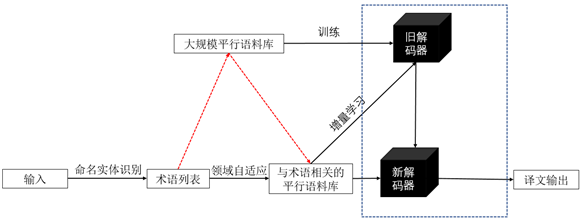
这是各种系统融合的大过程。
新译科技的翻译器,就是这样一个完美的翻译工具!
限定性神经网络翻译,让你?是?,?是?,种下一颗豆子,绝不会长出一个娃娃。
它通过干预输入的句子,调整底层神经网络的模型参数,并准确无误的还原干预部分的译文表达。限定性神经网络,让翻译不再发神经,而是变大神。
入夜方能赞美白昼。In the evening one may praise the day.熬夜看世界杯,借助新译科技翻译一下球评,再借助它假装吟两句似懂非懂的诗,今夜,在朋友圈中,你简直像c罗的帽子戏法一样闪耀。赶紧来体验一下吧,戳下面这个网址,直达新译在线智能翻译https://fanyi.newtranx.com/。


SEO搜索引擎优化相关的软件
Majestic
- 4.4
(40)咨询产品免费试用Semrush
- 4.2
(40)咨询产品免费试用百度统计
- 3.5
(34)咨询产品免费试用



行业专家共同推荐的软件
水滴互动B2B-SEO获客优化工具
- 4.0
(13)咨询产品免费试用企优托
- 4.5
(2)咨询产品免费试用曼朗-搜索引擎优化
- 4.0
(7)咨询产品免费试用



限时免费的SEO搜索引擎优化软件
Ahrefs
- 3.9
(40)咨询产品免费试用Similarweb
- 4.0
(40)咨询产品免费试用


新锐产品推荐
法大大
- 3.9
(319)咨询产品免费试用石墨文档
- 4.0
(89)咨询产品免费试用上直播
- 4.0
(95)咨询产品免费试用企业微信
- 3.9
(164)咨询产品免费试用悟空CRM
- 3.8
(134)咨询产品免费试用Udesk
- 4.2
(4)咨询产品免费试用







