Google说:少年,看你移动鼠标的手法,就知道你一定是机器人了

当阿兰·图灵在1947年第一次构想图灵测试的时候,他提出了一个很重要的点:有着和人类智能相近的计算程序,通过回答一系列问题,可以被区分究竟是程序还是人类。在大约70年之后,Google宣布他们把这种图灵测试做到了最简单粗暴的层次:通过鼠标的一次单击就可以下判断。
目前区分计算程序和人类最广泛的应用在于网站的登陆注册验证。CAPTCHA验证系统已经被大范围使用了,但是显然这种方式很烦:他要求用户输入扭曲的文本或数字,以防止被软件恶意登陆注册。CAPTCHA另一个严重的缺陷在于,已经有很多黑客可以破解这种方法了。
于是人们开始引入图像,用图像匹配的方式作为验证方法:比如给定一张猫的图片,要你在一排动物图片里选出相近的一张。这对计算程序来说很难,因此可以用来区分恶意软件。
不过这种方式还不够极简。
Google拍了拍脑门,最方便轻松的方式,不就是动下鼠标单击吗。
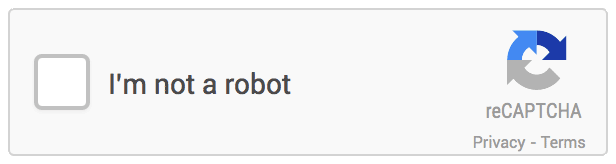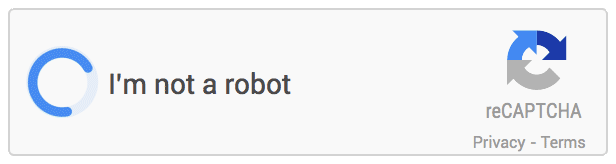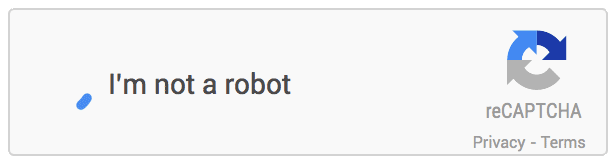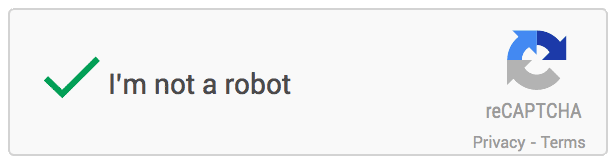
如图所示,只要移动鼠标,单击“我不是机器人”旁边的复选框打钩,系统就可以判断你是机器还是正常用户。如果判断结果显示非人类,系统会再利用此前图像匹配的方法进一步进行测试。这一验证系统被Google称作NoCAPTCHA reCAPTCHA。
那reCAPTCHA是如何做到这一点的?
reCAPTCHA其实在不知不觉中利用了用户提供的IP地址和cookies。通过IP和cookies,Google可以判断当前用户是不是以前曾经在web上被“记住过的熟悉的人”,此外,鼠标向复选框靠近时移动的行为和姿态也是一个非常细微的判断线索。
人类行为(Human behavior)包含着很多有价值的信息,数字环境下的人类行为更是如此。Google表示,他们还通过其他许多线索做判断,以便更好的秘密的拦截更多的机器软件——不过公开这些方法会让僵尸主控机不断学习和改进恶意攻击,对于验证系统很不利。
目前,Snapchat、WordPress 和Humble Bundle等网站正在测试 Google 的新版CAPTCHA。Google称 WordPress 60% 的流量和 Humble Bundle 80% 的流量都通过了reCAPTCHA直接被判断为人类,极大的提升了用户体验。
对于智能手机和平板的移动端,Google暂时还是沿用着图像匹配的验证方法。
Google其实很早就开始做这方面的研究了:在很多按点击量付费的网站广告,为了防止机器的恶意点击,很早就需要类似的防欺诈方法。而据说这种全自动区分计算和人类的检测方法至少在2013年就开始被集成进入CAPTCHA验证系统里了。今年情人节的时候,Google则推出了一项测试实验,向用户展示简单清晰的单词如“love”、“Flowers”等,系统可以判断是否有恶意程序通过图像识别技术获取了字体内容,从而拦截机器用户。
在我们赞叹科技越来越神奇的时候,或许也有些人在角落里默默担忧:Google会不会(或者已经)知道得太多了?用户在网上蛛丝马迹的动作行为,Google好像可以轻易的组合起来,还原出一个人真实的全貌。
不过Google表示,在其他网站上出现reCAPTCHA验证对话框时,Google只能在对话框范围里记录跟踪用户鼠标的移动行为,而不是整个网页范围。


SEO搜索引擎优化相关的软件
Majestic
- 4.4
(40)咨询产品免费试用Semrush
- 4.2
(40)咨询产品免费试用百度统计
- 3.5
(34)咨询产品免费试用



行业专家共同推荐的软件
水滴互动B2B-SEO获客优化工具
- 4.0
(13)咨询产品免费试用企优托
- 4.5
(2)咨询产品免费试用曼朗-搜索引擎优化
- 4.0
(7)咨询产品免费试用



限时免费的SEO搜索引擎优化软件
Ahrefs
- 3.9
(40)咨询产品免费试用Similarweb
- 4.0
(40)咨询产品免费试用


新锐产品推荐
紫日SCRM
- 0.0
(0)咨询产品免费试用金蝶管易云C-ERP
- 0.0
(0)咨询产品免费试用欣欣ERP
- 0.0
(0)咨询产品免费试用小叮当ERP
- 0.0
(0)咨询产品免费试用印智互联-商务印刷ERP
- 0.0
(0)咨询产品免费试用统率制造业ERP
- 0.0
(0)咨询产品免费试用







