汽车维保反欺诈系统的设计和算法应用
编者按:本文作者 赵昕、杨明锋、毛耀鋆,Delta Entropy Technology 七炅信息科技;36氪经授权发布。
背景
作为全球最大的汽车市场,中国在经历了多年的两位数增长以后,已经回落到个位数增长的“新常态”。随着汽车保有量的不断增加,以及汽车使用年限的增加,中国汽车售后市场(含配件、维保和增值服务)在整个汽车行业里的地位越发重要。汽车厂商、经销商和服务商等主体的关注点,也从新车销售逐渐转向汽车后市场。而随着行业竞争的加大,消费者理性消费意识增强,汽车后市场主体的利润空间不断受到挤压,全国4S店的经营状况愈发恶化,亏损面不断加大。
根据美国权威汽车维保专刊Warranty Week的统计,汽车厂商总收入中的1%-4%(平均2%左右)将作为保修相关的费用支付给经销商和服务商。这部分费用中的15-20%为欺诈案件,而中国的汽车厂商遭受的欺诈案件金额比例可能高达34%。美国市场上,每年维保相关的欺诈造成主机厂的损失超过30亿美金。这就意味着,对于中国市场主体成熟的损失不低于300亿人民币,每一家市场份额较高的畅销品牌汽车厂商,在这类欺诈维保支付上损失的金额都不低于10亿元/年。
本文将介绍维保反欺诈系统的基本设计思路和几种有效的反欺诈检测算法引擎,除了聚类分析等经典算法外,还包括了笔者所供职的Delta Entropy开发使用的新型机器学习算法,从而帮助汽车厂商大幅度降低维保成本。维保反欺诈系统除了能带来的巨大直接经济利益外,通过排除欺诈性案件,还可以更加准确地检测质量和配件问题,使预警系统更加精确地监控到索赔率的重大变化,从而使主机厂的产品工程师能够更好地了解故障模式以及驱动因素,从而提高产品质量、降低召回率、提高客户满意度。
传统的维保反欺诈方法
欺诈检测方法大致分为以下几种:
人工卷宗审核:顾名思义,很多公司都通过一定的标准(例如金额或者频率特别高)对高风险赔案进行人工卷宗审核,优点是这种方式对找到欺诈案件非常有效,但所需资源投入过大,专业人才较为缺乏不适用于普遍应用,而且由于人工审核的限制,经常会错过模式性欺诈
基于规则的系统识别:在系统中部署已定的规则,将触犯规则的案件推送到人工审核。这种方式比直接的人工审核更为普遍常见,可以有效查找已知的欺诈类型。但无法针对新的欺诈案件自动更新,而且非常容易被欺诈者得知后迅速失效
替换零件回收确认:将替换下的零配件进行回收确认,用以减少虚假的零配件索赔,这种方式对零件类的索赔会有一定的效果,但是成本高昂,不适合大范围应用
人工实地审核:非常有效,但难以预先得知聚焦的服务商或案件,应该采用什么作为人工审核的标准更加有效难以判断
高级数据分析方法:可以利用数据分析和机器学习的方法,针对欺诈的可能性高低对每个索赔和服务提供商进行精准评分,从而帮助合理分配卷宗审核员和现场审核员的工作重点。随着时间的推移,机器学习算法可以从服务提供商和审核人员的行为中学习获得越来越多的欺诈判断标识使得判断愈加精准。机器学习获取的结论还可以通过规则引擎得到迅速应用
针对维保中可能出现的欺诈行为,大多数制造商都有类似下图的业务规则审核机制,即使如此,它们并不能有效阻止大部分的索赔欺诈。在这个规则为主体的流程中,维保的服务提供商经常可以通过询问“为什么某某案件没有支付”从而获取简单规则的细节,从而在下次索赔中选择避开该规则的限制。因此为了有效地从根本上解决维保索赔欺诈,厂商需要一种普遍适用性高、支持多维度数据分析、并且可以不断自动学习更新的反欺诈机制。

高效的反欺诈机制
高效的反欺诈机制应该是一种综合的方案,针对不同类型的欺诈行为均能体现出效果。这种混合方案可以针对每个索赔案件、服务提供商都以标识符的形式进行欺诈可能性的判断,并提供标记原因,帮助人工审核人员更加专注于高风险案件,从而根本上提供欺诈案件的识别率,并且降低欺诈案件的产生率。 除了能够直接兼容对接现有系统以外,这种反欺诈引擎需要具有至少三方面的综合作用:
基于规则的引擎:针对已知欺诈模式或者操作失误的规则,例如超过允许收费工时数,无效的代码或零件、同一个维修多次申请理赔等
对异常现象的检测:针对未知但异常的欺诈,例如里程或者工时、零件数量明显超过正常范围
实时自动欺诈预警:使用先进的机器学习技术对于索赔中的索赔类型或零部件组合中不寻常的模式进行定位、对于和客户的维修保养原因不匹配的索赔或者零件组合进行预警、对于某服务提供商或技术人员的索赔模式与其他服务提供商和技术人员相比明显差异等方面给出迅速综合的判断
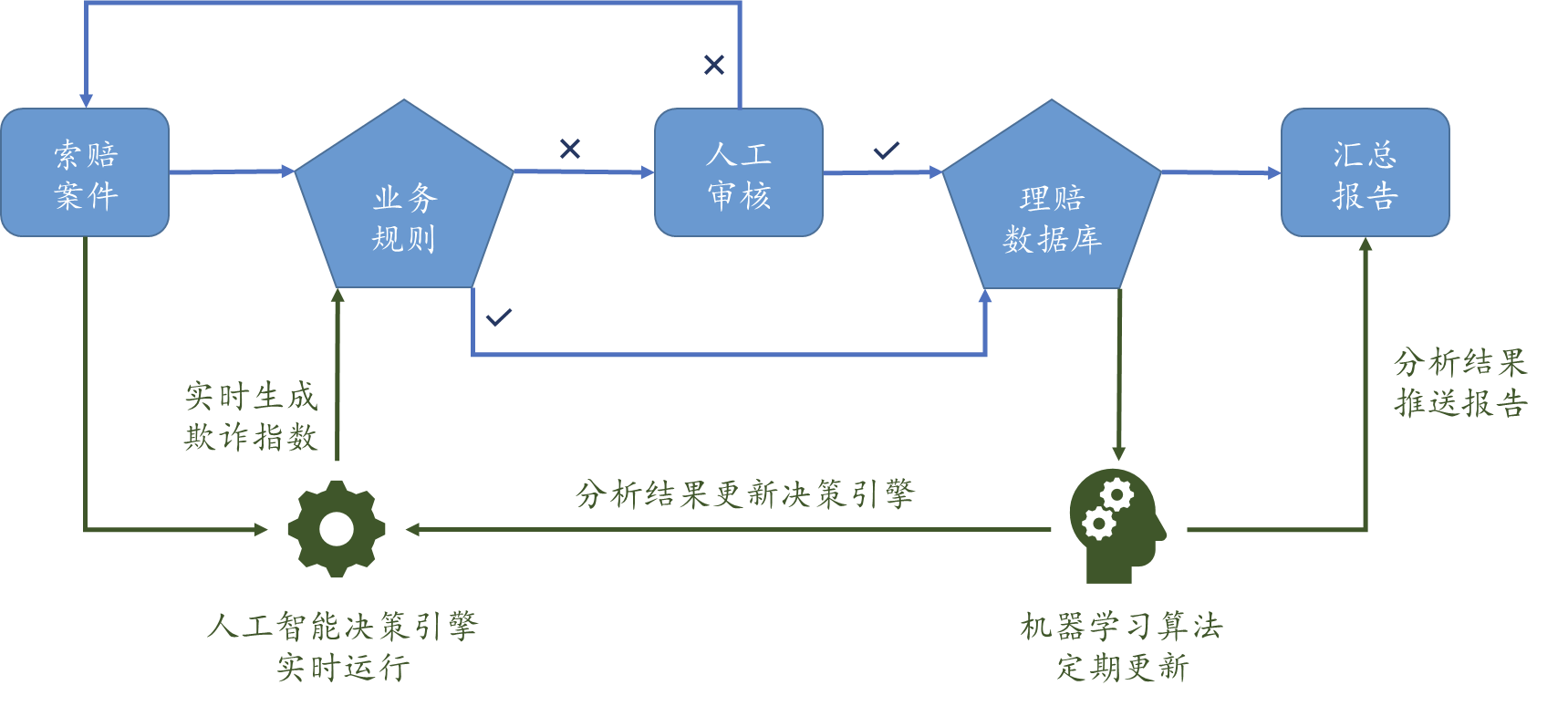
机器学习的反欺诈算法
鉴于目前国内大多数公司的反欺诈系统应用仍处在初级阶段,缺乏大量的人工验证过的欺诈案例,因此无法满足监督学习(Supervised)算法对基础数据的要求,暂时不适合于普遍应用,因此,本文将着重说明无监督学习(Unsupervised)算法。
汽车厂商的维保管理部门大多会采用标准的零配件和工时费标准,对各类维修赋予固定的工时和零配件价格,甚至采用系统赋值的方式。因此在一般情况下,每次索赔的“金额”一般欺诈的空间较小,而各类维修、零配件的“频率”是反欺诈算法的重点。以下算法旨在关注维保索赔中是否存在异常、欺诈现象,而非针对某个零部件相关的理赔金额判断其是否合理。
这些方法在单独使用时,不能解决所有的欺诈识别需求,实务中会结合多种方法共同使用。例如先按照业务需求将业务数据按照车型、里程、地区、发生时间等维度进行拆分,再使用汇总分析、决策树、聚类分析等方式建立有效的指标监控体系,最后使用机器学习等高级定量分析方法进行实时的预警和科学决策。
异常检测算法 – Benford定律
Benford定律的数据分析遵循一个基本假设:许多现实生活来源的数字列表都是以一种特定的不均匀的方式分布的,大约30%的概率数字1会出现,数字2发生的概率会低于数字1,随后3,4,一直到9,数字9发生的概率低于5%。通过应用Benford定律,可以快速发现人为编造数字的痕迹,从而帮助审查人员缩小调查范围和准确定位调查目标。这种方法适用于欺诈调查的初始阶段,而且易于实现,不需要复杂的算法逻辑。
Benford 算法和一般的统计汇总分析类似,可以在不知从何处入手时,作为初始分析的切入点进行使用,在此不做赘述,下文会着重分享可以系统化自动部署实现的三种算法。
自动算法1:聚类算法 – K Means Clustering
聚类算法通过将数据点分组和聚合成为类似的集群,然后在每个集群内寻找在某种意义上与集群内的其他数据项不同的数据项,从而检测异常数据。这种算法极为适合从非常大的数据集中识别异常数据,例如,识别潜在的欺诈性信用卡交易、潜在欺诈理赔案件、欺诈性风险贷款申请等。在所有的聚类算法中,最广泛使用的算法之一是K Means算法。
K Means 算法通过采用均值算法将数据集分成K个组(组内数据相似,而组间是有差异的),算法流程一般为:
从数据中抽取K个点作为聚类的中心
计算数据中所有的点到这K个点的距离,并将这个点归类到与其最近的聚类里
重新调整聚类中心到每个聚类的几何中心(Euclidean Mean)
重复进行步骤2和3 直到聚类的中心不再移动 - 模型收敛完成

为了防止初始聚类中心的选择导致的局部收敛现象,可以采用二分均值算法,通过将全体数据重复进行二分法,选择SSE(Sum of Squared Errors)最小的拆分方式添加聚类分组。
聚类算法的落地应用
每一个数据点与其所在的集群聚类中心的距离越远,意味着其越偏离常规,属于异常的可能性越高。在业务应用中,需要考虑两种应用方式:
若汽车厂商使用反欺诈算法对历史赔案进行离线分析,并且采用人工审核和事后追偿的落地方式,则需要考虑对分析结果进行人工干预和审核的便利性以及历史赔款“追回”的价值。因此需要将所有的异常值判断从“赔案”、“4S店/服务商”、“维修技术人员”等多个维度进行加权,并根据理赔金额的高低进行优先级排序后进行汇总,然后建立相应的审核机制。
若汽车厂商采用的是实时的方式对每个赔案进行打分,并根据分数的高低制定自动规则、系统预警后再进行人工审核的落地方式,则需要在实施应用时建立模型的更新机制,遵循一定的更新频率,从而保证新的欺诈案件和模式能够通过模型的自动学习不断被模型识别。
自动算法2:关联性分析 – Association Rules
关联性分析中最广为流传的一个应用就是沃尔玛的“尿布和啤酒”案例。关联性分析除了在零售行业的客户偏好方面的应用之外,也可以直接应用于维保领域的反欺诈分析。每一次维修中涉及到的零配件的类别和数量与每一次维修的特征相关,因此可以根据每一次维修中涉及到的零配件之间共同出现的情况,对某一个索赔维修中是否有不常见的组合进行识别。这种方法和其他的反欺诈算法一样,需要作为很多工具中的一个,用于定位识别欺诈案件。
例如:一般在维修中,通过关联性分析可以发现,排气歧管、密封圈垫一般是成对同时出现的;而喇叭的维修一般不会和排气歧管、密封圈垫的更换发生在同一个维修中。通过关联性分析规则,可以将排气歧管、密封圈垫和汽车喇叭的维修发生在同一次维修的索赔进行标注。这种现象本身不一定说明这个索赔一定是欺诈,但是如果通过汇总分析,同时发现这个服务商的汽车喇叭维修次数明显高于其他服务商的平均水平,则可以对这个服务商的喇叭维修进行关注和审核了。
自动算法3:实时欺诈预警算法 – Delta Detection
笔者所在的公司的维保反欺诈系统Delta Detection是七炅科技自主开发的维保反欺诈系统,其核心算法基于大数据分析挖掘海量索赔单中不同理赔科目(零部件、工时、索赔类型等)之间的隐含关系,并以此推导出各个索赔科目的存在合理性。该算法曾在美国大数据算法大赛中获得最佳效果。在医疗保险和汽车保险反欺诈领域的得到了广泛应用。其算法流程如下:
分析并汇总每一条索赔记录中的零配件维修代码,结合时间、车型、服务商4S店特征等信息,将每一条报销索赔记录转换成一个高维向量
对于新的报销索赔记录,利用稀疏矩阵填充算法,对已申请索赔的每一个项目进行评估打分
如果一个项目得分很低,则该项目有可能是异常维保索赔项目。得分越低,则欺诈可能性越高
将得分低的项目对应的欺诈可能性指数与该项所对应的金额相乘,加权后根据业务应用的需要,在每个赔案(或者服务商在某个时间段的所有赔案)层面汇总。
根据业务需要和应用目的,同时考虑误判率高低的影响,制定出欺诈标识对应的标准和规则,然后将判断为欺诈的赔案(或者服务商)进行系统推送和预警
通过真实保险数据的验证,该算法对于欺诈案件的识别成功率极高,而且普遍应用与医疗保险、汽车维修保养欺诈、汽车保险欺诈等领域。
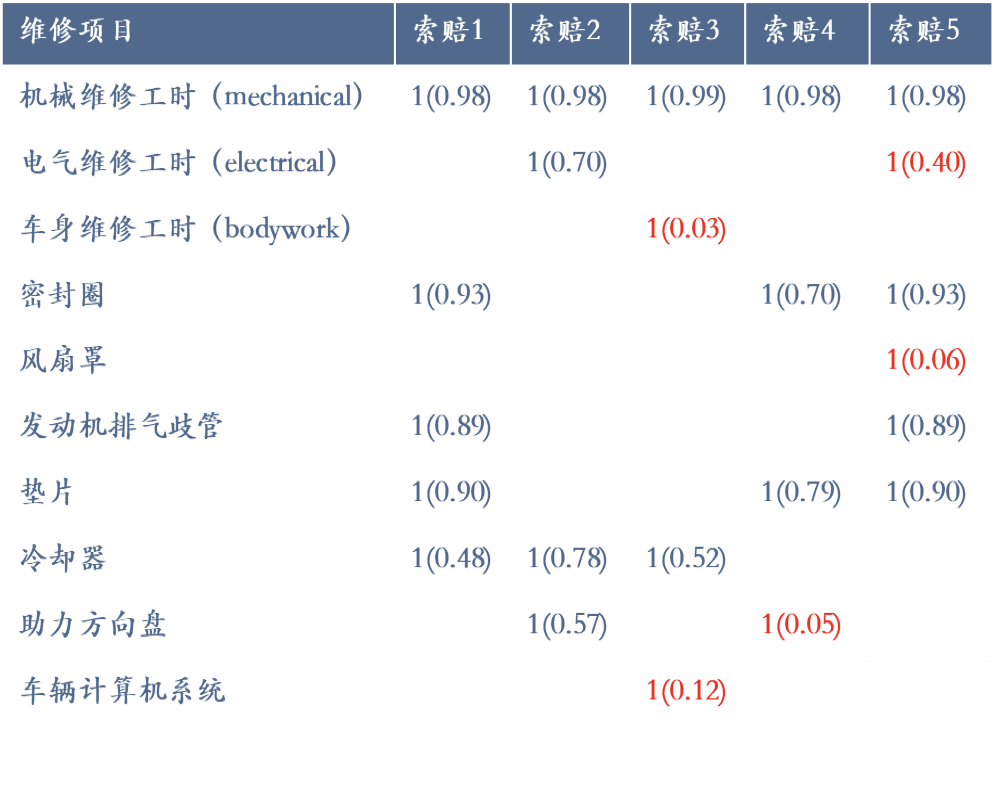
Delta Detection应用实例 :汽车维保反欺诈
操作流程:
根据车型、里程、地区将维修记录进行分组(分组决策可以参考决策树分组等变量重要性筛选工具的结果),然后对每一组数据进行独立分析
汇总分析每一条维修报销理赔记录,结合故障代码和维修项目细节与工时类别,将每一条申报记录(零件个数和工时数)转换成一个高维向量
利用Delta Detection算法和维修项目的内在关系,计算各项指标的出现概率,概率越低,表示欺诈的可能性越大。下面表格中,“汽车信息计算机”、“助力方向盘”等项目计算的概率得分较低,因此欺诈可能性较高
生成欺诈概率指数(1-概率),并将每项零件工时对应的金额和欺诈概率指数进行加权汇总,在服务商、维修员工、录单员等维度进行汇总
汇总后排位较高的索赔案件、服务商、维修员工、录单员成为风险管理部门关注的目标
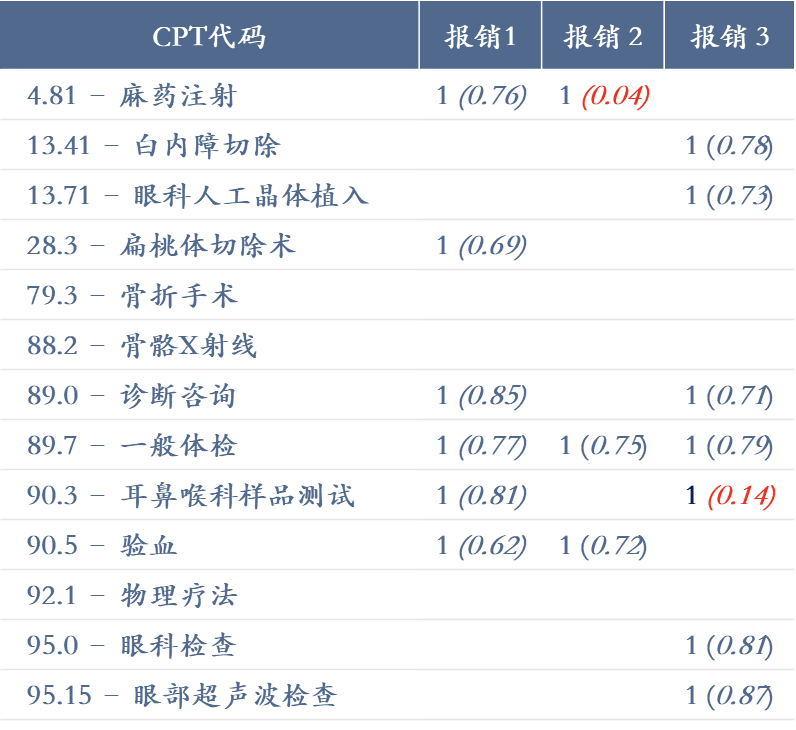
Delta Detection应用实例:医疗过度收费/欺诈报销
操作流程:
分析并汇总每一条医疗账单记录中的ICD和CPT代码,结合时间、地点、患者的个人背景信息和病史,将每一条报销记录转换成一个高维向量
对于新的报销记录,利用Delta Detection稀疏矩阵填充算法,对已报销的每一个项目进行评估打分
如果一个报销项目的得分很低,则该项目有可能是过度治疗/过度报销的收费
右图中,报销2中“麻药注射”只有0.04的得分,因此很可能是一个过度治疗/过度报销的项目
生成欺诈概率指数(1-概率),并将每项代码对应的金额和欺诈概率指数进行加权汇总,在医院、诊所、医生的维度进行汇总
汇总后排位较高的报销、医院、诊所、医生成为风险管理部门关注的目标
需要特别提醒的是:计算出的概率较低的项目,不代表这个一定就是欺诈案件,只是代表这个组合发生在现实中的可能性较低而已。因此为了避免模型结果过度敏感(avoid false alarm),就需要根据业务需要,对汇总后的结果进行排序,本着“抓大放小”的原则逐步推进反欺诈的系统。根据我们在类似项目中的经验,初次实施时,欺诈的先验概率为8%-10%时,准确性概率一般为95%-89%左右。
总结
随着机器学习技术的广泛应用,部署和实施维保反欺诈相关的检测系统和算法的成本逐年降低。这些算法经过了发达市场广泛应用,已经完全成熟。我国的汽车生产商可以通过逐步采用这些算法,每年节约超过百亿人民币的不必要支出。
关于作者:
赵昕,Delta Entropy Technology 七炅科技创始合伙人。曾在四大担任咨询总监,并具有多年的数据分析经验。长期专注于数据分析解决方案,聚焦金融保险和汽车行业。联系邮箱:zhaox@deltaentropy.com
杨明锋,Delta Entropy Technology 七炅科技创始合伙人。创立Delta Entropy前是美国德勤咨询(Deloitte)和毕马威(KPMG)大数据部门的技术负责人,为诸多世界五百强企业和美国政府机构提供基于大数据和人工智能技术的解决方案。联系邮箱:mfyang@deltaentropy.com
毛耀鋆,Delta Entropy Technology 七炅科技高级经理,曾任德勤上海精算及保险咨询团队咨询顾问,上海财经大学金融保险统计学士。联系邮箱:maoyj@deltaentropy.com
参考资料
[1] R.J. Bolton and D.J. Hand, “Unsupervised profiling methods for fraud detection”, Department of Mathematics Imperial College London {r.bolton,d.j.hand}@ic.ac.uk
[2] A.Dharmarajan, T. Velmurugan, “Applications of partition based clustering algorithms: A survey”, IEEE International Conference on Computational Intelligence and Computing Research 2013.
[3] Data Mining Techniques in Fraud Detection Rekha Bhowmik University of Texas at Dallas
rekha.bhowmik@utdallas.edu
[4] S. H.Gene “expression data knowledge discovery using global and local clustering”, Journal of computing, volume 2, issue 3, march 2010.
[5] www.warrantyweek.com
[6] S. Esakkiraj and S. Chidambaram, “A predictive approach for fraud detection using hidden markov model”International Journal of Engineering Research & Technology (IJERT) Vol. 2 Issue 1, January- 2013 C.
[7] V.S. Sunderam, G.D. Albada and P.M.A. Sloot,“Computational Science ICCS 2005”.
[8] Celebi, Kingravi and Vela, “A comparative study of efficient initialization methods for the K-Means clustering algorithm”, Expert systems with applications,40(1): 200–210, 2013.
[9] Xiuchang and Wei, “An improved K-means clustering algorithm”, Journal of networks, Vol. 9, No. 1, January,2014.
本文题图来自Yestone



数据分析相关的软件
永洪BI
- 4.3
(51)咨询产品免费试用帆软FineBI
- 4.2
(112)咨询产品免费试用观远数据
- 4.0
(30)咨询产品免费试用



行业专家共同推荐的软件
Wyn Enterprise
- 4.2
(49)咨询产品免费试用微软 Power BI
- 3.8
(53)咨询产品免费试用DigiPrime
- 4.7
(36)咨询产品免费试用



限时免费的数据分析软件
亿信ABI
- 3.9
(23)咨询产品免费试用派可数据
- 4.4
(31)咨询产品免费试用云眼
- 5.0
(1)咨询产品免费试用



最新文章推荐
新锐产品推荐
法大大
- 3.9
(319)咨询产品免费试用石墨文档
- 4.0
(89)咨询产品免费试用Teambition
- 3.7
(90)咨询产品免费试用有赞
- 3.9
(163)咨询产品免费试用微盟微商城
- 3.8
(36)咨询产品免费试用闪闪
- 0.0
(0)咨询产品免费试用







