反欺诈:一个“找不同”的游戏
编者按:本文作者 赵昕、杨明锋、毛耀鋆,Delta Entropy Technology 七炅信息科技;36氪经授权发布。
从信用卡、医疗费用报销到汽车维保的反欺诈应用
前言
笔者的“汽车维保反欺诈系统的设计和算法应用”一文,收到了算法和建模届同行的许多很有帮助的技术反馈和探讨沟通,也收到了很多诸如“感觉很专业”、“很深奥”的反馈。爱因斯坦曾经说过:“如果不能简单说清楚,那就是你自己还没有完全明白”,笔者痛定思痛,决定将算法的应用方式用更加直观的方式进行描述,期待能够将机器学习的反欺诈应用和更多的朋友分享。欢迎汽车领域的朋友提供反馈和改进建议,共同推进大数据算法在行业中的实际应用。
与人工卷宗审核的效果类似,机器学习算法也只能对“欺诈嫌疑较高”的案件进行标注和预警,而在进行现场实地查勘之前,都无法保证100%的准确率。根据笔者的经验,汽车维修保养和医疗报销领域的欺诈现象,其发生概率大多高于10%。如果将机器学习算法的预警概率制定在10%左右,也就是对大约十分之一的案件进行欺诈预警标注,其标注的案件为欺诈的准确率大约在89%-95%之间。在业务实际应用中,如果对预警准确率要求较高,则可以适当将预警标准提高到只针对十五分之一或者二十分之一的案件进行标注,则其准确率则可达96%-98%以上。当然这些准确率是针对单一案件而言,汇总后标注的高度嫌疑的服务商,准确率可以接近100%。
本文将采用三个不同的案例,采用从人脑学习到机器学习的过程来说明反欺诈算法的应用和实现方式。
人脑学习开始——信用卡
欺诈行为,无论是信用卡欺诈、医疗费用欺诈,还是汽车维修保养的欺诈,都是隐藏在大量的正常行为和数据记录中的少数“不正常”的行为。而反欺诈算法,归根结底就是一个“找异常”的游戏。我们先从一个41岁的女性消费者王女士的信用卡在一周内的消费记录开始寻找“异常”:
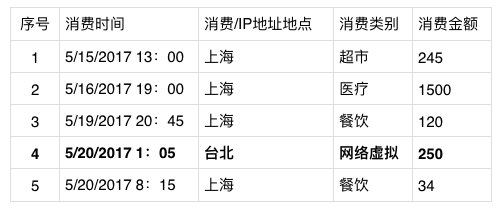
对于并非专门从事信用卡反欺诈的读者,也很容易运用“常规逻辑”看出:王女士的消费行为大多集中在上海地区,而其在5/20日于台湾IP地址进行的网络付费存在一定的异常可能。除了消费地点和消费类别稍显异常以外,消费时间与其他消费的关系(在上海发生两次日常消费之间,在台湾发生一次网络虚拟支出),也是本次消费表现异常,并极有可能为盗刷的一个原因。
但是,如果信用卡公司想针对信用卡盗用行为进行管控,并制定一些规则防止盗刷行为的发生,则无论是消费地点(台湾)还是消费类别(网络游戏),甚至是消费时间(凌晨),都无法单独作为一个标准规则,用于直接用于判断一次消费是否有欺诈嫌疑。因为对于很多其他的消费者来说,深夜发生于台湾的网络游戏支出,就不一定是盗用欺诈行为,如果设置了“屏蔽深夜期间于台湾发生的网络游戏支出”这一规则,则会给许多消费者带来不必要的麻烦。
因此可以看出,判断一次消费是否为欺诈的标准,是与该账户所属人的消费特点直接相关,并非简单的规则类限制可以准确描述。而且当消费者人数和次数数量较大时,人工审核判断的方式就无法满足信用卡消费反欺诈的时效性需要,这种情形下,人工智能和机器学习的算法就可以被用于高效自动筛选大量的消费记录,防止欺诈和盗用行为的发生。
人脑学习到机器学习的转化——医疗支出
除了账户的个人特征和历史行为所产生的异常判断标准以外,机器学习算法也会利用所有数据中那些大多数“正常” 的记录中所展示出来的内在关系(正常现象),来帮助判断某一个记录是否存在异常可能。以医疗费用支出 (医疗保险费用审核中经常发生的现象)为例,医疗反欺诈专员可以借助其医疗领域的丰富专业知识来快速判断某个报销是否存在欺诈可能性,但从大量数据的处理和应用的角度,需要一个自动化的机器学习算法来自动进行判断。
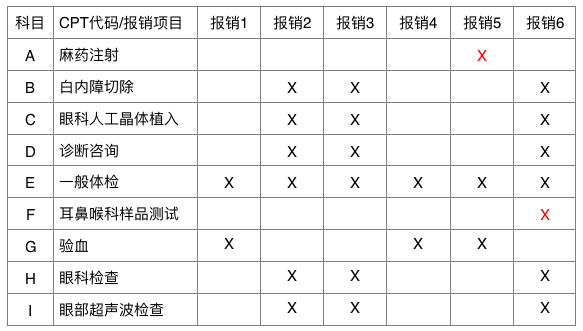
通过收集以往报销中的记录,可以看出,一般体检会经常伴随着验血这一项目出现,所以报销1和报销4可被视为较正常的报销记录,而报销5中所标注的麻药注射这一项则较为可疑。显然在常规情况下,伴随着一般体检所需要麻药注射的可能性是很低的。类似可以得出,报销2和报销3所代表的白内障切除手术,普遍会伴随眼科检查和一般体检等报销科目,而报销6中所记录的“耳鼻喉样品测试” 则是可能是较为异常的一项收费。
汽车维修保养行业是除了信用卡消费、医疗报销之外的另一个欺诈行为较为常见的领域。
根据美国权威汽车维保专刊Warranty Week统计,汽车厂商总收入中的1%-4%(平均2%左右)将作为保修相关的费用支付给经销商和服务商。这部分费用中的15-20%为欺诈费用,而中国的汽车厂商遭受的欺诈案件金额比例可能高达34%。保守估计,主机厂每年因此而承受的损失不低于300亿人民币,而每一家市场份额较高的畅销品牌汽车厂商,在这类欺诈支付上的损失可能超过10亿元/年。
机器学习算法可以通过一系列的汇总、预测和分析算法,将高欺诈嫌疑的案件进行最准确定位和标注。因为不同的车辆类型易损部位存在差异,汽车行驶环境(山路、平原等)带来的差异也可能造成维修信息存在较大不同,因此在把数据交给机器进行汇总归纳之前,需先行将数据进行区分,并根据车型、里程、地区将维修记录进行分组,帮助机器学习算法规避误判,更快更准确地捕捉到维修细节之间的内在关系。
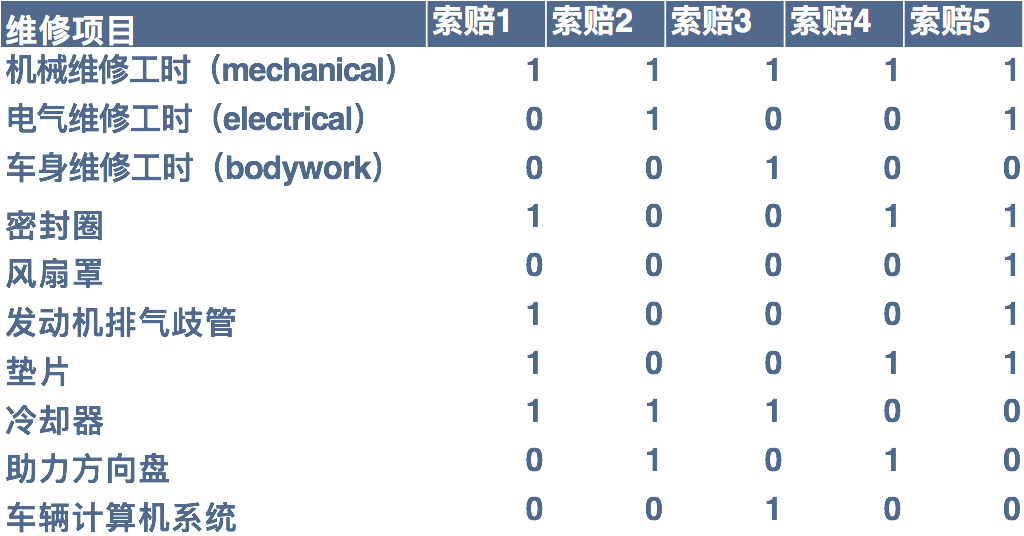
在机器能自动进行“学习”之前,需要将每一条维修记录转换成机器容易读懂理解的形式,也就是将每一条报销理赔记录,故障代码、维修项目细节、零件和工时数等转换成一串“0” 和“1”的记录,这就是矩阵运算中所谓的“高维向量”。下图中的索赔1表示这次维修中更换了密封圈、排气歧管、垫片和冷却器,并产生了机械维修工时。
然后对于每一个标注为“1”的项目,假设其不存在,并用其他所有的信息来“预测”这个项目应该为“1”的可能性(参考算法为稀疏矩阵填充算法等),循环进行计算,直到每一个标注为“1”的记录都计算完成了相应概率。下图中括号里的数字为算法计算的概率。
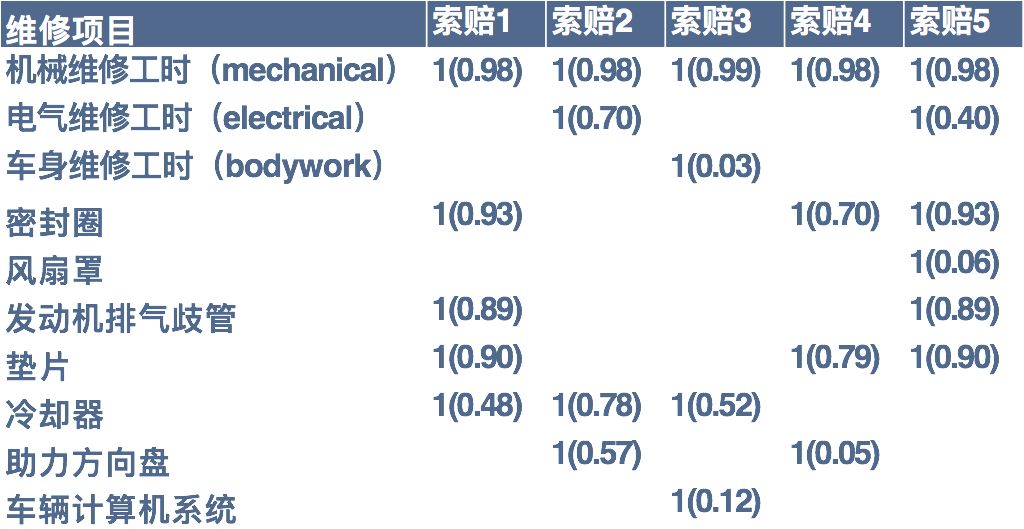
计算出的概率越低时,则表示这个收费项目在正常情况下存在的可能性越低,也就是欺诈的可能性越大。右侧表格中,“汽车信息计算机”、“助力方向盘”等项目计算的概率得分较低,因此欺诈可能性较高。如果将每项零件工时对应的金额和欺诈概率指数进行加权汇总,则可以在服务商等维度进行汇总,从而将排位较高的索赔案件、服务商进行排序。那些欺诈嫌疑较高且金额较大的主体,就可以成为风险管理部门关注的目标。
当系统部署完成并得到风险管理部门的认可以后,这个系统就可以成为实时动态屏蔽欺诈案件的第一道防线,对于任何一个欺诈嫌疑高、金额较大的案件进行标注和预警。
参考阅读:汽车维保反欺诈系统的设计和算法应用
关于作者:
赵昕,Delta Entropy Technology 七炅科技创始合伙人。曾在四大担任咨询总监,并具有多年的数据分析经验。长期专注于数据分析解决方案,聚焦金融保险和汽车行业。联系邮箱:zhaox@deltaentropy.com
杨明锋,Delta Entropy Technology 七炅科技创始合伙人。创立Delta Entropy前是美国德勤咨询(Deloitte)和毕马威(KPMG)大数据部门的技术负责人,为诸多世界五百强企业和美国政府机构提供基于大数据和人工智能技术的解决方案。联系邮箱:mfyang@deltaentropy.com
毛耀鋆,Delta Entropy Technology 七炅科技高级经理,曾任德勤上海精算及保险咨询团队咨询顾问,上海财经大学金融保险统计学士。联系邮箱:maoyj@deltaentropy.com
本文题图来自Yestone


数据分析相关的软件
永洪BI
- 4.3
(51)咨询产品免费试用帆软FineBI
- 4.2
(112)咨询产品免费试用观远数据
- 4.0
(30)咨询产品免费试用



大厂都在用的数据分析软件
Wyn Enterprise
- 4.2
(49)咨询产品免费试用微软 Power BI
- 3.8
(53)咨询产品免费试用DigiPrime
- 4.7
(36)咨询产品免费试用



限时免费的数据分析软件
亿信ABI
- 3.9
(23)咨询产品免费试用派可数据
- 4.4
(31)咨询产品免费试用云眼
- 5.0
(1)咨询产品免费试用



最新文章推荐
新锐产品推荐
欧众电商直播系统
- 0.0
(0)咨询产品免费试用HiShop直播电商
- 4.5
(1)咨询产品免费试用布谷科技-直播系统
- 0.0
(0)咨询产品免费试用好视通-云直播
- 0.0
(0)咨询产品免费试用AVCast串流直播
- 0.0
(0)咨询产品免费试用爱站网
- 0.0
(0)咨询产品免费试用







