何恺明“终结”ImageNet预训练时代:从0开始训练神经网络,效果比肩COCO冠军
编者按:本文来自微信公众号“量子位”(ID:QbitAI),作者夏乙 安妮。36氪经授权转载。

何恺明,RBG,Piotr Dollár。
三位从Mask R-CNN就开始合作的大神搭档,刚刚再次联手,一文“终结”了ImageNet预训练时代。
他们所针对的是当前计算机视觉研究中的一种常规操作:管它什么任务,拿来ImageNet预训练模型,迁移学习一下。
但是,预训练真的是必须的吗?
这篇重新思考ImageNet预训练(Rethinking ImageNet Pre-training)就给出了他们的答案。
FAIR(Facebook AI Research)的三位研究员从随机初始状态开始训练神经网络,然后用COCO数据集目标检测和实例分割任务进行了测试。结果,丝毫不逊于经过ImageNet预训练的对手。
甚至能在没有预训练、不借助外部数据的情况下,和COCO 2017冠军平起平坐。
结果
训练效果有图有真相。
他们用2017版的COCO训练集训练了一个Mask R-CNN模型,基干网络是用了群组归一化(GroupNorm)的ResNet-50 FPN。
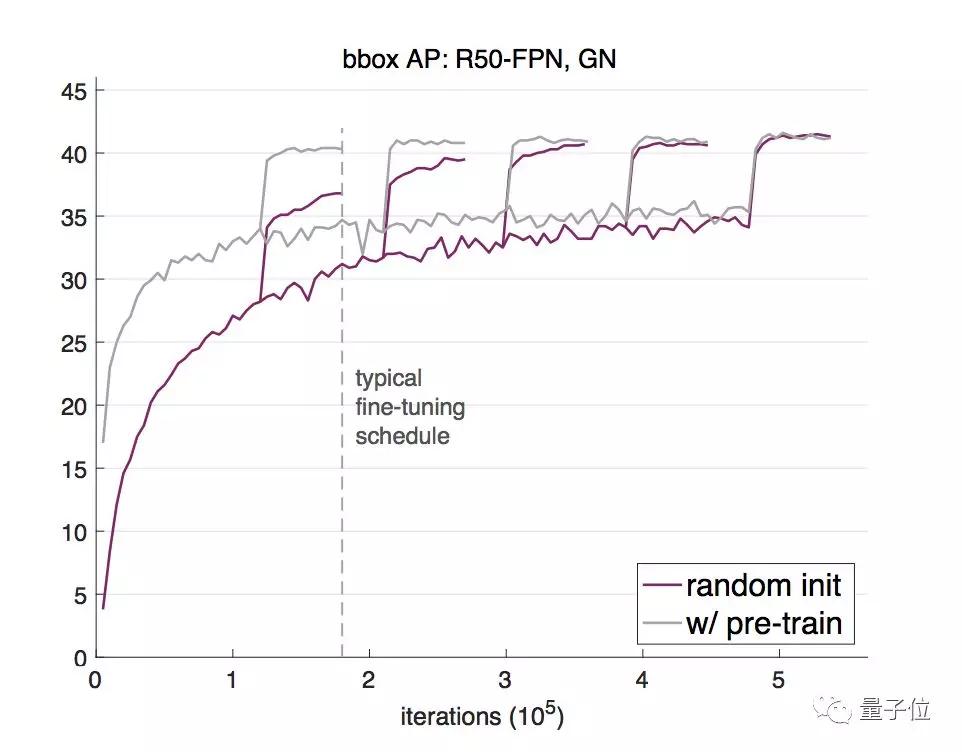
随后,用相应的验证集评估随机权重初始化(紫色线)和用ImageNet预训练后再微调(灰色线)两种方法的边界框平均检测率(AP)。
可以看出,随机权重初始化法开始不及预训练方法效果好,但随着迭代次数的增加,逐渐达到了和预训练法相当的结果。
为了探索多种训练方案,何恺明等人尝试了在不同的迭代周期降低学习率。
结果显示,随机初始化方法训练出来的模型需要更多迭代才能收敛,但最终收敛效果不比预训练再微调的模型差。
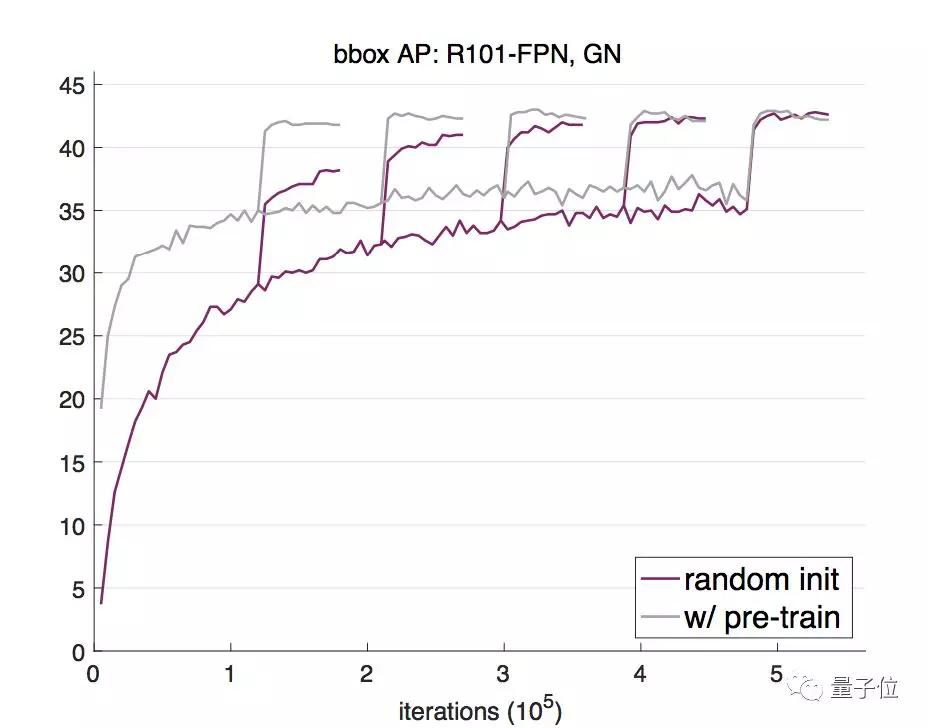
主干网络换成ResNet-101 FPN,这种从零开始训练的方法依然呈现出一样的趋势:从零开始先是AP不及预训练法,多次迭代后两者终趋于不分上下。
效果究竟能有多好?答案前面也说过了,和COCO 2017冠军选手平起平坐。
从零开始模型的效果,由COCO目标检测任务来证明。在2017版验证集上,模型的bbox(边界框)和mask(实例分割)AP分别为50.9和43.2;
他们还在2018年竞赛中提交了这个模型,bbox和mask AP分别为51.3和43.6。

这个成绩,在没有经过ImageNet预训练的单模型中是最好的。
这是一个非常庞大的模型,使用了ResNeXt-152 8×32d基干,GN归一化方法。从这个成绩我们也能看出,这个大模型没有明显过拟合,非常健壮(robust)。
实验中,何恺明等人还用ImageNet预训练了同样的模型,再进行微调,成绩没有任何提升。
这种健壮性还有其他体现。
比如说,用更少的数据进行训练,效果还是能和预训练再微调方法持平。何恺明在论文中用“Even more surprising”来形容这个结果。
当他们把训练图像数量缩减到整个COCO数据集的1/3(35000张图)、甚至1/10(10000张图)时,经过多次迭代,随机初始化看起来还略优于预训练法的效果。
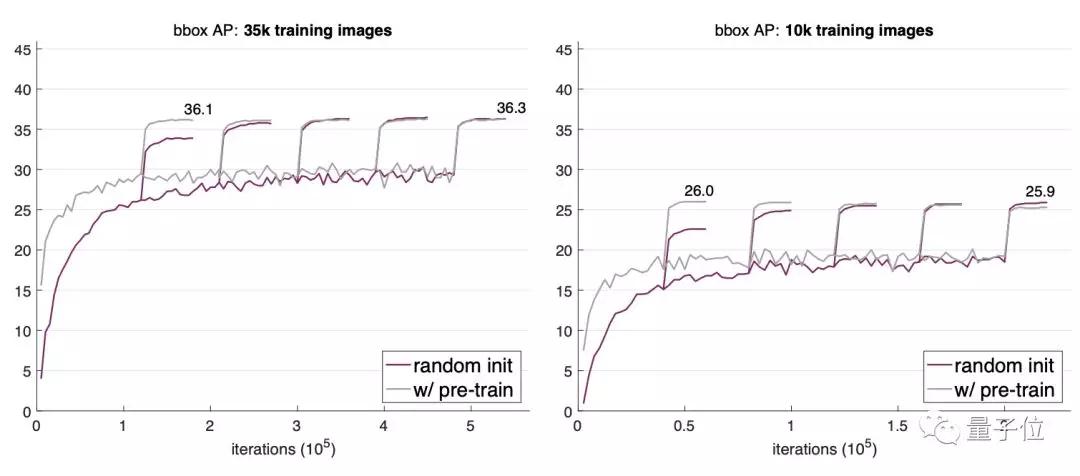
不过,10000张图已经是极限,继续降低数据量就不行了。当他们把训练数据缩减到1000张图片,出现了明显的过拟合。
怎样训练?
想抛弃ImageNet预训练,用不着大动干戈提出个新架构。不过,两点小改动在所难免。
第一点是模型的归一化方法,第二点是训练长度。
我们先说模型归一化(Normalization)。
因为目标检测任务的输入数据通常分辨率比较高,导致批次大小不能设置得太大,所以,批归一化(Batch Normalization,BN)不太适合从零开始训练目标检测模型。
于是,何恺明等人从最近的研究中找了两种可行的方法:群组归一化(Group Normalization,GN)和同步批归一化(Synchronized Batch Normalization,SyncBN)。
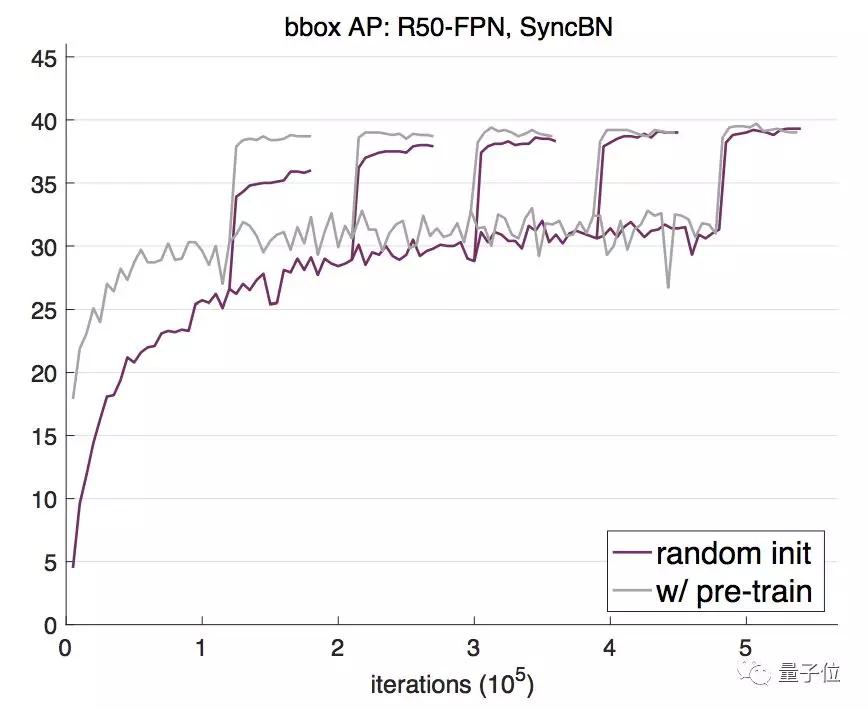
GN是吴育昕和何恺明合作提出的,发表在ECCV 2018上,还获得了最佳论文荣誉提名。这种归一化方法把通道分成组,然后计算每一组之内的均值和方差。它的计算独立于批次维度,准确率也不受批次大小影响。
SyncBN则来自旷视的MegDet,和香港中文大学Shu Liu等人的CVPR 2018论文Path Aggregation Network for Instance Segmentation。这是一种跨GPU计算批次统计数据来实现BN的方法,在使用多个GPU时增大了有效批次大小。
归一化方法选定了,还要注意收敛问题,简单说是要多训练几个周期。
道理很简单:你总不能指望一个模型从随机初始化状态开始训练,还收敛得跟预训练模型一样快吧。
所以,要有耐心,多训练一会儿。
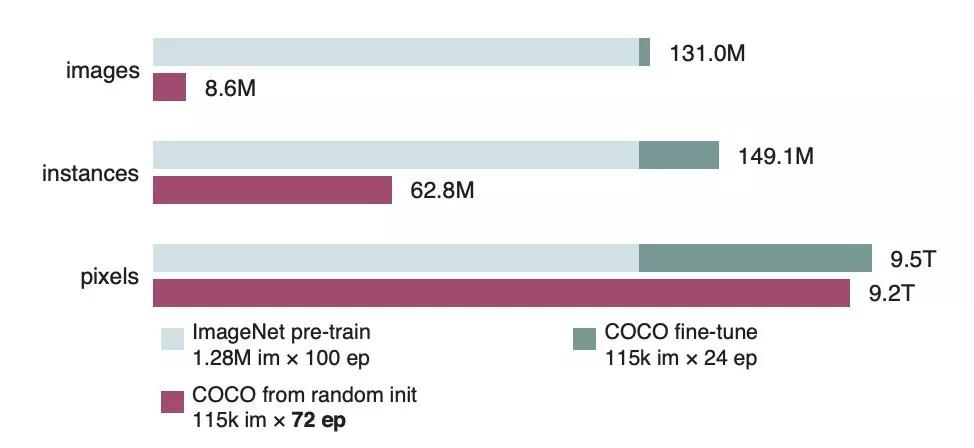
上图就是这两种方法的对比。假设微调的模型已经预训练了100个周期,那么,从零开始训练的模型要迭代的周期数是微调模型的3倍,见到的像素数量才能差不多,实例级、图片级的样本数量依然差距很大。
也就是说,要想从随机初始化状态开始训练,要有大量样本。
到底要不要用ImageNet预训练?
这篇论文还贴心地放出了从实验中总结的几条结论:
不改变架构,针对特定任务从零开始训练是可行的。
从零开始训练需要更多迭代周期,才能充分收敛。
在很多情况下,甚至包括只用10000张COCO图片,从零开始训练的效果不逊于用ImageNet预训练模型微调。
用ImageNet预训练能加速在目标任务上的收敛。
ImageNet预训练未必能减轻过拟合,除非数据量极小。
如果目标任务对定位比识别更敏感,ImageNet预训练的作用较小。
所以,关于ImageNet预训练的几个关键问题也就有了答案:
它是必需的吗?并不是,只要目标数据集和计算力足够,直接训练就行。这也说明,要提升模型在目标任务上的表现,收集目标数据和标注更有用,不要增加预训练数据了。
它有帮助吗?当然有,它能在目标任务上数据不足的时候带来大幅提升,还能规避一些目标数据的优化问题,还缩短了研究周期。
我们还需要大数据吗?需要,但一般性大规模分类级的预训练数据集就不用了,在目标领域收集数据更有效。
我们还要追求通用表示吗?依然需要,这还是个值得赞赏的目标。
想更深入地理解这个问题,请读论文:
Rethinking ImageNet Pre-training
Kaiming He,Ross Girshick,PiotrDollár
https://arxiv.org/abs/1811.08883






大厂都在用的企业培训平台软件
51CTO学堂企业版
- 4.4
(3)咨询产品免费试用考试星
- 4.5
(1)咨询产品免费试用幕印企业学堂
- 4.2
(3)咨询产品免费试用



限时免费的企业培训平台软件
微加云学院
- 4.4
(2)咨询产品免费试用SmartWinnr
- 4.7
(40)咨询产品免费试用习悦
- 5.0
(1)咨询产品免费试用



新锐产品推荐
精益派无代码开发平台
- 0.0
(0)咨询产品免费试用和信下一代云桌面系统(VENGD)
- 0.0
(0)咨询产品免费试用商基智能仓储管理系统(SJ-WMS)
- 0.0
(0)咨询产品免费试用商基SJ-SRM管理平台
- 0.0
(0)咨询产品免费试用普巴工作流程平台
- 0.0
(0)咨询产品免费试用爱德数智-不动产资产管理系统
- 0.0
(0)咨询产品免费试用







