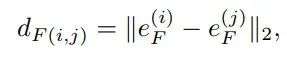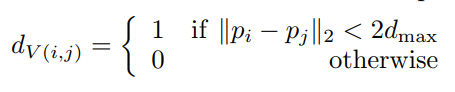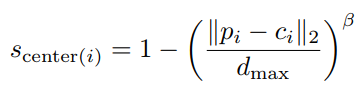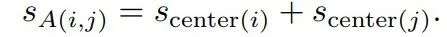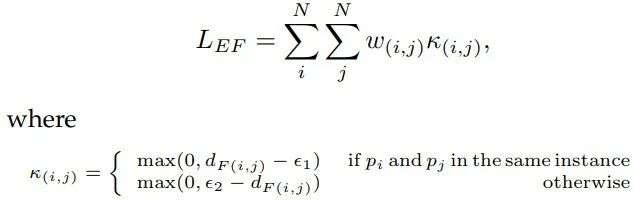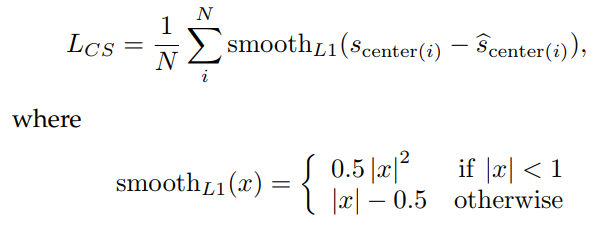让机器人不再"抓瞎": FPCC-Net, 一种基于点云聚类的高速实例分割算法
编者按:本文来自微信公众号“将门创投”(ID:thejiangmen),作者:让创新获得认可,36氪经授权发布。
From: Tohoku University编译: T.R
在bin-picking场景中,要区分大量混叠在一起的物体是十分困难的,但有一定的先验知识来辅助算法。虽然有很多个物体堆叠在一起,但它们的类别相同,而且还能提前获取其CAD模型,至于语义信息则可以忽略不记。
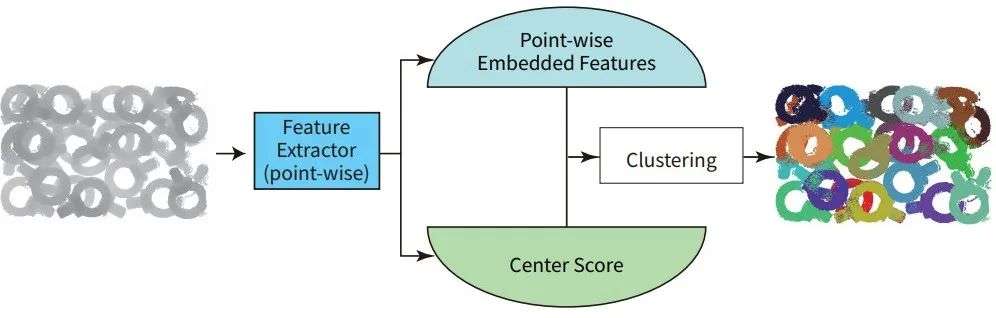
在实际需求的引导下,来自日本东北大学的研究人员提出了一种包含两个子网络结构的新型点云实例分割算法FPCC-Net,通过推理出点云实例的特征中心,随后在特征空间中将同一实例的其余点聚类到特征中心附近,从而实现点云实例分割。
更多详情,请参看论文原文:
论文链接:https://arxiv.org/abs/2012.14618
实例分割是许多应用不可或缺的预处理任务,从机器人到自动驾驶、再到人机交互,都少不了实例分割。然而,工业界机器人抓取问题中基于点云的实例分割研究还较少,在这一场景中,需要对同一类堆叠在一起的物体的不同个体进行分割,以便于机器人优化位姿,更高效地进行抓取和分拣。
与2D图像领域的高速发展相比,基于3D点云的实例分割还有很大的发展空间。目前这一领域主要存在三个问题:
1. 基于卷积的网络难以有效处理无序的点云数据;
2. 高质量标注的三维点云数据还比较缺乏;
3. 基于CNN的点云实例分割算法比较耗时。
在实际需求的引导下,来自日本东北大学的研究人员提出了一种包含两个子网络结构的新型点云实例分割算法FPCC-Net,通过推理出点云实例的特征中心,随后在特征空间中将同一实例的其余点聚类到特征中心附近,从而实现点云实例分割。
这一算法的目标是,在无需大规模手动标注数据的前提下,得到一个可以实用化的高速点云分割算法。它首先将点云映射到一个具有可区分性的特征空间中,使得属于同一实例的点具有相似的特征、不同实例的点具有可分离的特征。同时,寻找到每一个实例的中心点,将其视为聚类的参考点,来加速聚类算法的处理。
FPCC方法
本文提出的高速点云聚类方法,主要通过寻找点云的聚类中心,并基于这一中心来对同一实例的点云进行聚类。训练过程中所使用的合成数据集自动生成标注,并且不携带额外的颜色信息。整个点云都被转换到以其归一化后坐标的新坐标系下。每个点除了包含 x、y、z 三个坐标向量,同时还包含 Nx、Ny、Nz 三个方向上的法向量,送入网络后将得到每一个点的实例标签。
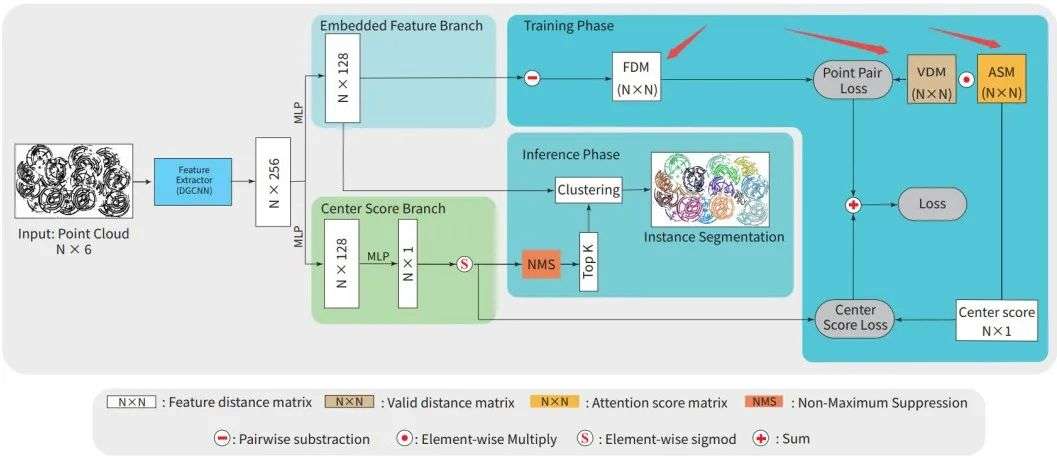
整个FPCC网络的结构如下图所示,它分为特征抽取器、中心获取分支和嵌入空间特征获取分支三个主要部分。
如图所示,三维点云(X, Y, Z Nx, Ny, Nz) 被送入到网络中获取每一个实例的标签。首先利用特征抽取器获取每一个点的特征,而后被送入到两个独立的分支中进一步处理。一方面,二进制的有效距离矩阵用于减小较远点之间的权重;另一方面,注意力分数矩阵则用于增加与中心点较近的点的权重。
点云处理一般都需要抽取点云的特征,在这一工作中,研究人员使用了DGCNN的结构来为每一个点进行特征抽取,针对N个点构成的点云将获得N×256的特征,而后这一特征将被送入嵌入特征分支和中心得分分支。
在嵌入特征分支中,被抽取的特征首先通过多层感知机被转换为128维;而中心得分分支则与嵌入特征分支并行推理出每一个点作为中心点的分数。
下面的算法流程展示了如何为每一个目标寻找到几何中心的过程,这样以后,每一个目标的中心点将作为参考点进行聚类。在中心得分分支中,来自特征抽取器逐点的特征将通过激活函数并得到N×1的最终分数结果。
在中心打分阶段,研究人员还使用了非极大值抑制的方式来为每个实例寻找中心点。首先将分数大于0.6的点视为候选点,而后选取其中分数最高的点作为中心点,并将剩下的点按中心点到实例上最远点的距离来剔除。
为了训练这一网络,研究人员提出了精巧的损失函数设计,并引入了特征距离矩阵、有效距离矩阵和注意力分数矩阵三个度量标准用于嵌入空间的学习。
引入特征距离矩阵,是为了让属于同一实例的点在特征空间中尽可能的接近,而输入不同实例的点则需要尽可能与其他实例区分开来。为了使输入同一实例的点云特征尽可能相似,研究人员引入了下面的指标来定义特征距离矩阵,使得同一实例的点云在特征空间中尽可能接近。
为了让网络能有效判断在一定欧式距离内的点是否属于同一个实例,FPCC中还引入了二进制的有效距离矩阵。在模型的推理阶段,点云同时通过特征距离和点之间的欧式距离进行聚类,如果欧式距离超过了两倍的最大距离 d_max,这两个点就不会从属于同一个实例。那么这时就需要忽略这个点,使其不产生损失。其定义如下所示:
此外,中心分数的设计用于点与其实例中心间的距离。在边界内,距离中心越近的点,中心分数也将越高,那么中心分数可以定义为下面的形式:
其中 β 是常量指数,而 c_i 则是中心点的坐标。在实验中将 β 设为2,使得边界附近的点得分接近0,而中心附近的点得分接近1。下图显示了每个实例的中心分数分布。
红色表示更高的中心得分,边界部分则更趋近于0。
最后还引入了注意力分数矩阵来增加重要点之间的权重,使得靠近中心的点具有更高的权重:
在前面多种度量标准的基础上,最终的损失函数包含了嵌入特征损失和中心得分损失两个部分。其中嵌入特征损失需要通过注意力矩阵和有效距离矩阵来逐元素相乘获取权重矩阵 W,此时这部分损失就可以定义为:
其中的 κ 意味着:属于不同实例点的特征距离要比输入相同实例点的特征距离要大。同时,如果两个点间的距离小于阈值就可以忽略,这将有助于模型对特征空间的学习。
对于中心分数,研究人员利用了较为鲁棒的 L1 损失,并使用了 Smooth L1 函数来进行计算:
实验结果
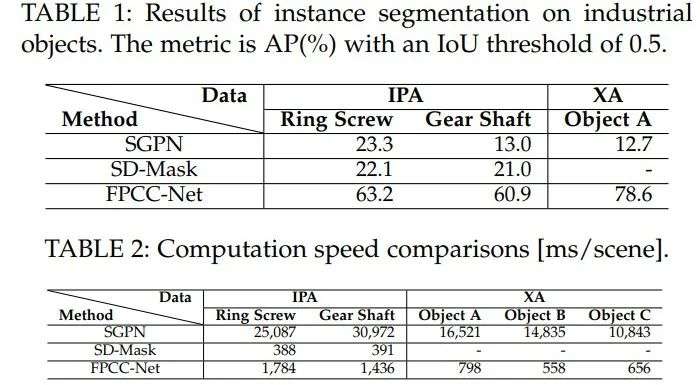
研究人员分别在夫琅禾费 IPA Bin-Picking 数据集上和 XA Bin-Picking 数据集上进行了实验。输入点云为随机采样得到了4096个点。下图显示了与几种前沿方法比较的结果,不同的实例用不同颜色展示出来。
针对几种典型的物体,研究人员还比较了不同方法的AP和在不同类目标上的运行时间(实验中使用了 Intel i7 8700K,GTX1080 )。
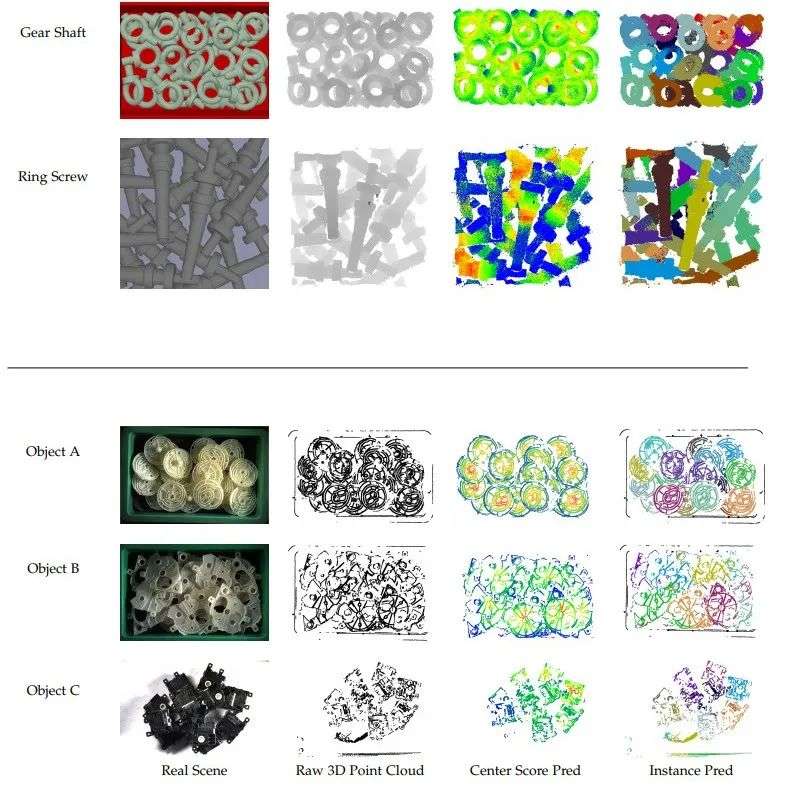
再来看看这种方法得到的一系列优异的结果,上半部分来自于 IPA 数据集,而下半部分则来自于 XA 数据集。
预测结果显示了中心的估计结果和实例分割结果。






大厂都在用的企业培训平台软件
51CTO学堂企业版
- 4.4
(3)咨询产品免费试用考试星
- 4.5
(1)咨询产品免费试用幕印企业学堂
- 4.2
(3)咨询产品免费试用



限时免费的企业培训平台软件
微加云学院
- 4.4
(2)咨询产品免费试用SmartWinnr
- 4.7
(40)咨询产品免费试用习悦
- 5.0
(1)咨询产品免费试用



新锐产品推荐
ProcessOn
- 3.9
(431)咨询产品免费试用有赞
- 3.9
(163)咨询产品免费试用日事清
- 3.8
(13)咨询产品免费试用企优托
- 4.5
(2)咨询产品免费试用Live800
- 4.8
(5)咨询产品免费试用酒店哥哥
- 2.5
(1)咨询产品免费试用