潮科技行业入门指南 | 深度学习理论与实战:提高篇(11)——实例分割
编者按:本文节选自《深度学习理论与实战:提高篇 》一书,原文链接http://fancyerii.github.io/2019/03/14/dl-book/ 。作者李理,环信人工智能研发中心vp,有十多年自然语言处理和人工智能研发经验,主持研发过多款智能硬件的问答和对话系统,负责环信中文语义分析开放平台和环信智能机器人的设计与研发。
以下为正文。

本文介绍用于实例分割的Mask R-CNN算法。
简介
Mask R-CNN基于Faster R-CNN,首先是使用RPN(可以加上FPN)得到候选区域(RoI),然后使用RoI Pooling的技术把这些区域的特征变成固定大小。Faster R-CNN在RoI Pooling后的特征上加上一些全连接层然后分类和bounding box回归。而Mask R-CNN在此基础上再加了一些卷积网络层用来判断某个候选区域的每一个像素是否属于这个目标物体,如下图所示。这个卷积网络层的输入是特征映射,输出是一个和RoI一样大小的矩阵。值为1表示模型预测这个像素属于目标物体,0则不属于。
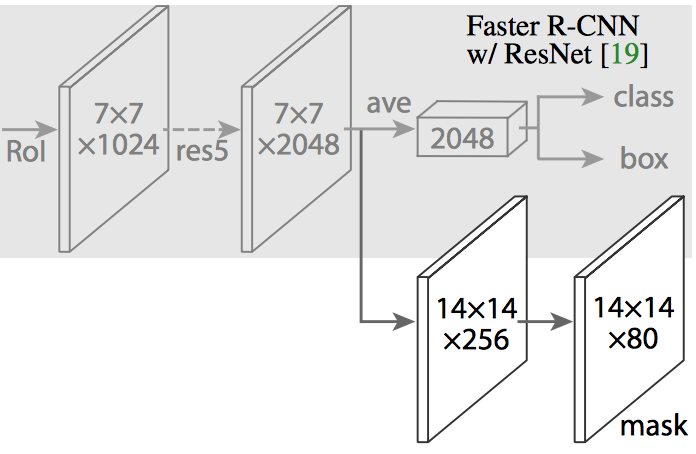
Mask R-CNN是Faster R-CNN的基础上增加一个Mask分支
Mask R-CNN的实际结构如下图所示,它需要把RoI Pool层变成一个RoI Align层,原因我们下面会详细介绍。
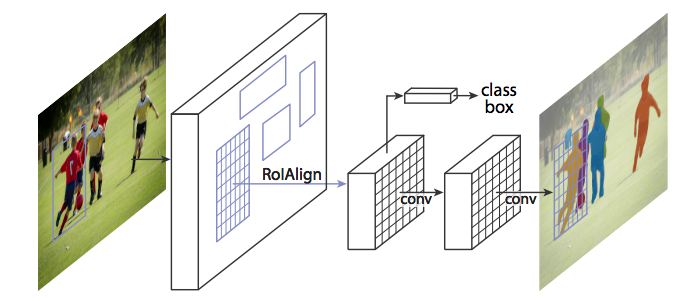
Mask R-CNN结构图
RoI Align
Mask R-CNN的想法非常简单,是Faster R-CNN的自然推广。但是RoI Pooling在用于实例分割时会有比较大的偏差,原因在于Region Proposal和RoI Pooling都存在量化的舍入误差。ROI Pooling这一操作存在两次量化的过程:
将候选区域量化为整数点坐标值
将量化后的区域分割成 k x k 个单元(bin),不能整除时也需要量化
经过上述两次量化,此时的候选区域已经和最开始回归出来的位置有一定的偏差,这个偏差会影响检测和分割的准确度。在论文里,作者把它叫作“不匹配问题(misalignment)。
我们用一个的例子具体分析一下不匹配问题。如下图所示,这是使用Faster-RCNN来实现目标检测。输入是800x800的图片,图片上有一个665*665的候选区域(里面是一只狗)。图片经过主干网络(backbone)进行提取特征后,特征映射的步长(stride)为32。因此,图像和候选区域的长度都是输入的1/32。800正好可以被32整除变为25。但665除以32以后得到20.78,有小数,于是ROI Pooling 把它量化成20。接下来需要把20x20的输入通过RoI Pooling变成7x7的大小,因此将上述包围框平均分割成7x7个矩形区域。显然,每个矩形区域的边长为2.86,又含有小数。于是ROI Pooling 再次把它量化到2。经过这两次量化,候选区域已经出现了较明显的偏差(如图中绿色部分所示)。更重要的是,该层特征映射上0.1个像素的偏差,缩放到原图就是3.2个像素。那么0.8的偏差,在原图上就是接近30个像素点的差别,这一差别是非常巨大的。
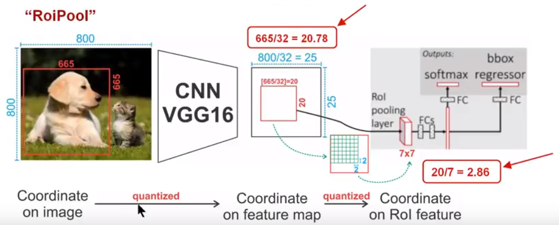
RoI Pooling存在两次量化误差
为了解决ROI Pooling的上述缺点,作者提出了ROI Align这一改进的方法(如下图所示)。ROI Align的思路很简单:取消量化操作,使用双线性内插的方法获得坐标为浮点数的像素点上的图像数值,从而将整个特征聚集过程转化为一个连续的操作。值得注意的是,在具体的算法操作上,ROI Align并不是简单地补充出候选区域边界上的坐标点,然后将这些坐标点进行池化,而是重新设计了一套优雅的流程,如下图所示。流程为:
遍历每一个候选区域,保持浮点数边界不做量化
将候选区域分割成k x k个单元,每个单元的边界也不做量化。
在每个单元中计算固定四个坐标位置,用双线性内插的方法计算出这四个位置的值,然后进行最大池化操作。
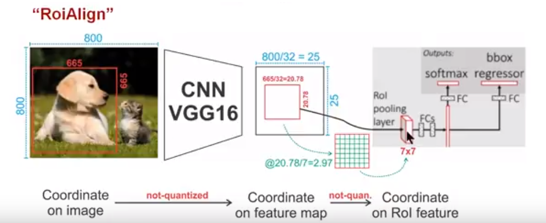
ROIAlign能避免量化误差
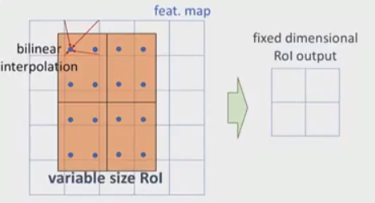
ROIAlign的插值
这里对上述步骤的第三点作一些说明:这个固定位置是指在每一个矩形单元(bin)中按照固定规则确定的位置。比如,如果采样点数是1,那么就是这个单元的中心点。如果采样点数是4,那么就是把这个单元平均分割成四个小方块以后它们分别的中心点。显然这些采样点的坐标通常是浮点数,所以需要使用插值的方法得到它的像素值。在相关实验中,作者发现将采样点设为4会获得最佳性能,甚至直接设为1在性能上也相差无几。事实上,RoI Align 在遍历取样点的数量上没有RoI Pooling那么多,但却可以获得更好的性能,这主要归功于解决了misalignment的问题。实验时发现,ROI Align在VOC2007数据集上的提升效果并不如在COCO上明显。造成这种区别的原因是COCO上小目标的数量更多,而小目标受misalignment问题的影响更大。
再来分析一下RoI Align的思路,其实很简单:候选区域进行缩放时并不进行量化。这似乎有点问题——我们怎么得到这个区域某个点的值呢?答案是不需要,因为我们并不需要得到图中狗嘴巴(假设它不是整除的点)的特征值(当然一定需要也可以通过双线性插值得到)。接下来比如我们要把这个候选区域对于的特征区域(20.78x20.78)切分成7x7,那么我们得到的更小区域是2.97x2.97。我们需要的是对这个这个更小区域进行max pooling。假设我们要进行2x2的max pooling,那么我们就可以把这个2.97x2.97的区域再切分成一个2x2的4个方框,然后对这4个方框的中心点求max pooling。现在问题来了,这个4个中心点的坐标可能不是整数。那么怎么办呢?在25x25的特征映射里找离它最近的4个点,然后进行双线性插值来估计这个点的值。
上图演示了插值过程,图中特征映射是6x6(注意图中的“格子”是5x5,但是每个点表示一个特征映射的中心,这和我们经常的习惯有些不同),候选区域的位置被精确的定位在特征映射图中,并且精确的切分成2x2(RoI Align的输出是2x2),接着这2x2的每个方格都被再切分成4各部分,每个部分的中心点用蓝色的点表示。每个方格都是求这4个中心点的最大值(max pooling),现在我们需要求每个蓝点的值,这可以通过双线性插值来实现,图中展示了最坐上的一个蓝点是怎么求值的——在6x6的特征映射中找到离它最近的4个(图中红线表示),然后用双线性插值求蓝点的值。
损失函数
Mask R-CNN的损失函数及注解如下:







行业专家共同推荐的软件
51CTO学堂企业版
- 4.4
(3)咨询产品免费试用考试星
- 4.5
(1)咨询产品免费试用幕印企业学堂
- 4.2
(3)咨询产品免费试用



限时免费的企业培训平台软件
微加云学院
- 4.4
(2)咨询产品免费试用SmartWinnr
- 4.7
(40)咨询产品免费试用习悦
- 5.0
(1)咨询产品免费试用



新锐产品推荐
安友-分销管理系统
- 0.0
(0)咨询产品免费试用安友-化工行业ERP
- 0.0
(0)咨询产品免费试用安友-固定资产管理系统
- 0.0
(0)咨询产品免费试用京东云-云数据库 MongoDB
- 0.0
(0)咨询产品免费试用京东云-DDoS 基础防护
- 0.0
(0)咨询产品免费试用京东云-SSL 数字证书
- 0.0
(0)咨询产品免费试用







