七分之一在线评论都有假,人工智能救一把?
编者按:本文来自微信公众号”亲爱的数据“(ID:deardata),作者:谭婧,36氪经授权发布。
评论区,是难以忽视的公共地区。
据目测,评论区是中国文学大师密度最高,骂人水平最高和逗逼水准最高的地方,A站B站还把评论玩成弹幕。
平台型APP因“评论”文化的迥异,体现出别样的审美与趣味,知乎体、爷青回,成为“时髦”的暗号。

在宏观层面,“网民评论”被定义为具有舆论属性和广泛的社会动员能力。所以,排查、约谈、暂停、整改、审核也都是管理机构的常用“大锤”。
有一批活跃的、对社区品牌有认同,并产生大量优质内容的用户,是社区的福气。
表面上 “评论区”肩负社区氛围组的重任,是互联网“公共场所”。
背地里,分享意见左右消费决策,进而影响生意。
(根据英国政府的数据,仅在英国,在线评论每年就影响了约280亿美元的酒旅预订交易。)
而评论区不是乌托邦,
大众点评(数量质量都不高,没营养的口水评论多)
小红书(水军多,付费版高级测评师云集)
淘宝(数量多,看得累,返现金,得好评)
马蜂窝(偷偷搬运别人家的评论据被实锤了)
这不是单一现象,外媒CNN甚至抛出一个数字:全球互联网,七分之一的酒旅在线评论是假的。
“评论区”青山常在,柴不断,就绕不过人工智能(AI)的重要方向,自然语言处理(NLP),让计算机像人类一样对“中文/文字”进行理解。
群众高呼,请AI紧急上线,内容检测、水军识别、脏话删除、不良内容处理。
01.自然语言处理技术,挺行的
话说,NLP技术在互联网大厂已经用得非常好了,搜索、推荐、广告、智能助理等许多系统中都有身影,技术团队紧咬学术前沿。
先看工业界,新东方教育2018年就开始有学员用户画像项目,进行等级分类。NLP技术对相关结构化数据文本,数据标签化,并增加用户圈选和行为事件分析功能,各个业务部门可以根据标签圈选学员。
汽车之家机器学习小组,为机器之家用户产品中心下属认知智能组,NLP技术支持用户选车,多轮对话。
2020年,京东智联云在双十一的第一个小时,情感智能客服服务138万次,使用情感识别、语音交互等智能化技术。
美团搜索,用机器理解用户的各种查询意图。可是,用户意图会随着时间变化,在有限的关键词中解读出非常丰富的信号,用于各种搜索的召回、排序以及展示。美团专门设有人工智能平台/搜索与NLP部门。
再者,美团大脑挖掘、关联各个场景数据,用人工智能算法让机器“阅读”用户针对商户的公开评论,理解用户在菜品、价格、服务、环境等方面的喜好,构建人、店、商品、场景之间的知识关联,可以认为是“餐饮娱乐的知识大脑”,支持搜索、SaaS 收银、金融、外卖业务服务。
作为一种非结构化文本,用户评论蕴含了大量非标准表达的“单词”。
机器根据句子所在上文的一系列“单词”,预测后面会跟哪个“单词”,预测的是概率大小,句子里面每个“单词”都有个根据上文预测的过程,把所有这些“单词”的产生概率乘起来,数值越大,代表这句话越像一句人话,而不是鬼话或者胡话。
所以,除了人类,机器也可以判断,哪个句子更像一句人话。

“黄鹤楼”一词,可能有三个意思。武昌蛇山之巅的名楼,北京的商家,湖北香烟品牌。AI算法也不傻,预测则可结合上下文,前文在讲长江、景点、旅游、票价、登高远眺,就不会推测出此处的“黄鹤楼”是在讲香烟,而是景点的概率更大。
再比如猫眼文娱,可以获取电影、电视剧、艺人等信息,形成一部“词典”。但是随着搜索体量增大,搜索表述复杂,词典满足不了用户需求,就会使用AI模型,作为词典的补充。
再看学术界,诞生了名叫Transformer的模型(一种深度神经网络),基于Transformer的 BERT模型(2018年技术重大进展),GPT模型(硅谷OpenAI实验室出品),它们都使用预训练和微调的思路来解决问题。
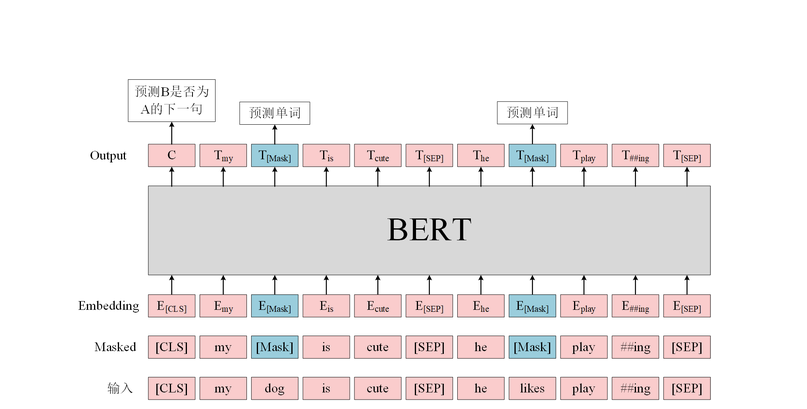
预训练语言模型,就像在无标注文本的大海里,学到潜在的语义信息,而无需为每一项任务单独标注大量训练数据。语言模型预训练结束,再使用少量标注语料进行微调(Fine-tuning)来完成具体的NLP任务,比如分类、序列标注、句间关系判断和机器阅读理解等。
总之,算法的“性能”得到显著改善,BERT做大了NLP技术的蛋糕。
02.运营组,也挺行的
《亲爱的数据》和几位互联网大厂的运营小哥哥聊了一会,各家“评论”的运营花了很多心思。
抖音的评论区是双轨制,既有最热的评论,也有最新的评论。最新的评论可以理解为一个小池子,根据用户的点赞数量,来看要不要继续推。这样能保证发得比较晚的神评论也能排上来,属于推荐思想在评论区的一种应用。
抖音搜索是有考虑过识别到评论区如果提问的人比较多,会有提示搜索的建议。但路径太长,直接改成了目前的高热社会类视频下面,加一个今日头条的文章链接。
常见的处理评论区数据的方法是结构化,电商和酒旅APP都对几十亿条评论区做了结构化处理,这里是指对数据做结构化处理,因为计算机能处理的都是结构化的,非结构化的数据它理解不了,所以文本在涉及到“理解”这一层,都是需要先结构化。
NLP分析了评价,提炼了“分词”,加了结构化的外展,相当于找到了“标注”,提高了用户浏览评论的效率。英雄所见略同,用户理所当然的认为,人数越多,观点越可信。
日常中,在淘宝购买一款升降桌,“安装效果好”“质量好”“用后感觉好”。选酒店的时候,你能看到多少人提到了“便宜”、“舒适”,又有多少人提到了“安静”“交通方便”。
很显然,消费+社区的评论会有门槛,淘宝、小红书、大众点评、马蜂窝等。商品没下单,没经历的用户不能参与评论。
看热闹的是外行,探店的往往是内行,平台会倾向把好评往前排,促进转化,消费后的诉求也会偏多,需要专门的回应,处理。纯娱乐、纯讨论的社区,参与评论的门槛低,抖音、快手、B站、芒果、豆瓣。一般来说,电商评论运营得好,有卖货的诉求,大家聊的都是和商品相关的。
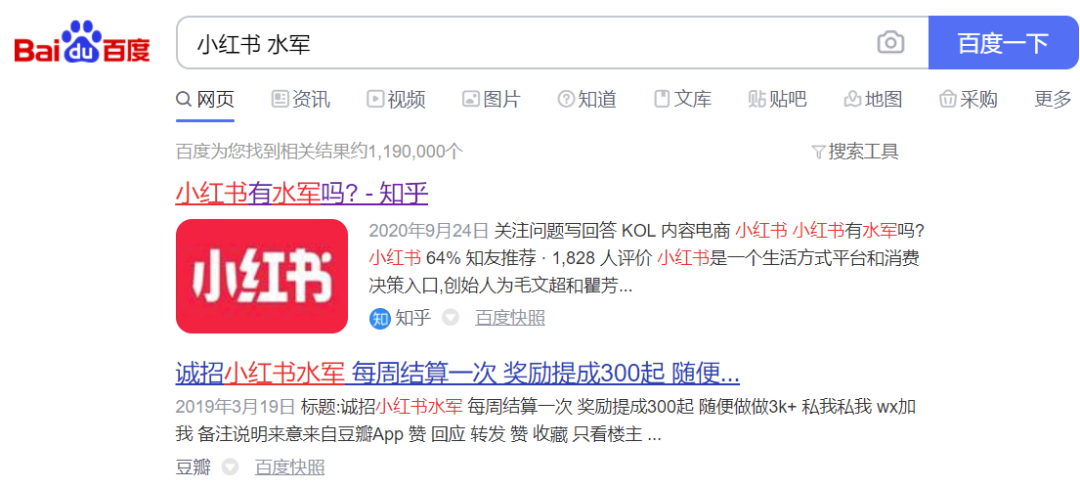
小红书的铁粉认为,虽然很多评价都是花钱买的。大V粉丝量多了就会接广告。但是,小红书整体测评感比较强,和无脑水军还不太一样,即使是托儿,也写得很诚恳。
评论是“UGC(用户生产的内容)”,既真实,又新鲜,可以挖掘出潜在商业价值。对用户来说,人人都需要“真实”而且“好用”的评论,无论是“经验”“干货”,还是“指南”。
03.为啥没有管好“评论”?

技术这么硬,起点这么高,为啥还管不好“评论区”。
这里,有三个绊脚石:
第一,评论数据质量特别差,注意“特别”两字。
数据治理水平低导致人工智能算法在很多时候效果不好。算法效果的好坏,与训练数据有很大关系,可以说一份好的标注数据,用一个普通的算法,也能有好的性能。现实中,企业想要做好 NLP,首先需要打通基础数据。评论数据的底子太差,麻袋上绣花,白费劲。
第二,“假装”在用。
反正大家都在智能化,装也得装着在用。把AI技术用起来,是“老板们”的刚需。有时候,工程会退化到自动化阶段,只是少部分用了算法智能。目前做得多的,也就是情感倾向分析,垃圾评论过滤等等。AI用不好,会变成噱头,可能倒退到最基础的统计分析图表。
第三,不重视。
很多互联网厂商认为,评论区是第二场景,有些二等公民的意味。
说白了,不够重视,或者说支持主要业务“(推荐和搜索)”的技术还做得不够好,根本顾不上评论区。挖掘得不够,应用的深度和广度不够。管理评论的主动力之一就是只是满足政府管理部门的监管要求。
综上,NLP技术对运营的号召力还不够大,影响还不够深刻,NLP与运营还没有形成彼此不分的鱼水关系。
英国南安普顿大学毕业的AI算法科学家袁雪瑶,也在采访中透露:“互联网厂商会针对用户发布的评论内容有半人工识别,加上人工的数据标注。NLP现在比较成熟的领域有,情感分析、舆情分析、和用户画像,这些会对运营有比较适中的影响。”
(基于深度学习的情感分类方法,它能够从海量的数据中主动学习文本中的语义信息并获得文本的特征与情感分类,达到精准提取文本数据与情感的目的。比如“消极”“积极”)
一位来自平安智汇企业有限公司的算法专家也认为:“评论里,口水多,分析就是得把其中有价值的给自动筛选出来。NLP技术正在解决问题,还做不到药到病除。”
“适中”一词用得特别好,NLP还有很大的战场,要与运营做盟军,攻克业务侧的难题。评论中使用的挖掘技术方法也包含了很多种,规则、传统机器学习模型、深度学习模型等。
虽然专职挖掘“评论”商业价值的明星AI产品似乎还没有出现,但是,有人注意到了。

东京大学的创业企业TDAI Lab认为应该面向点评网站等推销人工智能工具。
他们分析了4000多个日式拉面餐厅的评论,发布了东京版“人工智能排名,最优百家拉面店”。
在剔除疑似“刷好评”和“恶意差评”的情况下,人工智能选出了评价高的店铺。

分析“评论区”不立刻关乎生死,又能给企业降本增效的场景不应该被忽视。
AI 技术需要算力,需要数据,需要算法模型,更需要应用场景。很多AI公司一开始就想给高速列车换轮子,以这种雄心壮志去敲开传统企业的大门成功率很低,因为客户对新技术和AI公司都没有信任。
刷好评和恶意差评,消费者和餐饮店都有损失。消费者找不到好店,好店也失去了商机。
1968年,哈定(Garrett Hadin)在《科学》杂志上发表了一篇文章,题为The Tragedyof the Commons。译成《公地悲剧》,原文中的the commons还包括公共的空间。
评论区环境的恶化,没有人是赢家。AI审核、AI接管评论区是必然趋势,“评论”需要才华,管好“评论”更需要才华。
(完)






行业专家共同推荐的软件
亿企代账
- 4.3
(3)咨询产品免费试用捷税宝
- 4.5
(14)咨询产品免费试用云代账
- 3.8
(6)咨询产品免费试用



限时免费的代理记账软件
小微律政
- 3.8
(6)咨询产品免费试用花生账
- 4.2
(9)咨询产品免费试用易代账
- 3.8
(4)咨询产品免费试用



新锐产品推荐
草料二维码
- 4.3
(18)咨询产品免费试用广大大
- 4.7
(29)咨询产品免费试用trackingio
- 4.2
(2)咨询产品免费试用二维斑马
- 4.6
(2)咨询产品免费试用联图网
- 0.0
(0)咨询产品免费试用263云通信-云邮
- 4.1
(26)咨询产品免费试用







