在第三代英特尔® 至强® 可扩展处理器上,借助支持 Bfloat16 功能的英特尔® 深度学习加速技术,可显著提升“文本转语音 (TTS)”性能
作者
腾讯:Qiao Tian,高级研究员;Linghui Chen,首席研究员;Heng Lu,首席研究员;Dong Yu,杰出科学家
英特尔公司:Pujiang He,软件架构师;Ethan Xie,高级云软件工程师;Jianyan Lv,高级云软件工程师;Ciyong Chen,高级深度学习软件工程师
当前,人们提议将 WaveNet、Parallel WaveNet、WaveRNN、LPCNet 和 Multiband WaveRNN [1] 等神经声码器用于序列到序列声学模型,以提高 TTS 质量。WaveNet 声码器虽然可以生成高保真音频,但计算上巨大的复杂性限制了它在实时服务中的部署;LPCNet 声码器利用 WaveRNN 架构中语音信号处理的线性预测特性,可在单个处理器内核上生成超实时的高质量语音。但是,这对在线语音生成任务而言仍不够高效。
因此,腾讯 AI Lab(人工智能实验室)和云小微率先开发出一款基于 WaveRNN 多频带线性预测的全新神经声码器 FeatherWave [2],可以帮助用户显著提高语音合成效率。腾讯工程师与英特尔工程团队紧密合作,将面向第三代英特尔® 至强® 可扩展处理器(之前代号为 Cooper Lake)所做的优化进行全面整合,采用了英特尔® 深度学习加速技术(英特尔® DL Boost)中全新集成的 16 位 Brain Floating Point (bfloat16) 功能。通过优化,相同质量水平 (MOS4.5) 的文本转语音速度比 FP32 提升了高达 1.54 倍。
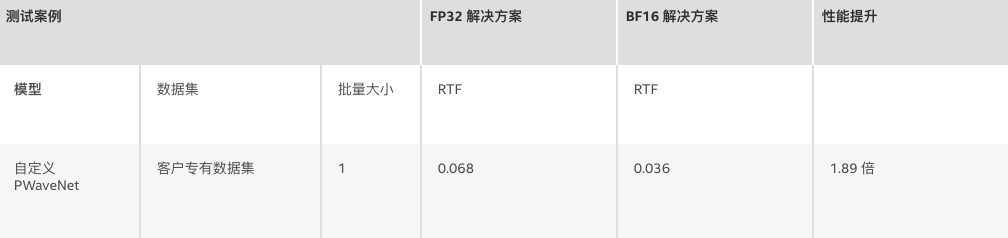
另外,腾讯还以 GAN 和 Parallel WaveNet (PWaveNet) [3] 为基础,推出一种改进后的模型。由于在当前部署的第二代英特尔® 至强® 可扩展处理器上运行 PWaveNet,其性能无法满足腾讯的实时要求,腾讯和英特尔便基于第三代英特尔® 至强® 可扩展处理器对模型性能进行了优化,使性能与采用 FP32 相比提升了高达 1.89 倍,同时质量水平保持不变 (MOS4.4)。
在本博客中,我们将介绍运行在第三代英特尔® 至强® 可扩展处理器上的 WaveRNN 和 PWaveNet 自定义模型的优化技术和性能测试结果。英特尔® 至强® 可扩展处理器专为运行复杂的人工智能 (AI) 工作负载而生,借助英特尔® 深度学习加速技术将嵌入式 AI 性能提升至新的高度。此种处理器现已支持英特尔® 高级矢量扩展 512 技术(英特尔® AVX-512 技术)和矢量神经网络指令 (VNNI)。随着第三代英特尔® 至强® 可扩展处理器的推出,英特尔® 深度学习加速技术现已集成了 bfloat16 加速。bfloat16 是 FP32 的精简版,与半浮点精度 (FP16) 相比,可为深度学习工作负载提供更大的动态范围。它无需使用校准数据进行量化/去量化操作,因此比 INT8 更方便。
英特尔® 深度学习加速技术现包括以下 bfloat16 指令:
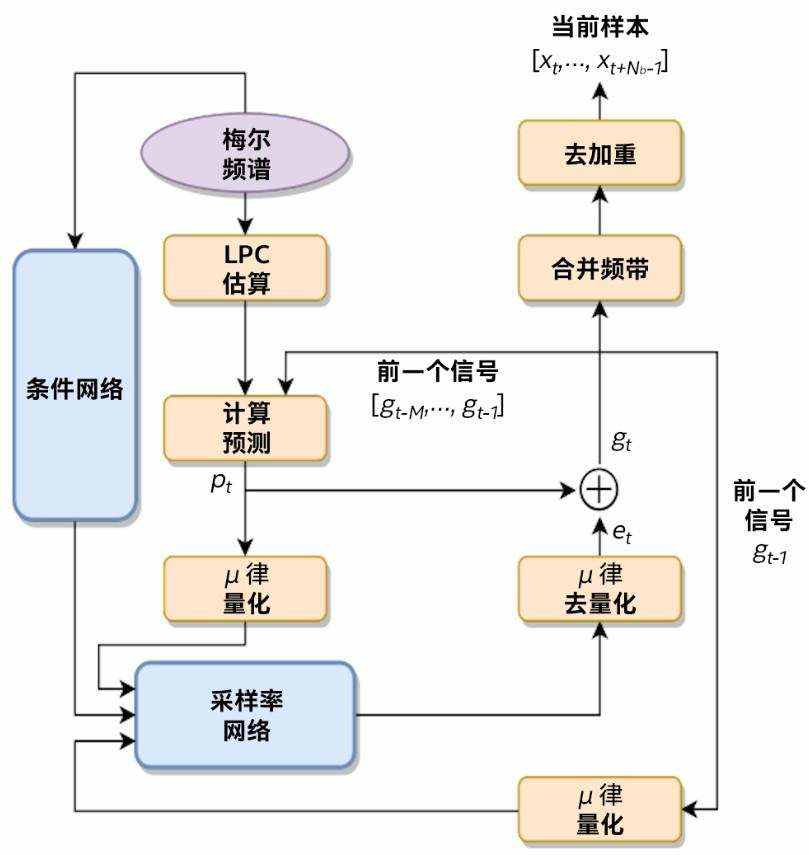
自定义 WaveRNN
图 1 是关于腾讯提出的 FeatherWave 声码器 [2] 结构的说明。其中提到的梅尔频谱广泛应用于神经 TTS 系统,用作条件网络的输入,而采样速率网络则将产生数个具有多/双 softmax 输出层的样本。与初始 WaveRNN 一样,采样网络首先会预测激励信号的粗略部分 (coarse part)。然后,通过调节预测的粗略信号 (coarse signal) 来计算精细部分 (fine part)。根据网络输出激励和线性预测信号,对子频带信号进行预测。然后,运用频带合并运算从子频带的预测信号中重构原始波形信号。
此处讨论的优化使用从一般工作负载到高性能计算 (HPC) 工作负载的几种优化技术。所有优化均使用自定义 WaveRNN 模型来执行。该模型与 FeatherWave 声码器类似,且没有多频带线性预测功能。对于 FeatherWave,我们预计性能也会有类似提升。
优化方法
1. 利用英特尔® AVX-512 技术和 bfloat16 指令
确保 GRU 模块和 Dense 运算符中粗略部分/精细部分的所有 SGEMV 计算都使用 512 位矢量进行矢量化,并采用 bfloat16 点积指令。对于按元素逐个加/乘等运算以及其他非线性激活,都使用最新的英特尔® AVX-512 指令运行。
2. 采用对齐功能优化内存分配器
内存对齐对于充分发挥 AVX-512 指令出色性能来说至关重要。将所有内存分配器都改为使用 `_mm_malloc(size, 64)`,确保工作负载中所使用的内存缓冲区对齐为 64 B。
3. 阻止缓存技术
将 SGEMV 运算(矩阵)的权重重构为特殊的块格式,与纯格式(列优先)相比,空间局部性得到提升。将 SGEMV 运算(矢量)的输入数据平铺以改善时间局部性。
4. 进行运算融合以减少内存访问量
在粗略部分和精细部分进行大量逐元素运算,以更新全部三个 GRU 门状态。融合这类逐元素运算可将大多数数据保存在寄存器或高速缓存中,而不是从 DRAM 加载/存储到 DRAM,从而使性能得到提升。
5. 在使用更多内核扩展模型时平衡稀疏 SGEMV
自定义 WaveRNN 采用的稀疏模型,其质量远胜小型密集模型。当运用更多内核扩展模型时,平衡计算量至关重要。此外,将工作负载尽可能平均地分配到不同的内核也很关键(此优化仅适用于多核环境)。
性能测试结果
以下性能测试结果通过在第三代英特尔® 至强® 可扩展处理器上运行的自定义 WaveRNN 获得。
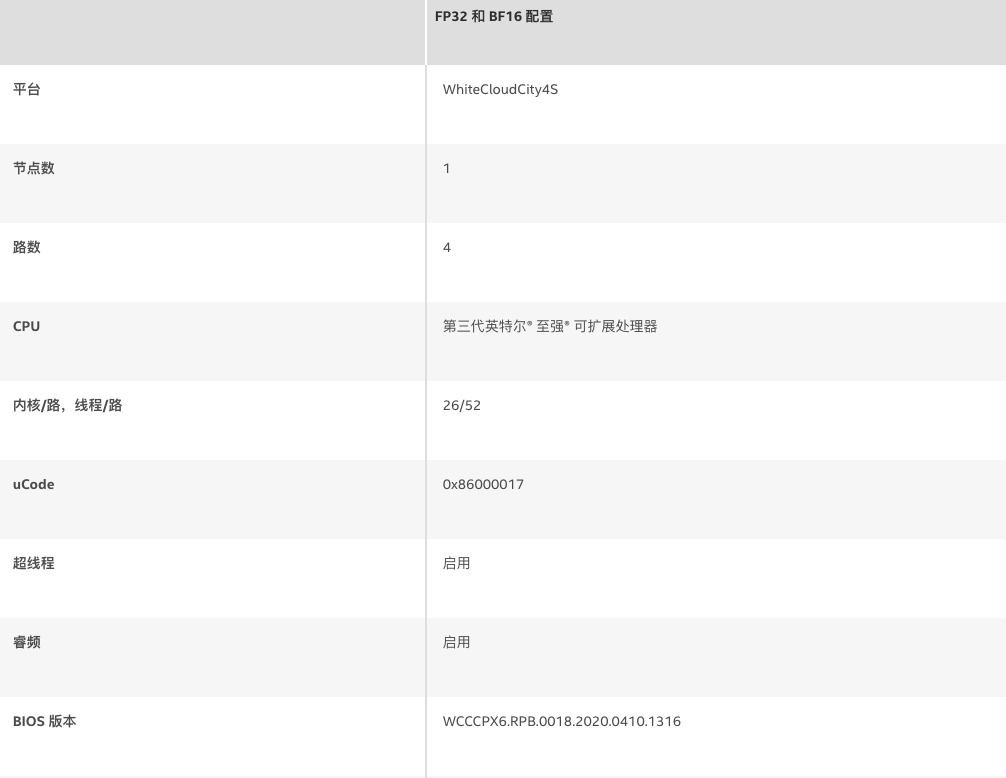
表 1. 硬件配置
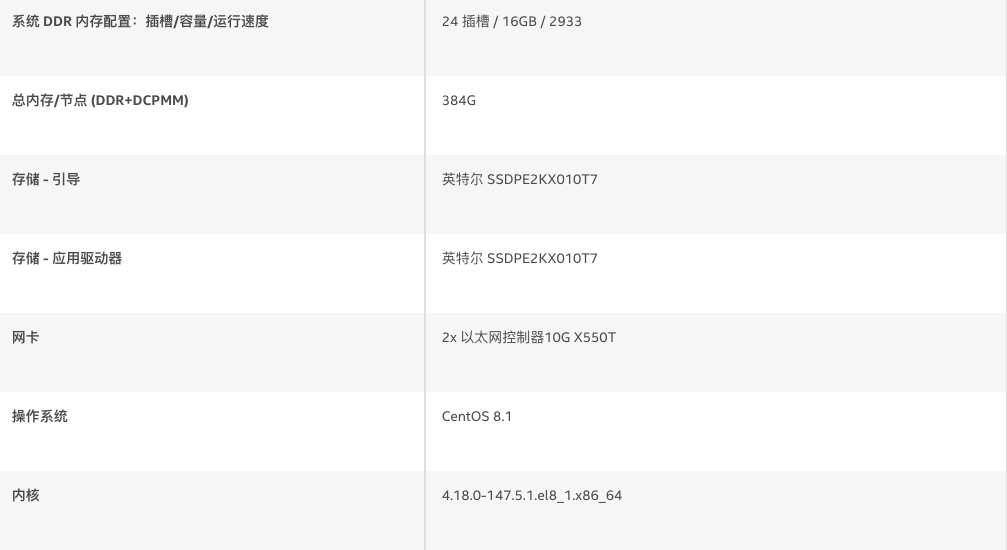
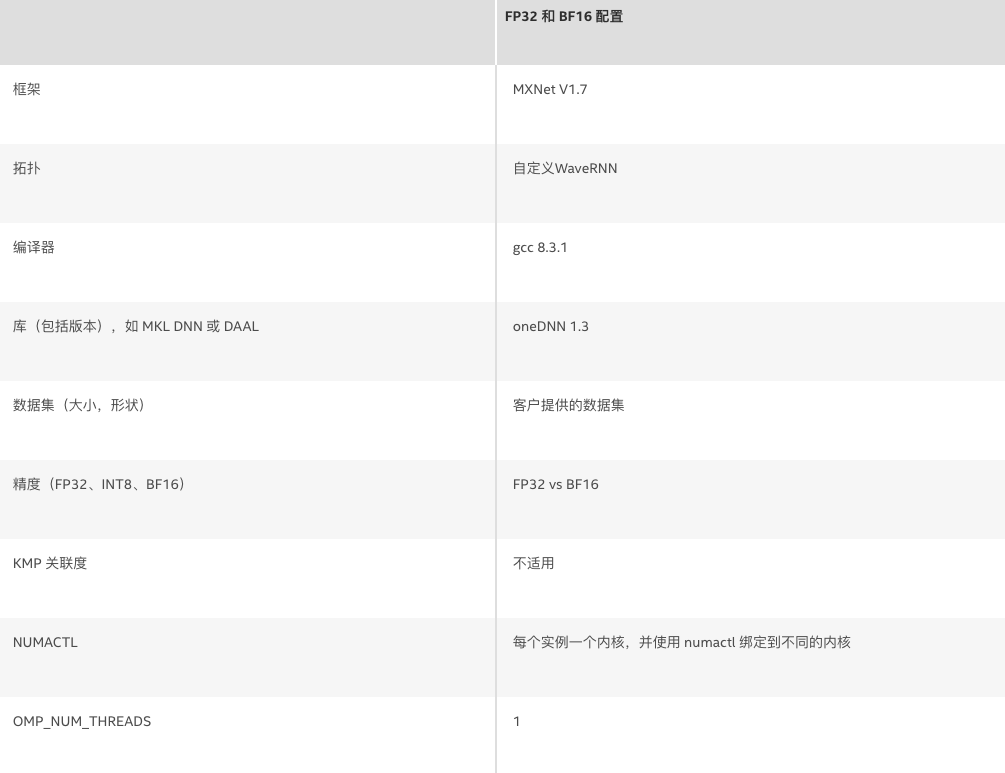
表 2. 软件配置

表 3. 性能测试结果
RT(越高越好)= 语音时间/用于合成语音的时间
PWaveNet
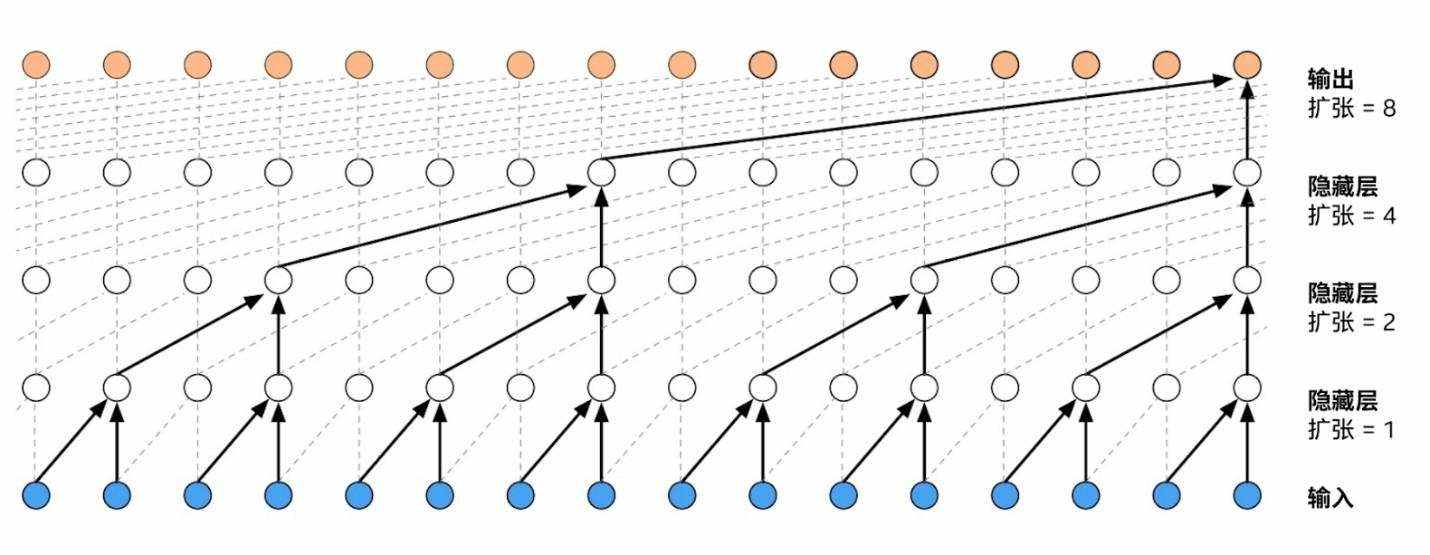
WaveNet 是一系列已成功应用于文本、图像、音乐、视频、手书及人类语音等多元数据的自回归深度生成模型之一。像 WaveNet 这样对原始音频信号进行建模代表着一种非常极端的自回归形式,每秒预测的样本多达 24,000 个。在网络训练期间,由于输入样本的完整序列可用且可以并行处理,因此以如此高的时间分辨率运算并不是个问题。生成样本时,必须先从输出分布中提取每个输入样本,然后才能在下一阶段将其作为输入传递。如此一来,也就无法进行并行处理。
逆自回归流 (IAF) 是 PWaveNet 的一个重要组成部分。IAF 代表深度自回归模型的双重表述,其中可以并行执行采样,而似然估计所需的训练过程则按顺序排列且速度缓慢。腾讯提议将 Parallel WaveNet 与 GAN 相集成[3],以获得更好的语音质量。
优化方法
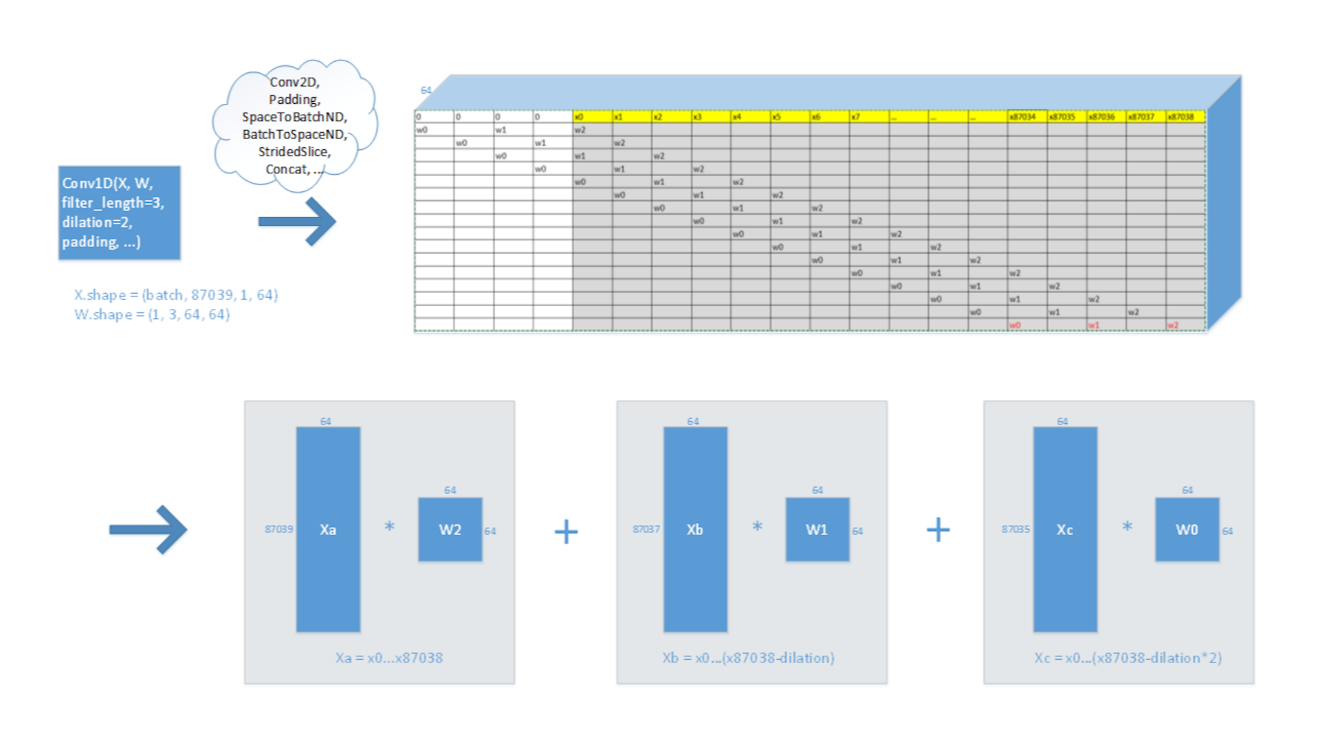
1. 通过扩张将 conv1D 运算转换为多个通用矩阵乘法 (GEMM) 的组合
在模型原始图中,conv1D 由 conv2D、padding、SpaceToBatchND、BatchToSpaceND、StridedSlice、Concat 等组成。某些运算复杂且运行效率低。我们简化了拓扑,将 conv1D 转换为几个 GEMM 的组合。这不仅减少了计算量,而且还降低了内存访问次数,因而可以提高缓存命中率。(由于 conv1D 的输入大小始终在变化,因此我们没有在深度神经网络库 (DNNL)/oneAPI 深度神经网络库 (oneDNN) 中直接使用卷积原语。)
2. 利用英特尔® 深度学习加速技术:AVX-512 指令
在该模型中,某些运算(例如 tanh 和 sigmoid)的时间比例相对较高。我们使用英特尔® AVX-512 指令重新实施这些运算;此优化提高了指令的执行效率,从而显著提升了性能。
3. 利用英特尔® 深度学习加速技术:bfloat16 指令
支持 bfloat16 指令是第三代英特尔® 至强® 可扩展处理器的新特性,可以减少将数字换入和换出内存所需的时间。低精度电路也简单得多。在该模型中,我们将所有卷积的输入数据从 FP32 格式转换为 bfloat16,然后调用 bfloat16 GEMM 进行计算。此优化可显著提升性能。
4. 利用 OpenMP 改善图形流的并行性
在该模型中,某些运算的组成比较复杂,这限制了整个图的并行性。通过 GEMM 函数简化之后,我们将 OpenMP 并行机制导入代码中,以进行其他琐碎运算。这样也可以显著提升性能。
表 4. 性能测试结果
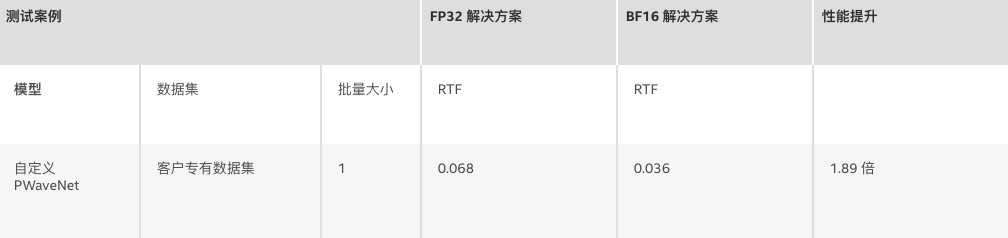
RTF(越低越好)= 用于合成语音的时间/语音时间
对于 WaveRNN 而言,出于高效率考虑,我们可以使用多个实例(每个内核 1 个实例)来实现更高的吞吐量 (RT)。而与 WaveRNN 相比,PWaveNet 则对计算有更高的要求,因此无法使用多个实例。因此,我们将 RTF 用作延迟指标(1 个实例/路)。
总结
总而言之,我们将第三代英特尔® 至强® 可扩展处理器上的多项优化技术应用于腾讯的自定义 WaveRNN 系列神经声码器和 Parallel WaveNet。这些优化技术有助于在平台上实现出色的性能。
参考
[1] DurIAN: Duration Informed Attention Network For Multimodal Synthesis(DurIAN:针对多模态合成的持续时间知悉网络)
[2] FeatherWave: An efficient high-fidelity neural vocoder with multiband linear prediction(FeatherWave:拥有多频带线性预测功能的高效高保真神经声码器)
[3] Generative Adversarial Network based Speaker Adaptation for High Fidelity WaveNet Vocoder(针对高保真 WaveNet 声码器且基于生成对抗网络的说话人自适应技术)
[4] Parallel WaveNet: Fast High-Fidelity Speech Synthesis(Parallel WaveNet:高保真语音快速合成)
一般提示和法律声明
性能测试中使用的软件和工作负荷可能仅在英特尔微处理器上进行了性能优化。
性能测试均系基于特定计算机系统、硬件、软件、操作系统及功能。上述任何要素的变动都有可能导致测试结果的变化。请参考其他信息及性能测试(包括结合其他产品使用时的运行性能)以对目标产品进行全面评估。 更多信息,详见 www.intel.cn/benchmarks。
性能测试结果基于 2020 年 4 月 28 日和 5 月 11 日进行的测试,且可能并未反映所有公开可用的安全更新。没有任何产品或组件是绝对安全的。
有关英特尔软件产品中性能和优化选择的更多信息,请参阅 https://software.intel.com/content/www/cn/zh/develop/articles/optimization-notice.html。
您的成本和结果可能会有所不同。
英特尔技术可能需要支持的硬件、软件或服务得以激活。
© 英特尔公司版权所有。英特尔、英特尔标识以及其他英特尔商标是英特尔公司或其子公司在美国和/或其他国家的商标。 其他的名称和品牌可能是其他所有者的资产。






行业专家共同推荐的软件
亿企代账
- 4.3
(3)咨询产品免费试用捷税宝
- 4.5
(14)咨询产品免费试用云代账
- 3.8
(6)咨询产品免费试用



限时免费的代理记账软件
小微律政
- 3.8
(6)咨询产品免费试用花生账
- 4.2
(9)咨询产品免费试用易代账
- 3.8
(4)咨询产品免费试用



新锐产品推荐
Flashdevelop
- 3.9
(40)咨询产品免费试用Basic4android (B4A)
- 0.0
(0)咨询产品免费试用PyCharm
- 4.0
(40)咨询产品免费试用CodeSandbox
- 0.0
(0)咨询产品免费试用JCppEdit
- 0.0
(0)咨询产品免费试用CodeinCloud
- 0.0
(0)咨询产品免费试用







