能“看穿”换脸视频背后的AI模型,Facebook的反Deepfake方法有点东西
本文来自微信公众号“量子位”(ID:QbitAI),作者:水木番,36氪经授权发布。
Deepfake是一款非常火的AI换脸工具,可以将专业复杂的AI换脸过程简单化,实现快速换脸,制作的内容甚至可以以假乱真。

但是,现在的技术不仅可以判断照片是否假冒伪劣,还可以跟踪所有背后的信息,你信吗?
这不,最近Facebook 和密歇根州立大学的研究团队合作,提出了一种可对Deepfake 伪造的图片采取逆向工程的研究方法:
通过对模型生成的图片进行逆向工程,分析出模型的超参数,估计出网络架构和训练损失函数!
这些参数和模型是一一对应的,可以直接反映出用什么模型方法生成的图片。

对于这项“逆向工程”的研究,Facebook的研究负责人Tal Hassner说:
识别未知模型的特征非常重要,因为Deepfake软件加入未知的图片非常容易。当调查人员试图追踪时,坏人可能会想办法掩盖他们的踪迹。
而如果我们发现不同地方上传的图片,都来自同一个模型,我们就可以找到生成这些内容的电脑,并判断其就是罪魁祸首。
因此,Facebook 的这项新技术简直是社交打假的福音啊!

让我们来看看它的原理是什么?
Deepfake的逆向工程
现在已经能够分辨一张图片是Deepfake合成的脸,还是真实的脸。
但这远远不够,社交网络中肯定还需要判断图片的归属,以及生成图片背后的信息。
Facebook提出用逆向工程处理Deepfake问题,但它并不是机器学习中的一个新概念。
之前的逆向工程机器学习模型类似黑盒测试,就是通过检查其输入和输出来得到模型。
这种方法往往依赖于模型本身已有的知识,但现实世界中往往缺乏已有的知识,所以实用性不高。
研究团队采用的逆向工程方法,主要依赖的是:
用于生成Deepfake图片的模型背后的架构特征。
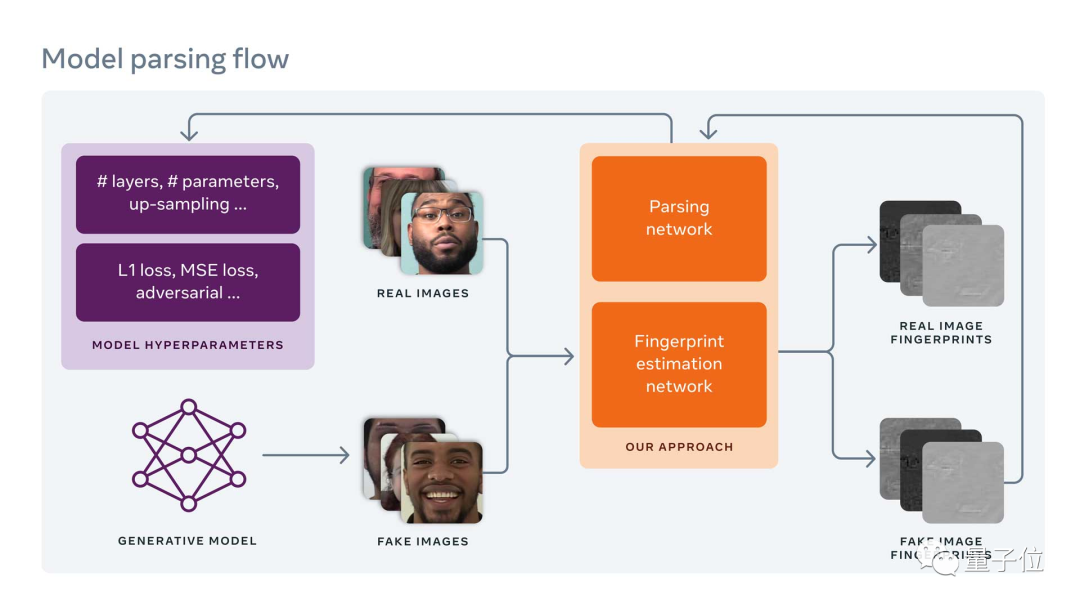
这些特征被称为超参数,密歇根州立大学 Vishal Asnani 的团队确定了这些超参数,并设计了一种“指纹估计网络”和“模型解析”的流程化方法对其进行深入分析。

“指纹估计网络”和“模型解析”
对生成模型的图片进行逆向工程,应该从哪里入手呢?
答案是可以从“指纹”入手,它是图片在处理过程中留下的信息。
正是因为Deepfake处理过的内容,会在图片上留下一个独特的“指纹”,所以可以凭借这些“指纹”信息进行逆向工程,分析出其独特的网络架构和损失函数,追踪其来源。
具体来说,研究团队首先通过一个指纹估计网络(FEN)来检测Deepfake的图片。
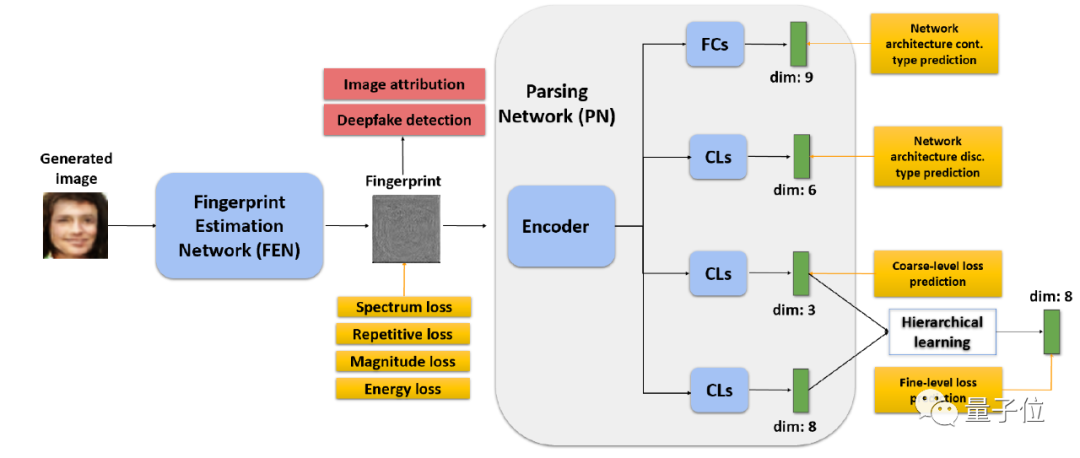
为了缩小工作范围,研究团队将“指纹”的特性(包括大小、重复性、频率范围和频率响应)作为开发约束条件的基础,进行无监督训练。
一旦“指纹”生成,就可以作为模型解析的输入。
然后,研究人员设计了一种模型解析网络的方法,既分析了用于创建Deepfake的模型的网络架构,也估计了训练的损失函数。
研究团队对网络架构中的一些连续参数进行了归一化处理,以方便训练,还对损失函数类型进行了分类,进行了分层学习。
由于生成模型在网络架构和训练的损失函数方面各不相同,因此从Deepfake得到超参数的过程,可以让它对应的模型的各类特征“无处遁形”,这也是逆向工程在这类应用中的神奇之处。
下面来看看它的网络架构和损失函数是怎么预测出来的。
网络架构预测
这项研究的主要难点在于预测网架构,因为深度网络一般有几百万个网络参数,所以很难预测。
但是网络架构的超参数比网络参数要少得多,估计起来相对容易。
在实际操作过程中,将超参数分为连续和离散两种:
对连续参数采用回归参数估计,由于参数有不同的范围,需要最小最大实现归一化。
由于离散参数是不平衡的,因此对每个参数会采用加权交叉熵处理。
损失函数预测
除了网络架构以外,生成模型的学习网络参数也可以影响图片上的“指纹”,这些网络参数由训练数据和模型的损失函数决定。
所以,研究人员分析了从“指纹”预测损失函数的可能性。
为了避免复杂,研究人员将损失函数分为像素损失,鉴别损失和分类损失。
如图所示,在这种分类基础上,可以进一步用分层学习预测损失函数,每个损失可以通过相应因子的乘积求得。
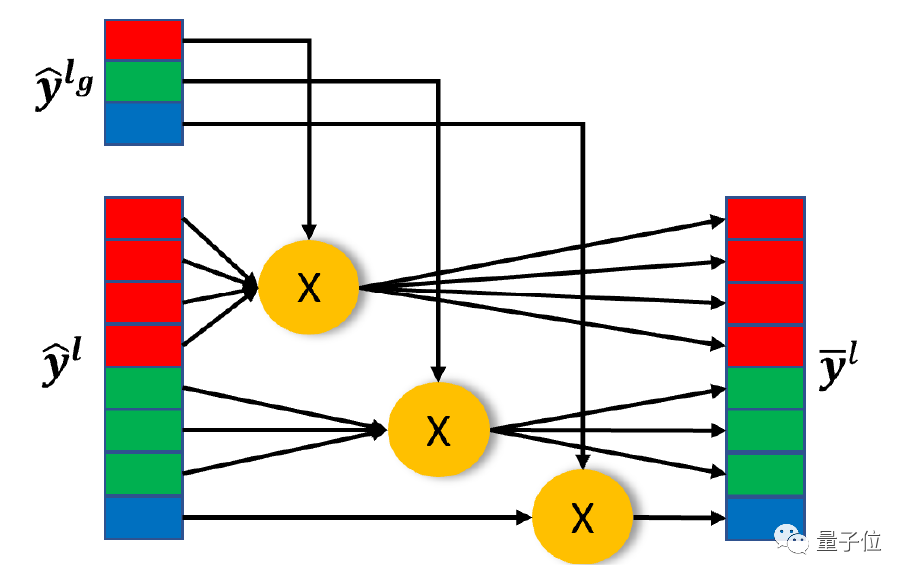
最终,整体的损失函数可以用各类损失函数的总和计算求得。
其他应用
除了模型解析,“指纹”估计网络还可用于Deepfake检测和图片归因:
研究团队设置了一个浅层网络,针对输入估计的“指纹”进行二进制简化,来实现Deepfake检测,并通过类别划分来实现图片归属的分析。
虽然“指纹估计方法”的初衷并不是主要针对这两项任务,但研究团队在这两项任务上也取得了相当好的结果。
效果怎么样?
让我们来看看逆向工程的实际效果。
估计网络架构和损失函数的标准交叉熵和加权交叉熵如下图,其中每种情况的各个参数可以用相似矩阵来表示。
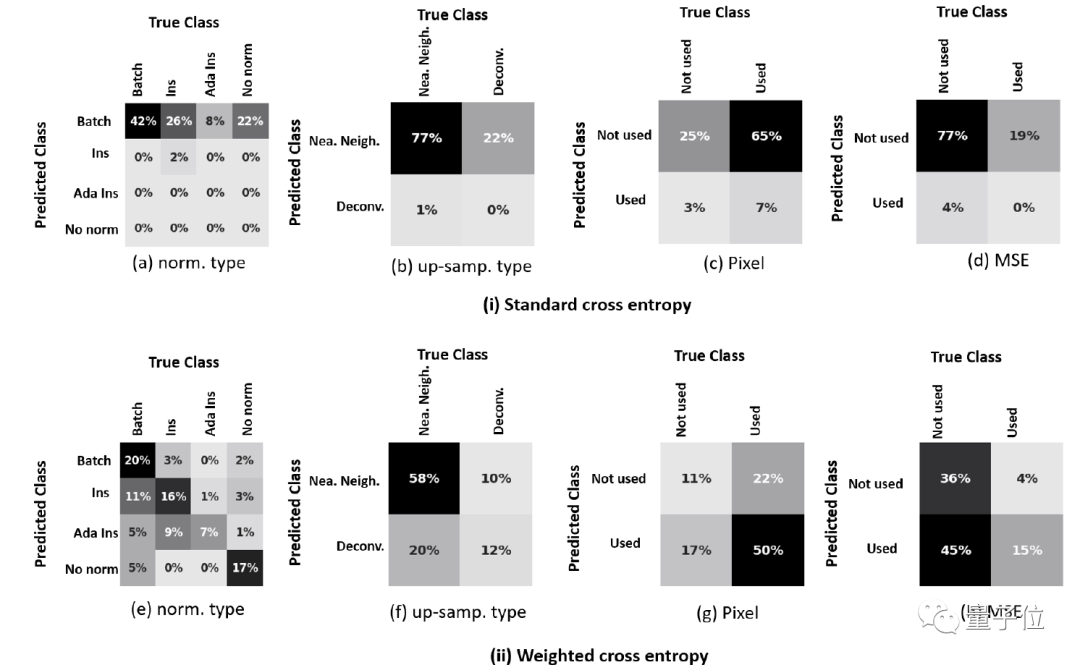
实际结果中,加权交叉熵可以处理数据中的不平衡,效果比标准交叉熵要好。
在给定多个图片时,可以分析出相应的网络架构和损失函数,如下表所示。
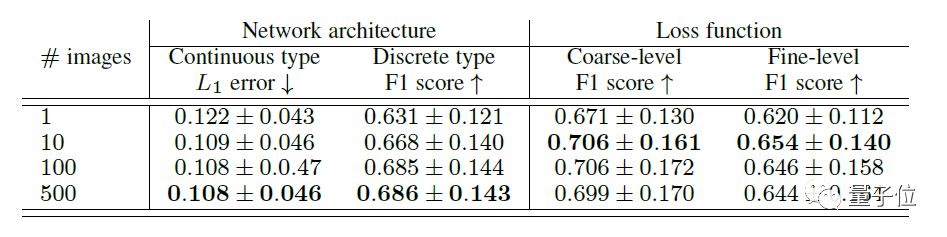
有趣的是:
当要评估的图片数从1增加到10时,性能的增加非常明显。当图片在10个以上的时候,性能会变得趋向于稳定。
最终,研究团队选取了一个由 100 个不同的生成模型生成的 100,000 张Deepfake图片的数据库,每个模型生成了 1000 张图片。
其中部分图片用于训练模型,而其他图片则被保存,并作为来源不明的图片呈现给模型。
由于是第一次进行模型解析,没有现有的基线可供比较。
因此,研究团队通过随机设定ground-truth集合中的每个超参数,形成了一个称为随机ground-truth的基线。

结果表明,研究团队方法训练出的数据的性能明显优于随机ground-truth基线。
此外,实验中有来自100个生成模型的Deepfake图片集合,说明模型的选择具有代表性。
这也意味着在这种逆向工程的方法在人类和非人类的图片表现中都有很好的泛化能力。
研究人员:猫鼠游戏的本质不会改变
Hassner 将这项工作与法医技术(forensic techniques)进行了类别,该技术通过寻找所产生的图像中的模式,来确定照片是哪种型号的相机来拍摄的。
但他表示:
尽管不是每个人都能制作自己的相机,但是任何有计算机相关经验的人都可以制作他们自己的模型,生成Deepfake图像。
看来还真是个问题,那现在的检测技术发展得怎么样呢?
在Facebook去年举办的Deepfake检测比赛上,最后获胜的算法也只能实现对Deepfake软件 65.18% 的成功检测。
此外,每天都有新的AI技术出来,目前也没有任何检测系统可以同步得那么快。

因此,检测Deepfake这类生成模型制作的照片目前仍然是一个“未解决的问题”。
面对这种动态变化,Hassner说:
本质上,这是一个猫和老鼠的游戏,它将会一直继续下去。

是啊,技术的攻与防的游戏永远不会停止,伪造和检测的博弈也只会越来越好玩。
让我们继续关注,看看这一出人工智能的好戏还会有什么新进展。
链接:
[1]https://www.theverge.com/2021/6/16/22534690/facebook-deepfake-detection-reverse-engineer-ai-model-hyperparameters?scrolla=5eb6d68b7fedc32c19ef33b4
[2]https://ai.facebook.com/blog/reverse-engineering-generative-model-from-a-single-deepfake-image/
[3]https://github.com/vishal3477/Reverse_Engineering_GMs[4]https://arxiv.org/abs/2106.07873





大厂都在用的代理记账软件
亿企代账
- 4.3
(3)咨询产品免费试用捷税宝
- 4.5
(14)咨询产品免费试用云代账
- 3.8
(6)咨询产品免费试用



限时免费的代理记账软件
小微律政
- 3.8
(6)咨询产品免费试用花生账
- 4.2
(9)咨询产品免费试用易代账
- 3.8
(4)咨询产品免费试用



最新文章推荐
新锐产品推荐
法大大
- 3.9
(319)咨询产品免费试用石墨文档
- 4.0
(89)咨询产品免费试用Teambition
- 3.7
(90)咨询产品免费试用有赞
- 3.9
(163)咨询产品免费试用微盟微商城
- 3.8
(36)咨询产品免费试用闪闪
- 0.0
(0)咨询产品免费试用







