谷歌推出录音程序Recorder,智能处理海量音频信息
编者按:本文来自微信公众号“将门创投”(ID:thejiangmen),36氪经授权发布。
对于冗长的会议、复杂的课程、高强度的采访来说,记笔记很多时候已经无法满足海量涌来的信息了,用录音笔或者手机录音成为记录信息的常用方式。但要从几个小时的录音中寻找到关键的信息却让人十分抓狂。如果我们能够拥有一个智能录音机,可以实时转录并标记长时间的录音内容,帮助我们像搜索文本图像一样迅速定位找到相关信息,那该多好!
为了解决这一问题,让人们更为便捷地检索录音中感兴趣的信息,谷歌为Pixel开发了一个名为Recorder的应用,将移动端机器学习的最新进展应用于对声音、对话的记录和转写、检测和识别特定类型的音频(包括语音、音乐、掌声、口哨、音乐等等)并为录音信息编制了有效的索引,从而帮助用户可以快速地寻找到感兴趣的录音片段。值得一提的是,所有这些都可以在设备端离线运行,无需网络和云服务的支持。
音频转录
这一app的背后是一个高性能的移动端语音识别模型,它可以有效可靠地对长达几个小时的录音进行撰写,同时在撰写的过程中还可以将单词映射到时间戳上建立有效的索引。
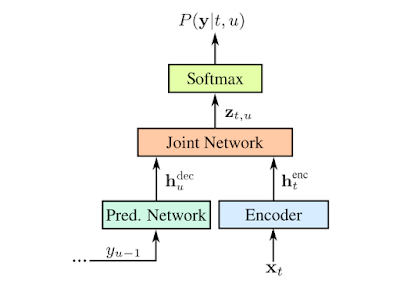
支持实时语音转写的RNN-T模型
这样用户就可以在单击撰写结果的一个单词时跳转到录音中对应的时刻开始播放,也可以通过对特定词语的搜索直接跳转到录音中对应的时间点,使得录音也变得智能化、可以方便地检索。
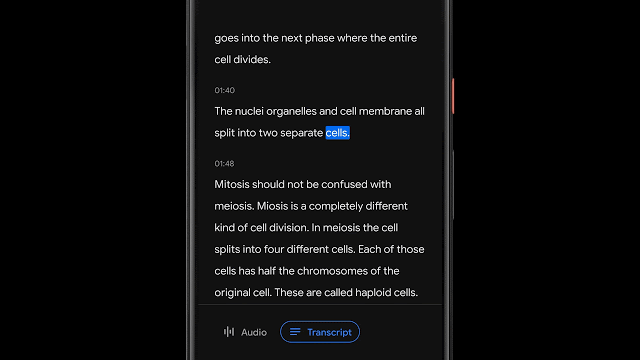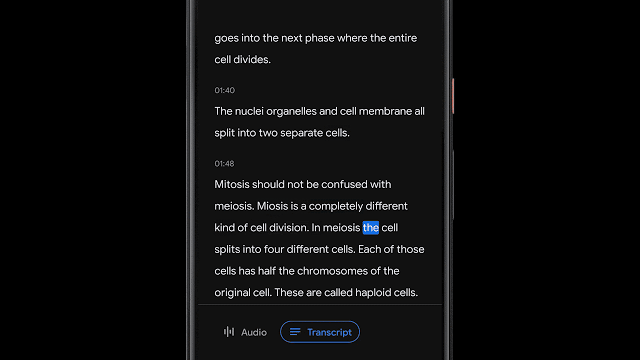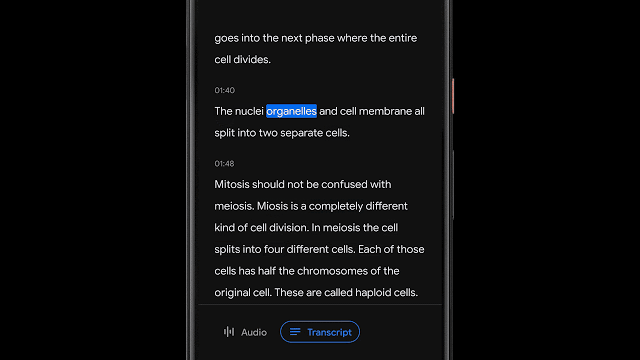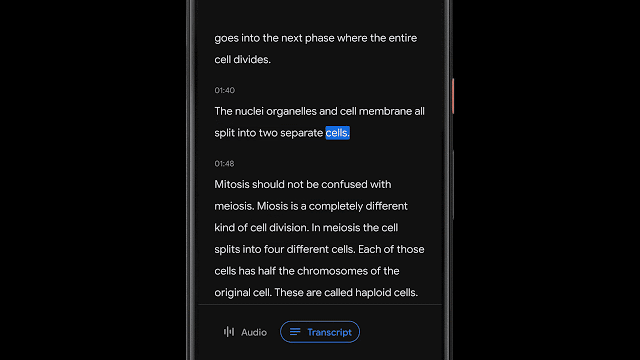
基于音频分类的录音内容可视化
除了可以支持特定单词的检索,很多时候能够可视化地快速搜索音频中特定类型的内容更为有用。在Recorder中为音频中不同类型内容的波形添加了不同的颜色,而这主要是通过基于CNN的音频分类模型来实现的。

用于训练CNN音频分类模型的数据集
虽然很多时候周围存在着嘈杂的多种声音,但Recorder中会根据某一时间段内(50ms)最主要的声音来为音频添加上对应分类的颜色标签。基于色彩的粗粒度视觉检索方式可以让用户直观地了解录音中的声音类型的分布比例,同时也为相关信息的检索提供了便利。
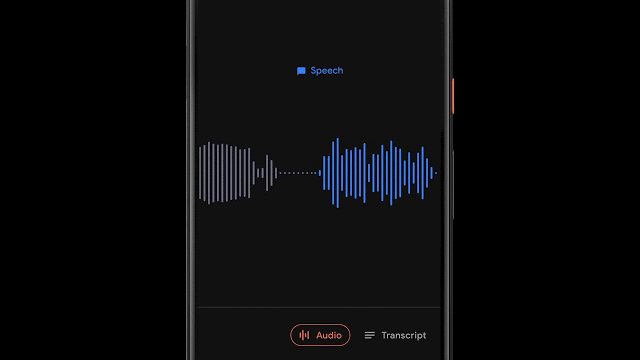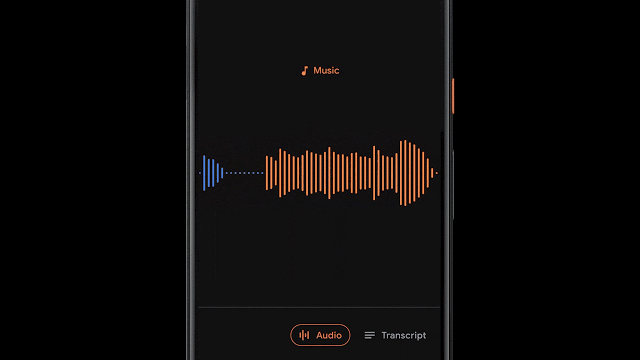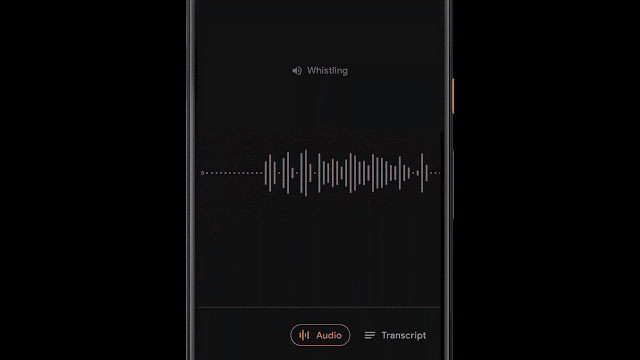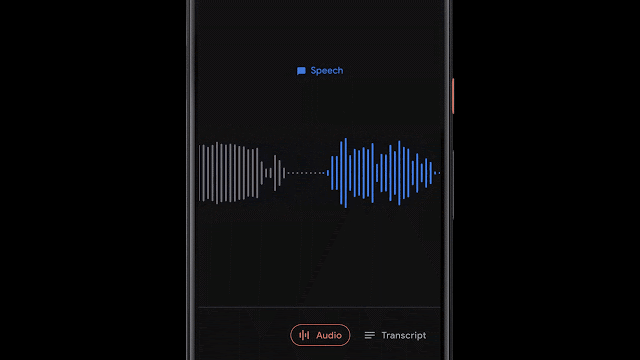
为了实现这一功能,录音软件利用滑动窗口的方法来对960ms长度的录音进行处理,每隔50ms的间隔输出一个表示对应声音类别的概率。此外研究人员还利用线性化与阈值等机制对概率得分进行处理,得到了更为精确的内容分类结果。
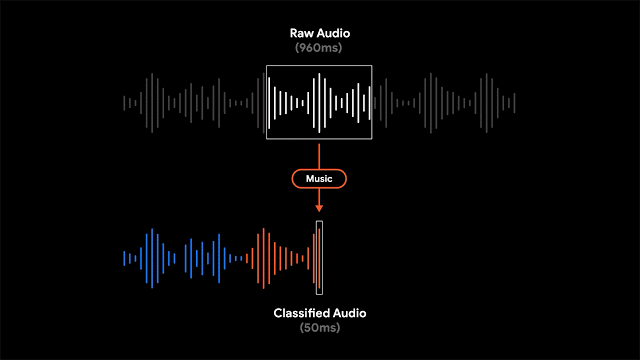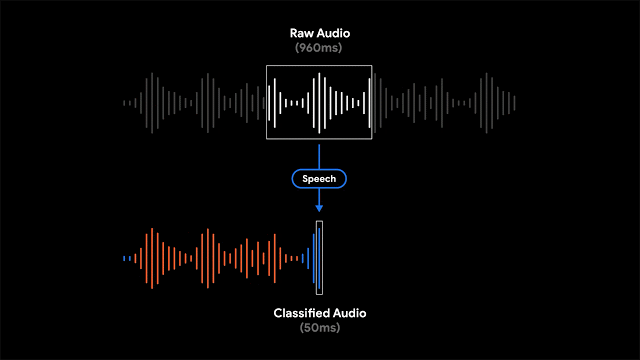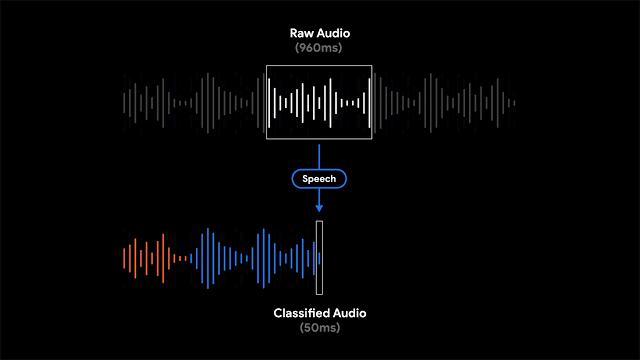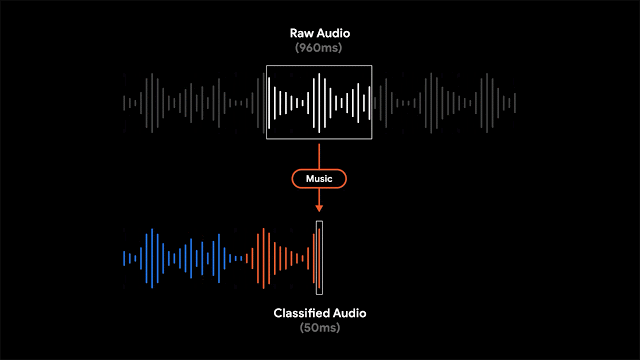
由于模型对于每个音频帧进行独立地分析,从而可以适应音频帧间不同类型的快速变化。通过自适应尺寸的中值滤波器技术对分类结果进行处理,就能得到平滑且连续的输出。同时模型和前后处理也满足高效的能耗要求,以便适应移动端严格的功耗限制。
自动标签建议
录音结束后,程序还能够根据内容自动生成三个最具代表性的标签,帮助用户快速构建文件标题。
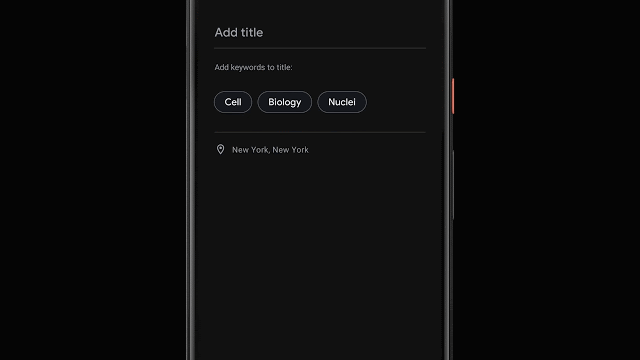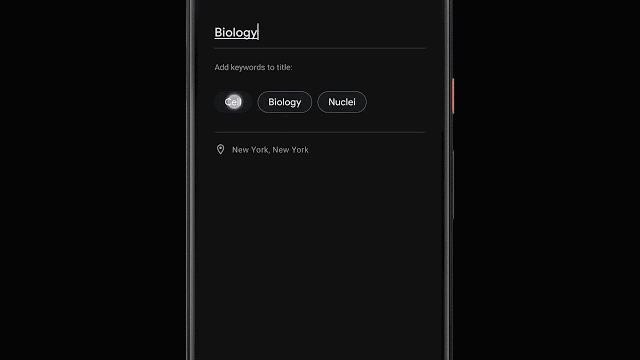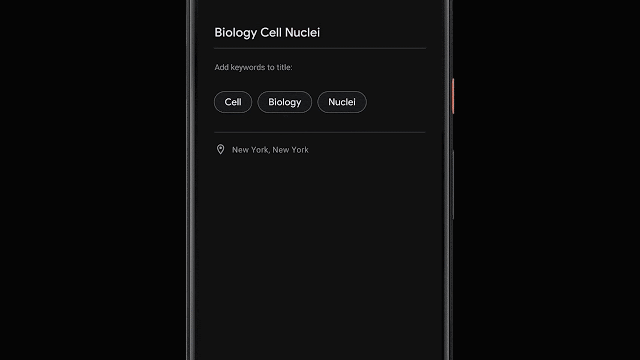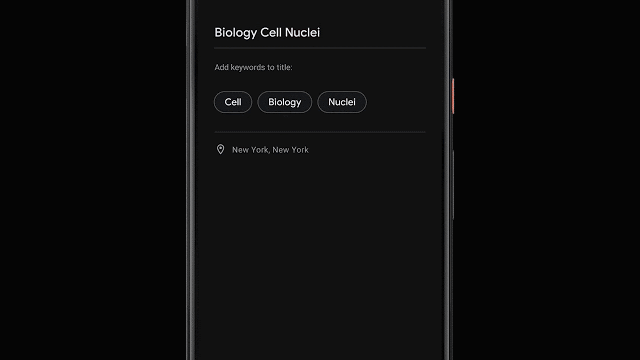
为了能够在转写结束就生成标签建议,程序在转录过程中就会对单词数量、重要性进行分析;同时也会将识别出的专有名词转为大写。然后使用设备端的词性标注器来根据语法标注每一个词的词性,检测出用户更容易理解和记忆的词。最后利用决策树的方式生成词语等分,并输出排名靠前的词语作为标签。
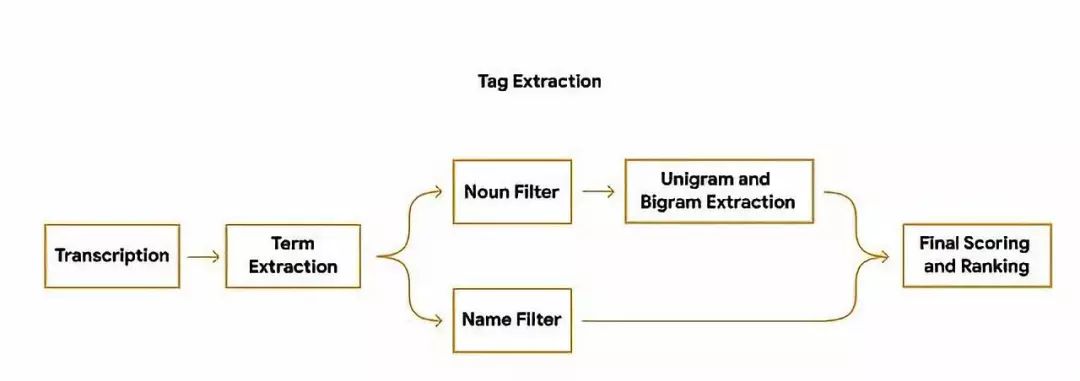
录音建议标签抽取流程
小程序大身手
虽然只是一款小小的录音机程序,但其中集成了很多机器学习技术,特别是要在设备端离线准确运行如此长时间的语音识别模型是十分不易的。设备端的运行不仅提高了用户使用的体验,同时也保护了用户隐私不受侵犯。通过对于需求的挖掘和机器学习技术的充分利用,小小的录音机也能成为人们高效工作的大帮手!从内容到图像,从视频到声音,让一切信息变得更容易搜索和触达,期待谷歌未来能够推出更好的服务。
From:Google,编译:T.R
ref:




行业专家共同推荐的软件
意派Epub360
- 4.1
(5)咨询产品免费试用易海报
- 4.0
(5)咨询产品免费试用百度H5
- 3.7
(8)咨询产品免费试用



限时免费的H5制作软件
秀多多
- 3.9
(5)咨询产品免费试用兔展
- 3.9
(5)咨询产品免费试用凡科微传单
- 4.0
(3)咨询产品免费试用



新锐产品推荐
国双营销云
- 2.5
(1)咨询产品免费试用睿帆科技Baymax
- 0.0
(0)咨询产品免费试用智赢ERP
- 0.0
(0)咨询产品免费试用熵简科技
- 0.0
(0)咨询产品免费试用奇点云-DataNuza
- 0.0
(0)咨询产品免费试用优易ERP
- 0.0
(0)咨询产品免费试用







